por Olivia Díaz | Apr 11, 2024 | Control Remoto
Todo ordenador tiene su BIOS, abreviación de Basic Input/Output System o sistema básico de entrada/salida), el cual es un firmware instalado en la placa base de la PC. Mediante BIOS se puede inicializar y configurar los componentes de hardware (CPU, RAM, disco duro, etc.). Digamos que es una especie de traductor o puente entre el hardware y el software del ordenador. Sus funciones principales son:
- Inicializar el hardware.
- Detectar y cargar el gestor de arranque y del sistema operativo.
- Configurar varios parámetros de tu PC como secuencia de arranque, hora y fecha, tiempos de RAM y voltaje de CPU.
- Establecer mecanismos de seguridad como una contraseña para restringir el acceso a tu PC.
Importancia de entender cómo acceder al BIOS y su actualización
Partiendo de que su función principal es inicializar y comprobar que todos los componentes de hardware de tu PC estén funcionando correctamente, si todo funciona correctamente, BIOS busca el sistema operativo en el disco duro u otro dispositivo de arranque conectado a tu PC. Sin embargo, acceder a BIOS puede ser un proceso desconocido para muchos usuarios, impidiendo su actualización que pueda garantizar el desempeño del equipo y su seguridad. Más adelante, en este blog explicaremos cómo acceder a BIOS.
Aclaración sobre la naturaleza no rutinaria de las actualizaciones del BIOS
Se recomienda actualizar BIOS para mantener el rendimiento, la estabilidad y seguridad del ordenador. El fabricante de tu PC puede enviar actualizaciones del BIOS para añadir funciones o corregir algunos errores. El proceso es generalmente sencillo, pero debe hacerse con sumo cuidado para evitar daños irreversibles. También, debe evitarse apagar o cortar la corriente en medio de un proceso de actualización con graves consecuencias para el equipo.
Acceso al BIOS desde Windows
Para acceder a BIOS, hay varias opciones, desde los siguientes botones, dependiendo de la marca de tu equipo:
- Dell: F2 o F12
- HP: F10
- Lenovo: F2, Fn + F2, F1, o Enter seguido de F1
- Asus: F9, F10 o Supr
- Acer: F2 o Supr
- Microsoft Surface: Mantener pulsado el botón de subir el volumen
- Samsung/Toshiba/Intel/ASRock/Origin PC: F2
- MSI/Gigabyte/EVGA/Zotac/BIOStar: Supr

Instrucciones para acceder al BIOS desde Windows 10 o 11 a través de la Configuración y la opción de Inicio Avanzado
Solo hay que seguir estas instrucciones:
- Reinicia tu ordenador y espera a que aparezca el logotipo del fabricante.
- Presiona una de las teclas que antes mencionamos al momento de ver la pantalla de inicio para poder acceder a la configuración del BIOS.
- Ya estando en el BIOS, puedes navegar por las diferentes opciones usando las teclas de flecha en tu teclado.
También puedes seguir este proceso en Windows 11:
- En la pantalla de inicio de sesión o de bloqueo, pulsa la tecla Shift en el teclado y toca el botón de encendido (o haz clic en la opción de encendido en la parte inferior derecha de la pantalla de inicio de sesión). A continuación, elige la opción Reiniciar en el menú.
- Cuando Windows 11 se reinicie, se te mostrará la pantalla de inicio avanzado (elige una opción).
- A continuación, desplázate a Solucionar problemas > Opciones avanzadas > Configuración del firmware UEFI y pulsa Reiniciar.
Dado que la configuración BIOS puede tener un impacto en el funcionamiento de tu PC, se recomienda buscar ayuda de un profesional.
Alternativas de utilizar el método de Windows 10 y 11 si el sistema operativo se carga demasiado rápido para acceder al BIOS
Una alternativa para iniciar la configuración del BIOS de Win11 es desde la aplicación de Configuración. Para ello, debes seguir estos pasos:
- Abre Configuración de Windows 11.
- Navega hasta Sistema > Recuperación > Reiniciar ahora.
- Antes de dar clic en Reiniciar ahora, debes guardar tu trabajo.
- A continuación, ve a Solución de problemas > Opciones avanzadas > Configuración del firmware UEFI y pulsa Reiniciar
(de UEFI hablaremos más adelante en este artículo).
Otra alternativa es usar el comando Ejecutar de Windows:
- Abre el cuadro de Ejecutar (pulsando las teclas Windows + R).
- Luego teclea /r /o, y pulsa Enter. Un atajo es escribir shutdown /r /o /f /t 00 y hacer clic en Aceptar.
- A continuación, selecciona Solucionar problemas > Opciones avanzadas > Configuración del firmware UEFI y pulsa Reiniciar para arrancar en la configuración del BIOS del sistema.
Por la línea de comando, también:
- Abre CMD, PowerShell o Terminal.
- Escribe shutdown /r /o /f /t 00 o shutdown /r /o y pulsa Enter.
- A continuación, accede a Solución de problemas > Opciones avanzadas > Configuración del firmware UEFI y pulsa Reiniciar para llegar a la configuración del BIOS/UEFI de Windows 11
Una opción más personalizada es por acceso directo:
- Haz clic con el botón derecho del ratón en el escritorio de Windows 11 y selecciona Nuevo > Acceso directo.
- En la ventana Crear acceso directo, introduce shutdown /r /o /f /t 00 o shutdown /r /o para ubicarlo.
- Sigue las instrucciones para crear un acceso directo a BIOS.
Una vez creado el acceso directo a la configuración del BIOS, sólo hay que hacer doble clic en él y elegir Solución de problemas > Opciones avanzadas > Configuración del firmware UEFI y pulsar Reiniciar para arrancar tu PC en el entorno del BIOS.
¿Qué significa UEFI?
UEFI (Unified Extensible Firmware Interface) o Interfaz de Firmware Extensible Unificada ha surgido como firmware más moderno y flexible con nuevas funciones que van más de la mano con las necesidades actuales de más volumen y más velocidad. UEFI soporta discos duros de mayor tamaño y tiempos de arranque más rápidos.
Ventajas de UEFI:
- Fácil de programar, ya que usa el lenguaje de programación C. Con este lenguaje de programación se pueden inicializar varios dispositivos a la vez y tener tiempos de arranque mucho más rápidos.
- Más seguridad, basado en el modo Secure Boot.
- Más rápido, ya que puede ejecutarse en modo de 32 o 64 bits y tiene más espacio de direcciones direccionables que BIOS, resultando en un proceso de arranque más rápido.
- Facilita el soporte remoto. Permite el arranque a través de la red, además puede portar diferentes interfaces en un mismo firmware. También se puede acceder de forma remota a una PC que no puede iniciarse en el sistema operativo para solucionar problemas y realizar tareas de mantenimiento.
- Arranque seguro, ya que puede verificar la validez del sistema operativo para prevenir o comprobar si algún malware manipuló el proceso de arranque.
- Más funciones y capacidad de agregar programas. También puede asociar controladores (ya no se tendría que cargarlos en el sistema operativo), lo cual es una ventaja importante en agilidad.
- Modular, ya que se puede hacer modificaciones por partes sin afectar a lo demás.
- Independencia del microcódigo de CPU.
- Soporte a unidades de almacenamiento de mayor tamaño, con hasta 128 particiones.
Adicionalmente, UEFI puede emular a BIOS antiguas en el caso de necesitar instalar en sistemas operativos antiguos.
Continuación del uso del término “BIOS” para referirse a UEFI por simplicidad
BIOS sigue siendo usado para inicializar y comprobar los componentes de hardware de un ordenador para garantizar su correcto funcionamiento. También, como hemos visto, permite personalizar el comportamiento de PC (qué arranca primero, por ejemplo). Así que BIOS sigue siendo de ayuda para resolver problemas que impiden que la PC arranque correctamente.
¿Cuándo deberías actualizar tu BIOS?
Razones para realizar una actualización del BIOS
La actualización del BIOS (o UEFI), como hemos mencionado antes, ayuda a que el sistema funcione con un mejor desempeño, además de estar comprobando y ajustando el hardware instalado, lo que a su vez impacta finalmente en el funcionamiento del software. Se recomienda actualizar BIOS solo si en la nueva versión existe una mejora necesaria.
A veces, sí es necesario actualizar BIOS para que la placa base admita el uso de un procesador de nueva generación u otro tipo de hardware.
Advertencia sobre los riesgos potenciales de una actualización del BIOS
La recomendación actualizar BIOS solo cuando es necesario parte de la posibilidad de que el proceso de actualización falle, dejando inoperable tu computadora (¡!). Otro riesgo es la pérdida de datos si algo falla durante la actualización (un corte de conexión, energía, proceso incompleto). Considera que puede haber errores inesperados que puedan resultar en un impacto directo en el funcionamiento de tu ordenador. Por eso se recomienda pedir apoyo profesional para hacerlo.
Cómo Actualizar tu BIOS
Aunque cada fabricante recomienda un proceso y sus propias herramientas para actualizar BIOS, podemos decir que el primer paso es siempre hacer una copia de seguridad de los datos más críticos en tu equipo, por si algo sale mal en el proceso (¡esperemos que no!). Para hacerlo, se recomienda lo siguiente:
Identificación del modelo de placa base y del BIOS mediante la información del sistema de Windows
La actualización del BIOS toma como referencia los datos del modelo de la placa base o del equipo. Para saberlo, pulsa la tecla Windows de tu PC y escribe Información del sistema. Se abrirá la ventana del servicio en el que se listarán todos los detalles del software instalado. Verás el Modelo del Sistema y Versión y Fecha del BIOS, para obtener el nombre del fabricante del BIOS, la versión del BIOS y su fecha de publicación. Con estos datos sabrás qué versión del BIOS descargar (debe ser posterior a la que tienes instalada).
Ahora bien, el método más común para actualizar BIOS es mediante un programa asistente de actualización, que te lleva de la mano a lo largo del proceso de actualización y se ejecuta desde el sistema operativo. Solo se debe indicar dónde se halla el archivo de actualización del BIOS y reiniciar el PC.
Pasos para descargar e instalar la actualización del BIOS según las instrucciones del fabricante
Generalmente, el fabricante de la placa base de tu PC cuenta no solo con un programa de asistente de actualización sino también con el archivo de actualización del BIOS, como el propio programa asistente, que puedes descargar desde la página de soporte del fabricante de tu equipo o placa base.
Una vez obtenido el programa asistente de instalación del BIOS y la última versión del BIOS, descárgalos en tu equipo. Es importante mencionar que no se recomienda usar versiones Beta de las actualizaciones del BIOS. Es preferible quedarte con la última versión estable, aunque sea más antigua.
Deja que el asistente de actualización te lleve de la mano y utiliza el archivo de actualización del BIOS para indicar que ése es el nuevo firmware que se va a instalar. En caso de que el archivo de actualización descargado no sea válido o más actualizado a lo que ya tienes instalado, el software del asistente lo detectará y no realizará la actualización.
Una vez concluido esto, reinicia tu PC. Te recomendamos que verifiques la configuración principal, revisando que la fecha y la hora sean correctas, el orden de arranque sea correcto (i.e. qué disco duro se verifica primero para una instalación de Windows) y revisa de que todo lo demás sea correcto.
Ahora sí, puedes continuar trabajando con la nueva versión del BIOS.
Consideraciones sobre las Actualizaciones del BIOS
Antes de realizar alguna actualización del BIOS, siempre se recomienda hacer una copia de seguridad de los datos para que esto no se convierta en tu pesadilla. Para la actualización del BIOS, ten en cuenta estas consideraciones:
- La actualización del BIOS generalmente no mejora el rendimiento, por lo que debe realizarse sólo si es necesario.
- Como hemos visto, existen varios métodos de actualización del BIOS, cada vez más intuitivos como aquéllos en que el propio fabricante ofrece un programa asistente de actualización que te lleva de la mano a lo largo del proceso. Es importante seguir las instrucciones que el fabricante de tu equipo señala para evitar que quede inutilizado.
- Siempre hay que investigar opciones de recuperación en caso de corrupción del BIOS y tener esa información a mano. Es decir: prepárate para cualquier contingencia. Muchas veces, a pesar de medidas de precaución, puede fallar la actualización, ya sea debido a problemas de incompatibilidad o a un desafortunado apagón o caída de la tensión eléctrica. Si esto llegase a pasar, y si aún funciona el PC, no apagues el equipo. Cierra la herramienta de actualización flash y reinicia el proceso de actualización para ver si funciona. Si realizaste una copia de seguridad del BIOS, intenta seleccionar este archivo para recuperarlo.
También algunas placas base tienen BIOS de respaldo o copia de seguridad que ayudan a restaurar el BIOS. O bien, el fabricante vende chips del BIOS desde su tienda online, a buen precio.
Por último, queda reiterar la recomendación de que te apoyes en un experto para la actualización del BIOS.

por Pandora FMS team | Last updated Apr 11, 2024 | Comunidad, Tecnología
Bebes agua del grifo todos los días, ¿verdad? ¿Sabes quién inventó el mecanismo de filtrado que hace que su agua esté pura y limpia?… bueno, ¿de verdad te importa?
¿Sabes que ese mecanismo es exactamente el mismo en todos los grifos de todas las casas de cualquier país?, ¿sabes que esa pieza, especializada, es obra de un ingeniero que lo hace por amor al arte?, ¿te imaginas que puede pasar si esta persona tiene un mal día?
Hablemos de la librería XZ Utils y por qué no es buena idea depender de un único proveedor y encima tocarle las narices. Hablemos de la librería XZ Utils y de su último desarrollador, Jia Tan.
Sí, el software de código abierto nos puede ofrecer una serie de beneficios en términos de precio (sí, porque es “gratis”), transparencia, colaboración y adaptabilidad, pero también entraña un riesgo respecto a la seguridad y confianza excesiva que depositamos como usuarios.
¿Qué ocurrió?
El pasado 29 de marzo, Red Hat, Inc. daba a conocer la vulnerabilidad CVE-2024-3094, contando con una puntuación de 10 en la escala de Common Vulnerability Scoring System, y, por lo tanto, una vulnerabilidad crítica, la cual comprometía a los servidores SSH afectados.
Esta vulnerabilidad afectaba al paquete XZ Utils, que es un conjunto de herramientas de software que proporcionan compresión y descompresión de archivos mediante el algoritmo LZMA/LZMA2, y que se incluye en las principales distribuciones de Linux. De no haber sido descubierta, podría haber sido muy grave, ya que se trataba de un código malicioso de tipo backdoor el cual otorgaría acceso remoto no autorizado a los sistemas afectados mediante SSH.
La vulnerabilidad daba comienzo en la versión 5.6.0 de XZ, y afectaría también a la versión 5.6.1.
Durante el proceso de compilación de liblzma extraería un archivo de prueba camuflado existente en el código fuente, posteriormente utilizado para modificar funciones específicas en el código liblzma. El resultado es una librería liblzma modificada, que puede ser usada por cualquier software enlazado a la misma, interceptando y modificando la interacción de datos con la librería.
Este proceso de implementar una backdoor en XZ es la parte final de una campaña que se ha extendido durante 2 años de operaciones, principalmente de tipo HUMNIT (inteligencia humana) por parte del usuario Jia Tan.
El usuario Jia Tan creó su cuenta de Github en 2021, realizando su primer commit al repositorio de XZ el día 6 de febrero de 2022. Más recientemente, el 16 de febrero de 2024 se añadiría un fichero malicioso bajo el nombre de “build-to-host.m4” en .gitignore, posteriormente incorporado junto al lanzamiento del paquete, para finalmente el día 9 de marzo de 2024 incorporar el backdoor oculto en dos ficheros de testeo:
- tests/files/bad-3-corrupt_lzma2.xz
- tests/files/good-large_compressed.lzma
¿Cómo se dieron cuenta?
La principal persona encargada de localizar este problema es Andres Freund.
Se trata de uno de los ingenieros de software más importantes en Microsoft, quien se encontraba realizando tareas de micro-benchmarking. Durante sus pruebas, se dio cuenta de que los procesos de sshd estaban usando una cantidad de CPU poco normal a pesar de que no se establecieran las sesiones.
Tras perfilar sshd, vio mucho tiempo de CPU en la librería liblzma. Esto a su vez le recordó a una reciente y extraña queja de Valgrind sobre las pruebas automatizadas en PostgreSQL. Este comportamiento podría haberse pasado por alto y no ser descubierto, lo que hubiera originado una gran brecha de seguridad en servidores SSH Debian/Ubuntu
Según comenta el propio Andres Freund, se requirieron de una serie de coincidencias para poder encontrar esta vulnerabilidad, vamos que fue cuestión de suerte haberlo encontrado.
Lo que encendió las alarmas de Freund fue un pequeño retraso de tan solo 0.5 sec en las conexiones ssh, que aunque parece muy poco, fue lo que lo llevó a investigar más a fondo y encontrarse con el problema y el potencial caos que pudo haber generado.
Esto recalca la importancia de vigilar la ingeniería de software y las prácticas de seguridad. La buena noticia es que, la vulnerabilidad se ha encontrado en releases muy tempranas del software, por lo que en el mundo real no ha tenido prácticamente ningún efecto, gracias a la rápida detección de este código malicioso. Pero nos hace pensar en lo que habría podido pasar, de no haberse detectado a tiempo. No es la primera vez que ocurre ni la última que ocurrirá. La ventaja del Open Source es que esto se ha hecho público y se puede evaluar el impacto, en otros casos donde no hay dicha transparencia, el impacto puede ser más difícil de evaluar y por tanto, la remediación.
Reflexión
Con lo sucedido, podemos destacar tanto puntos positivos como negativos relacionados con el uso del código abierto.
Como puntos positivos podemos encontrar transparencia y colaboración entre desarrolladores de todo el mundo. Tener una comunidad vigilante, encargada de detectar y reportar posibles amenazas de seguridad, y contar con flexibilidad y adaptabilidad, ya que la naturaleza del código abierto permite adaptar y modificar el software según las necesidades específicas.
En cuanto a lo malo, encontramos la vulnerabilidad a ataques maliciosos, como es este caso con la actuación de desarrolladores con intenciones malignas. Los usuarios confían en que el software no contenga código malicioso, lo que puede llevar a una falsa sensación de seguridad. Además, debido a la cantidad de contribuciones que existen y a la propia complejidad del software, se puede decir que es muy difícil verificar de manera exhaustiva el código.
Si a esto le añadimos la existencia de librerías que son mantenidas por una persona o un muy pequeño grupo de personas, el riesgo de punto único de falla es mayor. En este caso, esa necesidad o beneficio de disponer de más gente aportando es lo que causó el problema.
En conclusión, si bien el software de código abierto nos puede ofrecer una serie de beneficios en términos de transparencia, colaboración y adaptabilidad, también puede presentar desventajas o desafíos en cuanto a la seguridad y confianza que depositamos como usuarios.

por Olivia Díaz | Last updated Apr 1, 2024 | Pandora FMS
Hablar de demasiadas alertas en ciberseguridad no es hablar del cuento de Pedro y el Lobo y de cómo las personas acaban por ignorar advertencias falsas, sino de su gran impacto en las estrategias de seguridad y, sobre todo, en el estrés que causa al equipo de TI, que bien sabemos son cada vez más reducidos y deben cumplir diversas tareas en su día a día.
La Fatiga de Alertas o fatiga de alarma es un fenómeno en el que el exceso de alertas insensibiliza a las personas encargadas de responder a ellas, lo que lleva a alertas perdidas o ignoradas o, lo que es peor, respuestas tardías. Los profesionales de operaciones de seguridad de TI son propensos a esta fatiga debido a que los sistemas están sobrecargados con datos y pueden no clasificar las alertas con exactitud.
Definición de Fatiga de Alertas y su impacto en la seguridad de la organización
La fatiga de alertas, además de abrumar con datos por interpretar, desvía la atención de lo que es realmente importante. Para ponerlo en perspectiva, el engaño es una de las tácticas de guerra más antiguas desde los antiguos griegos: mediante el engaño, se desviaba la atención del enemigo dando la impresión de que se estaba produciendo un ataque en un lugar, haciendo que el enemigo concentrara sus recursos en dicho lugar para poder atacar por otro frente diferente. Trasladando esto a una organización, el cibercrimen bien puede causar y aprovechar la Fatiga del staff de TI para hallar brechas de seguridad. El costo de esto puede ser alto en la continuidad del negocio y consumo de recursos (tecnología, tiempo y recursos humanos), tal y como lo indica un artículo de Security Magazine sobre una encuesta a 800 profesionales de TI:
- 85% por ciento de los profesionales de tecnología de la información (TI) dicen que más del 20% de sus alertas de seguridad en la nube son falsos positivos. Cuantas más alertas, más difícil se hace identificar qué cosas son importantes y qué cosas no lo son.
- 59% de los encuestados recibe más de 500 alertas de seguridad de la nube pública por día. Al tener que filtrar las alertas, se pierde tiempo valioso que podría usarse para solucionar o incluso prevenir los problemas.
- Más del 50% de los encuestados dedica más de 20% de su tiempo a decidir qué alertas deben abordarse primero. La sobrecarga de alertas y las tasas de falsos positivos no solo contribuyen a la rotación, sino también a la pérdida de alertas críticas. 55% dicen que su equipo pasó por alto alertas críticas en el pasado debido a una priorización ineficaz de las alertas, a menudo semanalmente e incluso diariamente.
Lo que sucede es que el equipo que se encarga de revisar las alertas se va insensibilizando. Por naturaleza humana, cuando nos llega un aviso de cada pequeña cosa, nos acostumbramos a que las alertas sean poco importantes, así que se le da cada vez menos importancia. Esto significa que hay que encontrar el equilibrio: necesitamos estar enterados del estado de nuestro entorno, pero demasiadas alertas pueden causar más daño que la ayuda que prestan, porque dificultan la priorización de los problemas.
Causas de la Fatiga de Alertas
La Fatiga de Alertas se debe a una o varias de estas causas:
Son situaciones en las que un sistema de seguridad identifica erróneamente una acción o evento benigno como una amenaza o riesgo. Pueden deberse a varios factores, como firmas de amenazas desactualizadas, malas configuraciones de seguridad (o demasiado entusiastas), o limitaciones en los algoritmos de detección.
Falta de contexto
Las alertas deben ser interpretadas, por lo que, si las notificaciones de alerta no tienen el contexto adecuado, puede resultar confuso y difícil determinar la severidad de una alerta. Esto lleva a respuestas tardías.
Varios sistemas de seguridad
La consolidación y la correlación de las alertas se dificultan si existen diversos sistemas de seguridad que trabajan al mismo tiempo… y esto empeora cuando crece el volumen de alertas con distintos niveles de complejidad.
Falta de filtros y personalización de alertas de ciberseguridad
Si no se definen y filtran puede provocar un sinfín de notificaciones no amenazadoras o irrelevantes.
Políticas y procedimientos de seguridad no claros
Los procedimientos mal definidos llegan a ser muy problemáticos porque contribuyen a agravar el problema.
Escasez de recursos
No es fácil contar con profesionales de la seguridad que sepan interpretar y además gestionar un alto volumen de alertas lo que conduce a respuestas tardías.
Lo anterior nos dice que se requiere de una correcta gestión y políticas de alertas, junto con las herramientas adecuadas de monitorización que apoyen al staff de TI.
Falsos positivos más comunes
De acuerdo con el Institute of Data, los falsos positivos con los que se enfrentan los equipos de TI y seguridad son:
Falsos positivos sobre anomalías en la red
Estos ocurren cuando las herramientas de monitorización de red identifican actividades de red normales o inofensivas como sospechosas o maliciosas, tales como alertas falsas para escaneos de red, intercambio legítimo de archivos o actividades del sistema en segundo plano.
Falsos positivos de malware
El software antivirus a menudo marca archivos o aplicaciones benignas como potencialmente maliciosas. Esto puede suceder cuando un archivo comparte similitudes con firmas de malware conocidas o muestra un comportamiento sospechoso. Un falso positivo en ciberseguridad en este contexto puede resultar en el bloqueo o cuarentena de software legítimo, provocando interrupciones en las operaciones normales.
Falsos positivos sobre el comportamiento del usuario
Los sistemas de seguridad que monitorizan las actividades de los usuarios pueden generar un falso positivo en ciberseguridad cuando las acciones de un individuo se marcan como anormales o potencialmente maliciosas. Ejemplo: un empleado que accede a documentos confidenciales después del horario laboral, generando un falso positivo en ciberseguridad, aunque pueda ser legítimo.
También se pueden encontrar falsos positivos en los sistemas de seguridad del correo electrónico. Por ejemplo, los filtros de Spam pueden clasificar erróneamente los correos electrónicos legítimos como spam, lo que hace que los mensajes importantes terminen en la carpeta de correo no deseado. ¿Puedes imaginarte el impacto de que un correo de vital importancia acabe en la carpeta de Spam?
Consecuencias de la Fatiga de Alertas
La Fatiga de Alertas tiene consecuencias no sólo en el propio staff de TI sino también en la organización:
Falsa sensación de seguridad
Demasiadas alertas pueden llevar al equipo de TI a pensar que son falsos positivos, dejando de lado las acciones que se podrían tomar.
Respuesta tardía
El exceso de alertas saturan al equipo de TI, impidiendo reaccionar a tiempo ante riesgos reales y críticos. Esto, a su vez, provoca remediaciones costosas e incluso la necesidad de asignar más personal para resolver el problema que pudo evitarse.
Incumplimiento regulatorio
Las filtraciones de seguridad pueden conducir a multas y sanciones para la organización.
Una violación a la seguridad de la empresa llega a divulgarse (y hemos visto titulares en las noticias) e impacta a su reputación. Esto puede llevar a la pérdida de confianza de lo clientes… y, por consiguiente, generar menos ingresos.
Sobrecarga de trabajo para el staff de TI
Si el personal a cargo de la monitorización de las alertas se siente abrumado de notificaciones, pueden experimentar mayor estrés laboral. Ésta ha sido una de las causas de menor productividad y una alta rotación de personal en el área de TI.
Deterioro de la moral
La desmotivación del equipo puede hacer que dejen de involucrarse y volverse menos productivos.
¿Cómo evitar estos problemas de Fatiga de Alertas?
Si se diseñan las alertas antes de implementarlas, se convierten en alertas útiles y eficientes, además de ahorrar mucho tiempo y, en consecuencia, se reduce la fatiga de alertas.
Priorizar
La mejor forma de conseguir un alertado efectivo es usar la estrategia “menos es más”. Hay que pensar primero en las cosas absolutamente imprescindibles.
- ¿Qué equipos son absolutamente imprescindibles? Casi nadie necesita alertas en equipos de pruebas.
- ¿Cuál es la gravedad si cierto servicio no funciona adecuadamente? Los servicios de alto impacto deben tener el alertado más agresivo (nivel 1, por ejemplo).
- ¿Qué es lo mínimo que se necesita para determinar que un equipo, proceso o servicio NO está funcionando correctamente? A veces es suficiente monitorizar la conectividad del dispositivo, en otras ocasiones se necesita algo más específico, como el estado de un servicio.
Responder estas preguntas ayudará a saber cuáles son las alertas más importantes sobre las que necesitamos actuar inmediatamente.
Evitar falsos positivos
A veces puede ser complicado conseguir que las alertas sólo se disparen cuando realmente existe un problema. Configurar los umbrales correctamente es gran parte del trabajo, pero hay más opciones disponibles. Pandora FMS tiene varias herramientas para ayudar a evitar falsos positivos:
Umbrales dinámicos
Son muy útiles para ajustar los umbrales a los datos reales. Al activar esta función en un módulo, Pandora FMS hace un análisis de su histórico de datos, y modifica automáticamente los umbrales para que capturen los datos que se salen de lo normal.
- Umbrales FF: En ocasiones el problema no es que no hayamos definido correctamente las alertas o los umbrales, sino que las métricas que utilizamos no son del todo fiables. Pongamos que estamos monitorizando la disponibilidad de un dispositivo, pero la conexión a la red en la que se encuentra es inestable (por ejemplo, una red inalámbrica muy saturada). Esto puede hacer que se pierdan paquetes de datos o, incluso, que haya momentos en los que un ping no consiga conectar con el dispositivo a pesar de estar activo y llevando a cabo su función correctamente. Para estos casos, Pandora FMS cuenta con el Umbral FF (FF Threshold). Usando esta opción podemos configurar cierta “tolerancia” al módulo antes de cambiar de estado. De este modo, por ejemplo, el agente reportará dos datos críticos consecutivos para que el módulo cambie a estado crítico.
- Utilizar ventanas de mantenimiento: Pandora FMS permite deshabilitar temporalmente el alertado e incluso la generación de eventos de un módulo o agente concretos con el modo silencioso (Quiet). Con las ventanas de mantenimiento (Scheduled downtimes), esto se puede programar para que, por ejemplo, no salten alertas durante las actualizaciones del servicio X en la madrugada de los sábados.
Mejorar los procesos de alerta
Una vez que se hayan asegurado de que las alertas que se disparen son las necesarias, y que sólo saltarán cuando realmente ocurra algo, podemos mejorar mucho más el proceso como sigue:
- Automatización: El alertado no sólo sirve para enviar notificaciones; también se puede usar para automatizar acciones. Imaginemos que estamos monitorizando un antiguo servicio que a veces se satura, y cuando eso ocurre, la manera de recuperarlo es simplemente reiniciarlo. Con Pandora FMS podemos configurar la alerta que monitoriza ese servicio para que trate de reiniciarlo automáticamente. Para ello, sólo debemos configurar un comando de alerta que, por ejemplo, haga una llamada API al gestor de dicho servicio para que lo reinicie.
- Escalado de alertas: Siguiendo con el ejemplo anterior, con el escalado de alertas podemos hacer que la primera acción que realice Pandora FMS, cuando se dispara la alerta, sea un reinicio del servicio. Si en la siguiente ejecución del agente, el módulo sigue en estado crítico, podemos configurar la alerta para que, por ejemplo, se cree un ticket en Pandora ITSM.
- Umbrales de alerta (alert threshold): Las alertas tienen un contador interno que indica cuándo se deben disparar las acciones configuradas. Simplemente modificando el umbral de una alerta podemos pasar de tener varios correos al día avisándonos del mismo problema a recibir uno cada dos o tres días.
Esta alerta (de ejecución diaria) tiene tres acciones: en un primer momento, se trata de reiniciar el servicio. Si a la siguiente ejecución de alerta el módulo no se ha recuperado, se manda un correo al administrador, y si aún no se ha solucionado, se crea un ticket en Pandora ITSM. Si la alerta se mantiene disparada a la cuarta ejecución, se mandará un mensaje diario por Slack al grupo de operadores.
Otras formas de reducir el número de alertas
- La protección en cascada (Cascade Protection) es una herramienta inestimable en la configuración de un alertado eficiente, al omitir el disparo de alertas de dispositivos dependientes de un dispositivo principal. Con un alertado básico, si estamos monitorizando una red a la que accedemos por medio de un switch específico y este dispositivo tiene un problema, comenzaremos a recibir alertas por cada equipo de esa red a la que ya no podemos acceder. En cambio, si activamos la protección en cascada en los agentes de esa red (indicando que dependen del switch), Pandora FMS detectará que el equipo principal está caído, y omitirá el alertado de todos los equipos dependientes hasta que el switch vuelva a estar operativo.
- El uso de servicios puede ayudarnos no sólo a reducir el número de alertas disparadas, sino también el número de alertas configuradas. Si tenemos un clúster de 10 máquinas, quizá no sea muy eficiente tener una alerta para cada una de ellas. Pandora FMS permite agrupar agentes y módulos en Servicios, junto con estructuras jerárquicas en las que podemos decidir el peso de cada elemento y alertar en base al estado general.
Implementar un plan de respuesta a incidentes
La respuesta a incidentes es el proceso de prepararse para las amenazas a la ciberseguridad, detectarlas a medida que surgen, responder para sofocarlas o mitigarlas. Las organizaciones pueden gestionar la inteligencia y mitigación de amenazas a través de la planificación de respuesta a incidentes. Hay que recordar que cualquier organización corre el riesgo de perder dinero, datos y reputación debido a las amenazas a la ciberseguridad.
La respuesta a incidentes requiere reunir un equipo de personas de diferentes departamentos dentro de una organización, incluyendo líderes de la organización, parte del staff de TI y otras áreas involucradas en el control y cumplimiento de datos. Se recomienda:
- Planificar cómo analizar datos y redes en busca de posibles amenazas y actividades sospechosas.
- Decidir qué incidentes deben recibir una respuesta primero.
- Tener un plan para la pérdida de datos y finanzas.
- Cumplir con todas las leyes pertinentes.
- Estar preparado para presentar datos y documentación a las autoridades después de una infracción.
Por último, un recordatorio oportuno: la respuesta a incidentes se volvió muy importante a partir del RPDG con normas extremadamente estrictas sobre informes de incumplimiento. Si hay que denunciar un incumplimiento concreto, la empresa debe tener conocimiento de ello en 72 horas y comunicar lo sucedido a las autoridades correspondientes. También se debe proporcionar un informe de lo sucedido y presentar un plan activo para mitigar el daño. Si una empresa no tiene un plan de respuesta a incidentes predefinido, no estará lista para presentar dicho informe.
LA RPDG también requiere saber si la organización cuenta con las medidas de seguridad adecuadas. Las empresas pueden ser fuertemente penalizadas si son examinadas después de la infracción y los funcionarios descubren que no contaban con la seguridad adecuada.
Conclusión
Está claro el alto costo tanto para el personal de TI (constante rotación, agotamiento, estrés, decisiones tardías, etc.) como para la organización (interrupción de las operaciones, filtraciones y violaciones de seguridad, sanciones bastante onerosas). Aunque no existe una solución única para evitar el exceso de alertas, sí se recomienda priorizar alertas, evitar falsos positivos (umbrales dinámicos y FF, ventanas de mantenimiento), mejoras en procesos de alertas y un plan de respuesta a incidentes, junto con políticas y procedimientos claros para responder a incidentes, con el fin de asegurarte de encontrar el equilibrio adecuado para tu organización.
Contáctanos para acompañarte con las mejores prácticas de Monitorización y alertas.
Si te interesó este artículo, puedes leer también: ¿Sabes para qué sirven los umbrales dinámicos en la monitorización?

por Ahinóam Rodríguez | Last updated Mar 19, 2024 | Pandora FMS
En la actualidad muchas empresas generan y almacenan enormes cantidades de datos. Para hacernos una idea, décadas atrás, el tamaño de Internet se medía en Terabytes (TB) y ahora se mide en Zettabytes (ZB).
Las bases de datos relacionales se diseñaron para satisfacer las necesidades de almacenamiento y gestión de la información que había en la época. Hoy en día tenemos un escenario nuevo donde las redes sociales, los dispositivos IoT y el Edge Computing generan millones de datos no estructurados y altamente variables. Muchas aplicaciones modernas requieren un alto rendimiento para proporcionar respuestas rápidas a las consultas de los usuarios.
En los SGBD relacionales un incremento en el volumen de datos debe ir acompañado de mejoras en la capacidad del hardware. Este desafío tecnológico obligó a las empresas a buscar soluciones más flexibles y escalables.
Las bases de datos NoSQL tienen una arquitectura distribuida que les permite escalar horizontalmente y manejar flujos de datos continuos y rápidos. Esto las convierte en una opción viable en entornos de alta demanda como las plataformas de streaming donde el procesamiento de los datos se realiza en tiempo real.
Ante el interés que despiertan las bases de datos NoSQL en el contexto actual, nos parece indispensable elaborar una guía de uso que ayude a los desarrolladores a comprender y utilizar eficazmente esta tecnología. En este artículo nos proponemos aclarar algunos conceptos básicos sobre NoSQL, poniendo ejemplos prácticos y proporcionando recomendaciones sobre implementación y optimización para aprovechar al máximo sus ventajas.
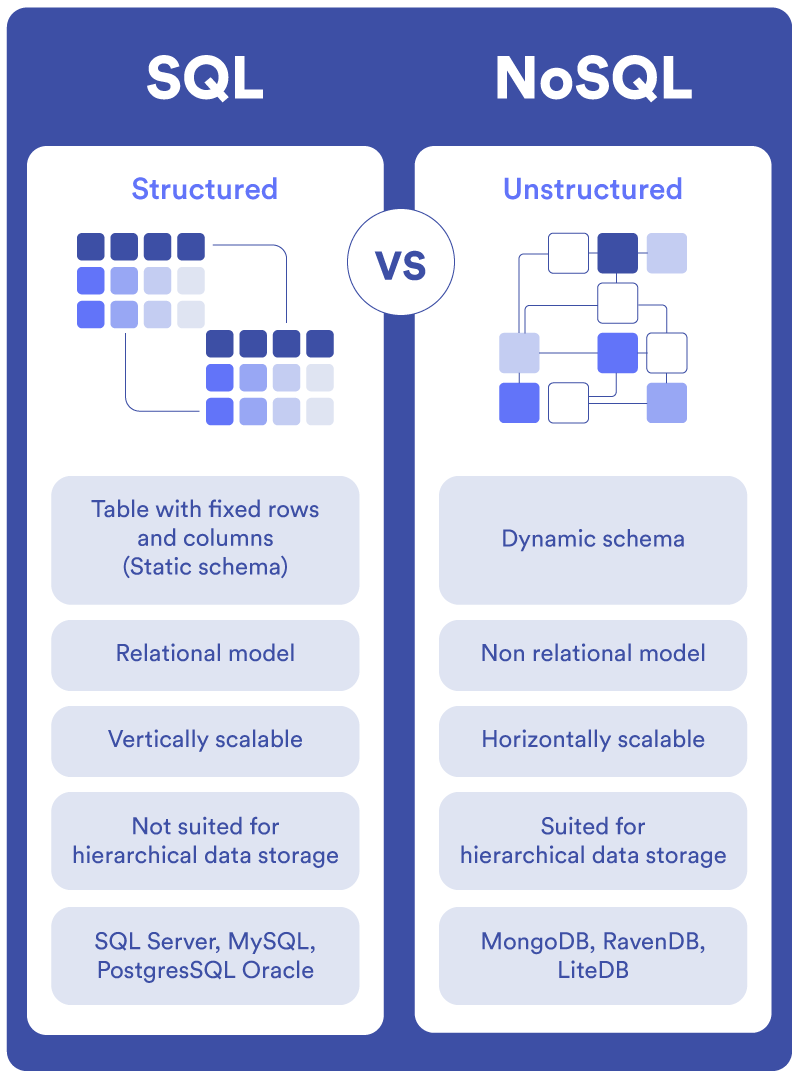
Modelado de datos en NoSQL
Una de las mayores diferencias entre las bases de relacionales y no relacionales radica en el enfoque que adoptamos para el modelado de datos.
Las BBDD NoSQL no siguen un esquema rígido y predefinido. Esto permite a los desarrolladores elegir libremente el modelo de datos en función de las características del proyecto.
El objetivo fundamental es mejorar el rendimiento de las consultas, eliminando la necesidad de estructurar la información en tablas complejas. Así, NoSQL admite una gran variedad de datos desnormalizados como documentos JSON, valores clave, columnas y relaciones de grafos.
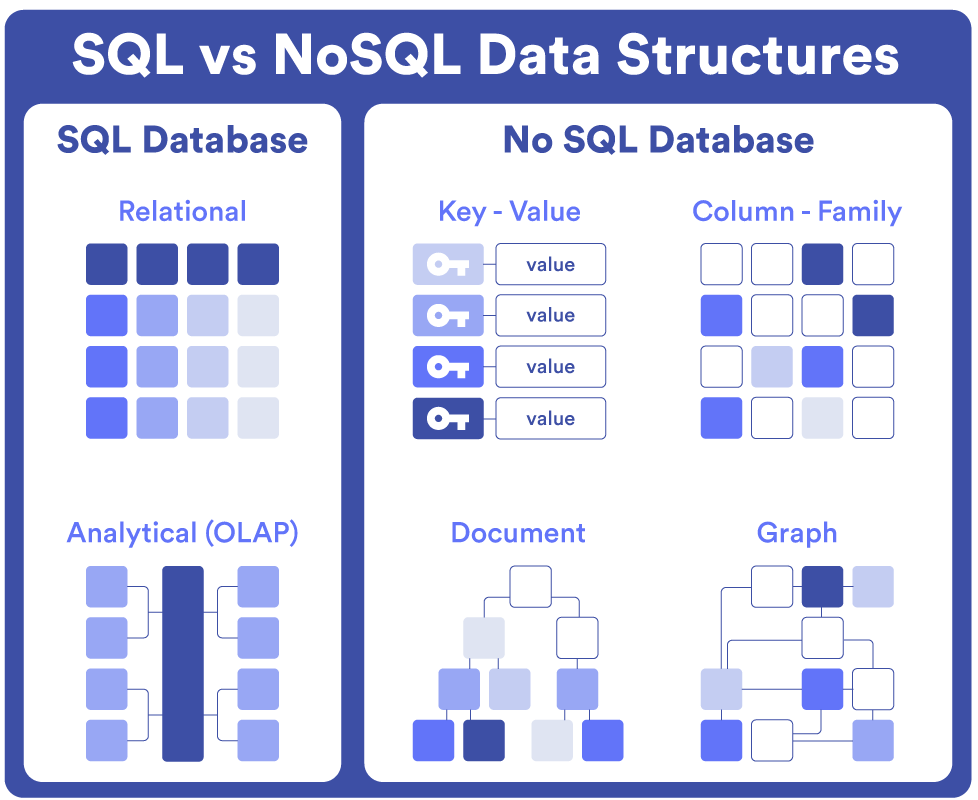
Cada tipo de base de datos NoSQL está optimizado para facilitar el acceso, consulta y modificación de una clase específica de datos. Las principales son:
- Clave-valor: Redis, Riak o DyamoDB. Son las BBDD NoSQL más sencillas. Almacenan la información como si fuera un diccionario basado en pares de clave-valor, donde cada valor está asociado con una clave única. Se diseñaron con la finalidad de escalar rápidamente garantizando el rendimiento del sistema y la disponibilidad de los datos.
- Documentales: MongoDB, Couchbase. Los datos se almacenan en documentos como JSON, BSON o XML. Algunos las consideran un escalón superior de los sistemas clave-valor ya que permiten encapsular los pares de clave-valor en estructuras más complejas para realizar consultas avanzadas.
- Orientadas a columnas: BigTable, Cassandra, HBase. En lugar de almacenar los datos en filas como lo hacen las bases de datos relacionales, lo hacen en columnas. Estas a su vez se organizan en familias de columnas ordenadas de forma lógica en la base de datos. El sistema está optimizado para trabajar con grandes conjuntos de datos y cargas de trabajo distribuidas.
- Orientadas a grafos: Neo4J, InfiniteGraph. Guardan los datos como entidades y relaciones entre entidades. Las entidades se llaman “nodos” y las relaciones que unen los nodos son los “bordes”. Son ideales para gestionar datos con relaciones complejas, como redes sociales o aplicaciones con ubicación geoespacial.
Almacenamiento y particionado de datos en NoSQL
En lugar de emplear una arquitectura monolítica y costosa donde todos los datos se almacenan en un único servidor, NoSQL distribuye la información en diferentes servidores conocidos como “nodos” que se unen en una red llamada “clúster”.
Esta característica permite a los SGBD NoSQL escalar horizontalmente y gestionar grandes volúmenes de datos mediante técnicas de particionado.
¿Qué es el particionado en bases de datos NoSQL?
Es un proceso que consiste en dividir una base de datos de gran tamaño en fragmentos más pequeños y fáciles de administrar.
Es necesario aclarar que el particionado de datos no es exclusivo de NoSQL. Las bases de datos SQL también soportan particionado, pero los sistemas NoSQL poseen una función nativa llamada “auto-sharding” que divide los datos de manera automática, balanceando la carga entre los servidores.
¿Cuándo particionar una base de datos NoSQL?
Existen varias situaciones en las que es necesario particionar una BBDD NoSQL:
- Cuando el servidor está al límite de su capacidad de almacenamiento o memoria RAM.
- Cuando necesitamos reducir la latencia. En este caso balanceamos la carga de trabajo en diferentes nodos del clúster para mejorar el rendimiento.
- Cuando queremos asegurar la disponibilidad de los datos iniciando un procedimiento de replicado.
Aunque el particionado se utiliza en BBDD de gran tamaño, no debemos esperar a que el volumen de datos sea excesivo porque en este caso podría provocar la sobrecarga del sistema.
Muchos programadores utilizan AWS o Azure para simplificar el proceso. Estas plataformas ofrecen una gran variedad de servicios en la nube que permiten a los desarrolladores despreocuparse de las tareas relacionadas con la administración de las bases de datos y centrarse en escribir el código de sus aplicaciones.
Técnicas de particionado
Existen diferentes técnicas para realizar el particionado de una base de datos de arquitectura distribuida.
- Clustering
Consiste en agrupar varios servidores para que trabajen juntos como si fueran uno solo. En un entorno de clustering todos los nodos del clúster comparten la carga de trabajo para aumentar la capacidad de procesamiento del sistema y la tolerancia a fallos.
- Separación de lecturas y escrituras
Consiste en dirigir las operaciones de lectura y escritura a diferentes nodos del clúster. Por ejemplo, las operaciones de lectura se pueden dirigir a servidores de réplica que ejercen de esclavos para aliviar la carga del nodo principal.
- Sharding
Los datos se dividen horizontalmente en fragmentos más pequeños llamados “shards” y se distribuyen en diferentes nodos del clúster.
Es la técnica de particionado más utilizada en bases de datos con arquitectura distribuida por su escalabilidad y capacidad de autobalancear la carga del sistema, evitando cuellos de botella.
- Consistent Hashing
Es un algoritmo que se utiliza para asignar de manera eficiente datos a nodos en un entorno distribuido.
La idea de los hashes consistentes fue introducida por David Karger en un artículo de investigación publicado en 1997 y titulado “Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web“.
En este trabajo académico se propuso por primera vez el algoritmo “Consistent Hashing” como una solución para balancear la carga de trabajo de los servidores con bases de datos distribuidas.
Es una técnica que se utiliza tanto en el particionado como en la replicación de datos ya que permite solucionar problemas comunes a ambos procesos como la redistribución de claves y de recursos cuando se añaden o se eliminan nodos en un clúster.
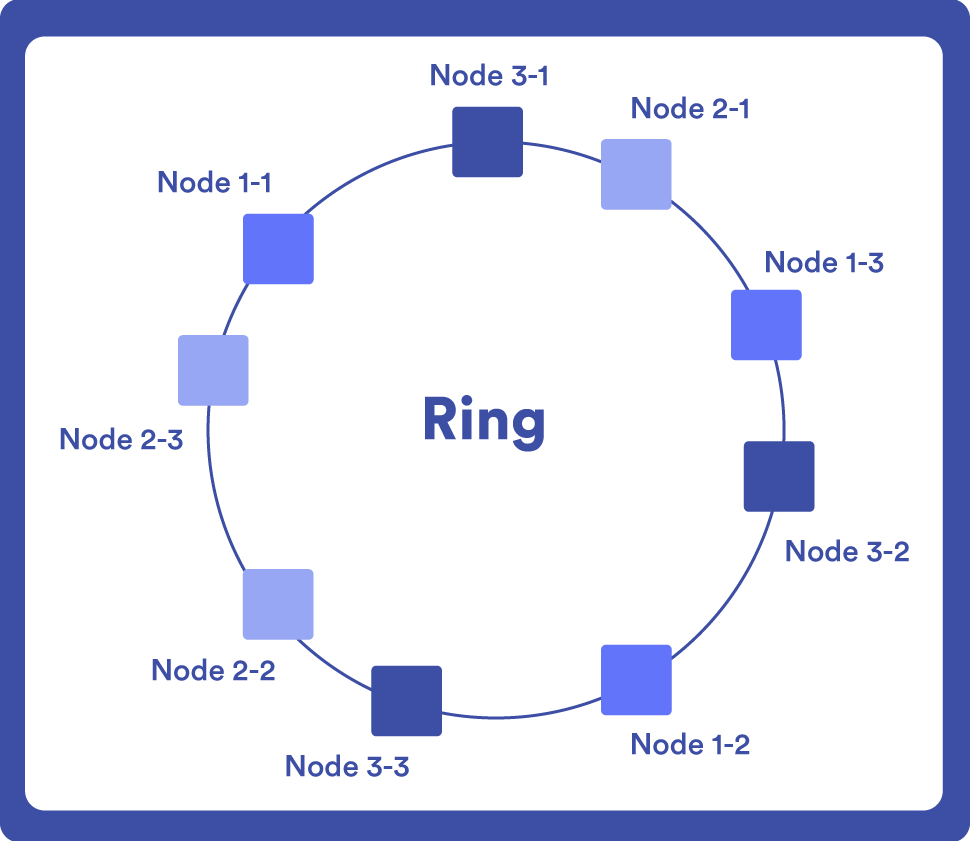
Los nodos se representan en un anillo circular y cada dato se asigna a un nodo mediante una función de hash. Cuando se añade un nuevo nodo al sistema, los datos se redistribuyen entre los nodos existentes y el nuevo nodo.
El hash funciona como un identificador único de manera que al realizar una consulta, sólo hay que ubicar ese punto sobre el anillo.
Un ejemplo de base de datos NoSQL que utiliza “Consistent Hashing” es DynamoDB, ya que uno de sus puntos fuertes es el escalado incremental, y para conseguirlo necesita un procedimiento capaz de fraccionar los datos de manera dinámica.
Replicado en bases de datos NoSQL
Consiste en crear copias de los datos en múltiples máquinas. Este proceso busca mejorar el rendimiento de las BBDD, distribuyendo las consultas entre diferentes nodos. Al mismo tiempo, garantiza que la información seguirá estando disponible, aunque se produzca un fallo en el hardware.
Las dos formas principales de realizar el replicado de datos (además del Consistent Hashing que ya mencionamos en el apartado anterior) son:
Servidor maestro-esclavo
La escritura se realiza en el nodo principal y desde él se replican los datos a los nodos secundarios.
Peer to peer
Todos los nodos del clúster tienen el mismo nivel jerárquico y pueden aceptar escrituras. Cuando los datos se escriben en un nodo se propagan a todos los demás. Esto garantiza la disponibilidad, pero puede provocar también inconsistencias si no se implementan mecanismos de resolución de conflictos (por ejemplo, si dos nodos intentan escribir a la vez en la misma ubicación).
Teorema de CAP y consistencia de las bases de datos NoSQL
El teorema CAP fue presentado por el profesor Eric Brewer de la Universidad de Berkeley en el año 2.000. Nos explica que una base de datos distribuida puede cumplir a la vez con dos de estas tres cualidades:
- Consistencia: Todas las peticiones posteriores a la operación de escritura obtienen el mismo valor, independientemente de dónde se realicen las consultas.
- Disponibilidad: La base de datos siempre responde a las solicitudes, incluso si se produce un fallo.
- Tolerancia a particiones: El sistema sigue funcionando aunque se interrumpa la comunicación entre algunos nodos.
Según este esquema podríamos elegir un SGBD que sea consistente y tolerante a particiones (MongoDB, HBase), disponible y tolerante a particiones (DynamoDB, Cassandra) o consistente y disponible (MySQL), pero no puede mantener las tres características a la vez.
Cada desarrollo tiene sus requerimientos y el teorema CAP nos ayuda a encontrar el SGBD que mejor se ajusta a sus necesidades. A veces es imprescindible que los datos sean consistentes en todo momento (por ejemplo, en un sistema de control de stock). En estos casos solemos trabajar con una base de datos relacional. En las bases de datos NoSQL la consistencia no está cien por cien garantizada, ya que los cambios deben propagarse entre todos los nodos del clúster.
BASE y el modelo de consistencia eventual en NoSQL
BASE es un concepto enfrentado a las propiedades ACID (atomicidad, consistencia, aislamiento, durabilidad) de las bases de datos relacionales. En este enfoque priorizamos la disponibilidad de los datos por encima de la consistencia inmediata, algo que es especialmente importante en las aplicaciones que procesan datos en tiempo real.
El acrónimo BASE significa:
- Basically Available: La base de datos envía siempre una respuesta, aunque contenga errores si se producen lecturas desde nodos que aún no han recibido la última escritura.
- Soft state: La base de datos puede estar en un estado inconsistente cuando se produce la lectura, así que es posible que obtengamos resultados dispares en diferentes lecturas.
- Eventually Consistent: La consistencia en la base de datos se alcanza una vez que la información se ha propagado a todos los nodos. Hasta ese momento hablamos de una consistencia eventual.
A pesar de que el enfoque BASE surgió en respuesta a ACID, no son opciones excluyentes. De hecho, algunas bases de datos NoSQL como MongoDB ofrecen una consistencia configurable.
Indexación de árboles en bases de datos NoSQL. ¿Cuáles son las estructuras más conocidas?
Hasta el momento hemos visto cómo se distribuyen y se replican los datos en una BBDD NoSQL, pero nos falta explicar cómo se estructuran de manera eficiente para facilitar su búsqueda y recuperación.
Los árboles son las estructuras de datos más utilizadas. Organizan los nodos de forma jerárquica partiendo de un nodo raíz que es el primer nodo del árbol, nodos padre que son todos aquellos nodos que tienen al menos un hijo, y nodos hijo que completan el árbol.
El número de niveles de un árbol determina su altura. Es importante tener en cuenta el tamaño final del árbol y el número de nodos que contiene, ya que esto puede influir en el rendimiento de las consultas y el tiempo de recuperación de los datos.
Existen diferentes índices de árboles que podemos emplear en bases de datos NoSQL.
Árboles B
Son árboles balanceados e ideales para sistemas distribuidos por su capacidad para mantener la coherencia de los índices, aunque también se pueden utilizar en bases de datos relacionales.
La característica principal de los árboles B es que pueden tener varios nodos hijos por cada nodo padre, pero siempre mantienen balanceada su altura. Esto quiere decir que poseen un número de niveles idéntico o muy similar en cada rama del árbol, una particularidad que hace posible manejar inserciones y eliminaciones de manera eficiente.
Se utilizan mucho en sistemas de archivo donde es necesario acceder con rapidez a grandes conjuntos de datos.
Árboles T
También son árboles balanceados que pueden tener como máximo dos o tres nodos hijos.
A diferencia de los árboles B que están diseñados para facilitar las búsquedas en grandes volúmenes de datos, los árboles T funcionan mejor en aplicaciones donde se necesita acceso rápido a datos ordenados.
Árboles AVL
Son árboles binarios, lo que significa que cada nodo padre puede tener como máximo dos nodos hijos.
Otra característica destacada de los árboles AVL es que están equilibrados en altura. El sistema de autobalanceo sirve para garantizar que el árbol no crezca de manera descontrolada, algo que podría perjudicar el rendimiento de la base de datos.
Son una buena elección para desarrollar aplicaciones que requieren consultas rápidas y operaciones de inserción y eliminación en tiempo logarítmico.
Árboles KD
Son árboles binarios y balanceados que organizan los datos en múltiples dimensiones. En cada nivel del árbol se crea una dimensión específica.
Se utilizan en aplicaciones que trabajan con datos geoespaciales o datos científicos.
Árboles Merkle
Representan un caso especial de estructuras de datos en sistemas distribuidos. Son conocidos por su utilidad en Blockchain para cifrar datos de manera eficiente y segura.
Un árbol Merkle es un tipo de árbol binario que ofrece una solución de primer nivel al problema de la verificación de los datos. Su creador fue un informático y criptógrafo estadounidense llamado Ralph Merkle en 1979.
Los árboles Merkle tienen una estructura matemática formada por hashes de varios bloques de datos que resumen todas las transacciones en un bloque.
Los datos se van agrupando en conjuntos de datos más grandes y se relacionan con los nodos principales hasta reunir todos los datos dentro del sistema. Como resultado, se obtiene la raíz Merkle (Merkle Root).
¿Cómo se calcula la raíz Merkle?
1. Los datos se dividen en bloques de un tamaño fijo.
2. Cada bloque de datos se somete a una función hash criptográfica.
3. Los hashes se agrupan en pares y a estos pares se les aplica nuevamente una función para generar sus respectivos hashes padres hasta que solamente queda un hash que es la raíz Merkle.
La raíz Merkle está en la cima del árbol y es el valor que representa de forma segura la integridad de los datos. Esto se debe a que está determinadamente relacionada con todos los conjuntos de datos y el hash que identifica a cada uno de ellos. Cualquier cambio en los datos originales alterará la raíz Merkle. De esta forma, podemos tener la certeza de que los datos no han sido modificados en ningún punto.
Esta es la razón por la que los árboles Merkle se emplean con frecuencia para verificar la integridad de los bloques de datos en transacciones de Blockchain.
Bases de datos NoSQL como Cassandra recurren a estas estructuras para validar los datos sin sacrificar velocidad y rendimiento.
Comparación entre sistemas de gestión de bases de datos NoSQL
Por lo que hemos podido ver hasta ahora, los SGBD NoSQL son extraordinariamente complejos y variados. Cada uno de ellos puede adoptar un modelo de datos diferente y presentar características únicas de almacenamiento, consulta y escalabilidad. Este abanico de opciones permite a los desarrolladores seleccionar la base de datos más adecuada para las necesidades de su proyecto.
A continuación, pondremos como ejemplo dos de los SGBD NoSQL más usados en la actualidad para el desarrollo de aplicaciones escalables y de alto rendimiento: MongoDB y Apache Cassandra.
MongoDB
Es un SGBD de tipo documental desarrollado por 10gen en 2007. Es de código abierto y ha sido creado en lenguajes de programación como C++ C y JavaScript.
MongoDB es uno de los sistemas más populares para bases de datos distribuidas. Redes sociales como LinkedIn, empresas de telecomunicaciones como Telefónica o medios informativos como Washington Post utilizan MongoDB.
Veamos algunas de sus características principales.
- Almacenamiento en BBDD con MongoDB: MongoDB almacena los datos en documentos BSON (JSON binario). Cada base de datos se compone de una colección de documentos. Una vez que MongoDB está instalado y la Shell está en ejecución, podemos crear la BBDD simplemente indicando el nombre que queremos usar. Si la BBDD aún no existe, MongoDB la creará automáticamente al añadir la primera colección. De manera similar, una colección se crea automáticamente al almacenar un documento en ella. Sólo tenemos que agregar el primer documento y ejecutar la sentencia “insert” y MongoDB creará un campo ID asignándole un valor del tipo ObjectID que es único para cada máquina en el momento en el que se ejecuta la operación.
- Particionado en BBDD con MongoDB: MongoDB facilita la distribución de datos en múltiples servidores utilizando la función de sharding automático. La fragmentación de los datos se produce a nivel de colección, distribuyendo los documentos entre los distintos nodos del clúster. Para efectuar esta distribución se emplea una “clave de partición” definida como campo en todos los documentos de la colección. Los datos se fragmentan en “chunks” que tienen por defecto un tamaño de 64 MB y se almacenan en diferentes shards dentro del clúster, procurando que exista un equilibrio. MongoBD monitoriza continuamente la distribución de los chunks entre los nodos del shard y si fuera necesario, efectúa un rebalanceo automático para asegurarse de que la carga de trabajo que soportan los nodos esté equilibrada.
- Replicado en BBDD con MongoDB: MongoDB utiliza un sistema de replicación basado en la arquitectura maestro-esclavo. El servidor maestro puede realizar operaciones de escritura y lectura, pero los nodos esclavos únicamente realizan lecturas (replica set). Las actualizaciones se comunican a los nodos esclavos mediante un log de operación llamado oplog.
- Consultas en BBDD con MongoDB: MongoDB cuenta con una potente API que permite acceder y analizar los datos en tiempo real, así como realizar consultas ad-hoc, es decir, consultas directas sobre una base de datos que no están predefinidas. Esto proporciona a los usuarios la posibilidad de realizar búsquedas personalizadas, filtrar documentos y ordenar los resultados por campos específicos. Para llevar a cabo estas consultas, MongoDB emplea el método “find” sobre la colección deseada o “findAndModify” para consultar y actualizar los valores de uno o más campos simultáneamente.
- Indexación en BBDD con MongoDB: MongoDB utiliza árboles B+ para indexar los datos almacenados en sus colecciones. Se trata de una variante de los árboles B con nodos de índice que contienen claves y punteros a otros nodos. Estos índices almacenan el valor de un campo específico, permitiendo que las operaciones de recuperación y eliminación de datos sean más eficientes.
- Coherencia en BBDD con MongoDB: A partir de la versión 4.0 (la más reciente es la 6.0), MongoDB soporta transacciones ACID a nivel de documento. La función “snapshot isolation” ofrece una visión coherente de los datos y permite realizar operaciones atómicas en múltiples documentos dentro de una sola transacción. Esta característica es especialmente relevante para las bases de datos NoSQL, ya que plantea soluciones a diferentes problemas relacionados con la consistencia, como escrituras concurrentes o consultas que devuelven versiones obsoletas de un documento. En este aspecto, MongoDB se acerca mucho a la estabilidad de los RDMS.
- Seguridad en BBDD con MongoDB: MongoDB tiene un nivel de seguridad alto para garantizar la confidencialidad de los datos almacenados. Cuenta con varios mecanismos de autenticación, configuración de accesos basada en roles, cifrado de datos en reposo y posibilidad de restringir el acceso a determinadas direcciones IP. Además, permite auditar la actividad del sistema y llevar un registro de las operaciones realizadas en la base de datos.
Apache Cassandra
Es un SGBD orientado a columnas que fue desarrollado por Facebook para optimizar las búsquedas dentro de su plataforma. Uno de los creadores de Cassandra es el informático Avinash Lakshman que trabajó anteriormente con Amazon, formando parte del grupo de ingenieros que desarrolló DynamoDB. Por este motivo, no es extraño que comparta algunas características con este otro sistema.
En el año 2008 fue lanzado como proyecto open source y en 2010 se convirtió en un proyecto top-level de la Fundación Apache. Desde entonces Cassandra continuó creciendo hasta ser uno de los SGBD NoSQL más populares.
Aunque a día de hoy Meta utiliza otras tecnologías, Cassandra sigue formando parte de su infraestructura de datos. Otras empresas que lo utilizan son Netflix, Apple o Ebay. En términos de escalabilidad está considerada como una de las mejores bases de datos NoSQL.
Veamos algunas de sus características más destacadas:
- Almacenamiento en BBDD con Apache Cassandra: Cassandra utiliza un modelo de datos tipo “Column Family”, que es similar a las bases de datos relacionales, pero más flexible. No se refiere a una estructura jerárquica de columnas que contengan otras columnas, sino más bien a una colección de pares clave-valor, donde la clave identifica una fila y el valor es un conjunto de columnas. Es un diseño pensado para almacenar grandes cantidades de datos y realizar operaciones de escritura y lectura más eficientes.
- Particionado en BBDD con Apache Cassandra: Para la distribución de datos Cassandra utiliza un particionador que reparte los datos en diferentes nodos del clúster. Este particionador usa el algoritmo “consistent hashing” para asignar una clave de partición única a cada fila de datos. Los datos que poseen la misma clave de partición estarán juntos en los mismos nodos. También admite nodos virtuales (vnodes), lo que significa que un mismo nodo físico puede tener varios rangos de datos.
- Replicado en BBDD con Apache Cassandra: Cassandra propone un modelo de replicado basado en Peer to peer en el que todos los nodos del clúster aceptan lecturas y escrituras. Al no depender de un nodo maestro para procesar las solicitudes, la posibilidad de que se produzca un cuello de botella es mínima. Los nodos se comunican entre sí y comparten datos utilizando un protocolo de gossiping.
- Consultas en BBDD con Apache Cassandra: Al igual que MongoDB, Cassandra también admite consultas ad-hoc, pero estas tienden a ser más eficientes si están basadas en la clave primaria. Además, dispone de su propio lenguaje de consulta llamado CQL (Cassandra Query Language) con una sintaxis similar a SQL, pero que en lugar de utilizar joins apuesta por la desnormalización de los datos.
- Indexación en BBDD con Apache Cassandra: Cassandra utiliza índices secundarios para permitir consultas eficientes sobre columnas que no forman parte de la clave primaria. Estos índices pueden afectar a columnas individuales o a varias columnas (SSTable Attached Secondary Index). Se crean para permitir consultas complejas de rango, prefijo o búsqueda de texto en un gran número de columnas.
- Coherencia en BBDD con Apache Cassandra: Al utilizar una arquitectura Peer to Peer Cassandra juega con la consistencia eventual. Los datos se propagan de forma asíncrona en múltiples nodos. Esto quiere decir que durante un breve periodo de tiempo puede haber discrepancias entre las diferentes réplicas. Sin embargo, Cassandra proporciona también mecanismos para configurar el nivel de consistencia. Cuando se produce un conflicto (por ejemplo, si las réplicas tienen versiones diferentes), utiliza la marca de tiempo (timestamp) y da por válida la versión más reciente. Además, realiza reparaciones automáticas para mantener la coherencia y la integridad de los datos si se presentan fallos de hardware u otros eventos que causan discrepancias entre las réplicas.
- Seguridad en BBDD con Apache Cassandra: Para utilizar Cassandra en un entorno seguro es necesario realizar configuraciones, ya que muchas opciones no están habilitadas por defecto. Por ejemplo, debemos activar el sistema de autenticación y establecer permisos para cada rol de usuario. Además, es fundamental encriptar los datos en tránsito y en reposo. Para la comunicación entre los nodos y el cliente se pueden cifrar los datos en tránsito utilizando SSL/TLS.
Desafíos en la administración de las bases de datos NoSQL ¿Cómo ayuda Pandora FMS?
Los SGBD NoSQL ofrecen a los desarrolladores la posibilidad de gestionar grandes volúmenes de datos y de escalar horizontalmente añadiendo múltiples nodos a un clúster.
Para administrar estas infraestructuras distribuidas es necesario dominar diferentes técnicas de particionado y replicación de los datos (por ejemplo, hemos visto que MongoDB utiliza una arquitectura maestro-esclavo, mientras que Cassandra prioriza la disponibilidad con el modelo Peer to peer).
A diferencia de lo que ocurre con los RDMS que comparten muchas similitudes, en las bases de datos NoSQL no hay un paradigma común y cada sistema tiene sus propias APIs, lenguajes y una implementación diferente, por lo que acostumbrarse a trabajar con cada uno de ellos puede significar un auténtico desafío.
Teniendo en cuenta que la monitorización es un componente fundamental para la administración de cualquier base de datos, debemos ser pragmáticos y apoyarnos en aquellos recursos que nos hacen la vida más fácil.
Tanto MongoDB como Apache Cassandra disponen de comandos que devuelven información sobre el estado del sistema y permiten diagnosticar problemas antes de que se conviertan en fallos críticos. Otra posibilidad es utilizar el software de Pandora FMS para simplificar todo el proceso.
¿Cómo hacerlo?
Si se trata de una base de datos en MongoDB, tenemos que descargar el plugin de Pandora FMS para MongoDB. Este plugin utiliza el comando mongostat para recopilar información básica sobre el rendimiento del sistema. Una vez obtenidas las métricas relevantes, estas son enviadas al servidor de datos de Pandora FMS para su análisis.
En cambio, si la base de datos funciona con Apache Cassandra, debemos descargar el plugin correspondiente a este sistema. Este plugin obtiene la información ejecutando internamente la herramienta nodetool, que ya está incluida en la instalación estándar de Cassandra y ofrece una amplia gama de comandos para monitorizar el estado de los servidores. Una vez que se analizan los resultados, el plugin estructura los datos en formato XML y los envía al servidor de Pandora FMS para su posterior análisis y visualización.
Para que estos plugins funcionen correctamente, hay que copiar los ficheros en el directorio de plugins del agente de Pandora FMS, editar el archivo de configuración y, por último, reiniciar el sistema (en los artículos enlazados se explica muy bien el procedimiento).
Una vez que los plugins estén activos, podremos monitorear la actividad de los nodos del clúster en una vista de gráficos y recibir alertas si se produce algún fallo. Estas y otras opciones de automatización nos ayudan a ahorrar bastante tiempo y recursos en el mantenimiento de las bases de datos NoSQL.
¡Crea una cuenta gratuita y descubre todas las utilidades de Pandora FMS para impulsar tu proyecto digital!
Y si tienes dudas sobre la diferencia entre NoSQL y SQL puedes consultar nuestro post “NoSQL vs SQL: principales diferencias y cuándo elegir cada una de ellas“.

por Pandora FMS team | Last updated Mar 12, 2024 | Pandora FMS
Hoy se requiere confianza digital dentro y fuera de una organización, por lo que se deben implementar herramientas, con métodos y mejores prácticas de ciberseguridad en cada capa de nuestros sistemas y su infraestructura: aplicaciones, sistemas operativos, usuarios, tanto en la infraestructura local como en la nube. Esto es lo que llamamos System Hardening o fortalecimiento de sistemas, una práctica esencial que establece las bases para una infraestructura informática segura. Su objetivo es reducir en lo posible la superficie de ataque, fortaleciendo los sistemas para poder enfrentar posibles ataques de seguridad y eliminar en lo posible los puntos de apoyo de entrada para el cibercrimen.
Enfoque integral para la seguridad organizacional
Para implementar la seguridad organizacional, indudablemente se requiere de un enfoque integral, ya que se debe considerar dispositivos (endpoints, sensores, IoT), hardware, software, ambientes locales, entornos cloud (e híbridos), junto con políticas de seguridad y el cumplimiento regulatorio local e incluso el internacional. Cabe recordar que hoy, y en un futuro, no solo debemos proteger los activos digitales de una organización, sino que también evitar tiempos de inactividad y las posibles sanciones regulatorias (asociadas a incumplimiento de GDPR y leyes sobre protección de datos). También el Hardening contribuye a sentar la base sólida sobre la cual implementar soluciones de seguridad avanzadas. Más adelante, en Tipos de Hardening veremos dónde es posible implementar el fortalecimiento de la seguridad.
Beneficios del Hardening en Ciberseguridad
- Mejora de la funcionalidad del sistema: Las medidas de hardening contribuyen a optimizar los recursos del sistema, además de eliminar servicios y software innecesarios y aplicar parches y actualizaciones de seguridad. Las consecuencias de acciones conducen a un mejor rendimiento del sistema, ya que también se desperdician menos recursos en componentes no utilizados o vulnerables.
- Mayor nivel de seguridad: En un sistema fortalecido se reduce la superficie de un potencial ataque y se fortalecen las defensas contra amenazas (ejemplo, malware, acceso no autorizado y filtraciones de datos). Se protege la información confidencial y se garantiza la privacidad de los usuarios.
- Simplificación de la conformidad y auditoría: Las organizaciones deben cumplir con estándares y regulaciones de seguridad específicas para su industria, con el fin de proteger datos confidenciales. El hardening ayuda a cumplir con estos requisitos y garantiza el cumplimiento de estándares específicos de la industria, como GDPR (protección de datos personales), el estándar de seguridad de datos de la industria de tarjetas de pago (PCI DSS) o la ley de responsabilidad y portabilidad de seguros médicos (HIPAA, para proteger datos de un usuario de seguros de salud).
Otros beneficios incluyen el aseguramiento de la continuidad del negocio (sin interrupciones o fricciones), la defensa en diversas capas (controles de acceso, cifrado, firewalls, sistemas de detección de intrusiones y auditorías de seguridad periódicas) y la posibilidad de asumir una postura más proactiva en la seguridad, con evaluaciones y actualizaciones periódicas para prepararse ante amenazas y vulnerabilidades emergentes.
Todo sistema seguro ha debido ser securizado antes, y esto es, precisamente, en lo que consiste el hardening.
Tipos de Hardening
En el conjunto de la infraestructura IT, existen varios subconjuntos que requieren diferentes enfoques de seguridad:
1. Hardening de la gestión de la configuración
Implementación y configuración de la seguridad para varios componentes del sistema (incluyendo hardware, sistemas operativos y aplicaciones de software). También implica deshabilitar servicios y protocolos innecesarios, configuración de controles de acceso, implementación del cifrado y protocolos de comunicación seguros. Cabe mencionar que los equipos de seguridad y de TI a menudo mantienen agendas encontradas. La política de hardening debe tomar en cuenta las discusiones entre las dos partes. Se recomienda también implementar:
- Evaluación de elementos configurables: Desde cuentas de usuario e inicios de sesión, componentes y subsistemas del servidor, qué actualizaciones y vulnerabilidades de software y aplicaciones realizar, redes y firewalls, acceso remoto y gestión de registros, etc.
- Encontrar el equilibrio entre seguridad y funcionalidad: La política de Hardening debe considerar tanto los requisitos del equipo de seguridad como la capacidad del equipo de TI para implementarla utilizando los niveles de tiempo y mano de obra asignados actualmente. También se debe decidir qué desafíos deben enfrentarse y cuáles no valen la pena por cuestiones de tiempo y costos operativos.
- Gestión de cambios y prevención de “configuration drift”: El hardening implica implementar la monitorización continua, donde las herramientas de automatización contribuyen al cumplimiento de requerimientos en cualquier momento, eliminando la necesidad de escaneo constante. También, en los cambios no deseados, se puede reforzar las políticas de hardening que puede suceder en el entorno de producción. Por último, en caso de cambios no autorizados, las herramientas de automatización ayudan a detectar anomalías y ataques para implementar acciones preventivas.
2. Hardening de aplicaciones
Protección de las aplicaciones de software que se ejecutan en el sistema, mediante eliminación o inhabilitación de características y funcionalidades innecesarias, aplicación de parches y actualizaciones de seguridad específicos para la aplicación, junto con las prácticas de codificación segura y controles de acceso, además de mecanismos de autenticación a nivel de aplicación. La importancia de la seguridad de las aplicaciones radica en que los usuarios de la organización demandan ambientes seguros y estables; por parte de los empleados, la aplicación de parches y actualizaciones permite reaccionar ante amenazas e implementar medidas preventivas. Hay que recordar que los usuarios son muchas veces el punto de entrada a la organización para el cibercrimen. Entre las técnicas más comunes, podemos mencionar:
- Instalación de aplicaciones solo desde repositorios confiables.
- Parches de automatizaciones de aplicaciones estándar y de terceros.
- Instalación de cortafuegos, antivirus y programas de protección contra malware o spyware.
- Cifrado de datos basado en software.
- Aplicaciones de gestión y cifrado de contraseñas
3.Hardening de Sistema Operativo (OS)
Configuración del sistema operativo para minimizar las vulnerabilidades, ya sea deshabilitando servicios innecesarios, el cierre de puertos no utilizados, implementación de firewalls y sistemas de detección de intrusos, aplicación de políticas de contraseñas seguras y aplicación periódica de parches y actualizaciones de seguridad. Entre los métodos más recomendables, encontramos los siguientes:
- Aplicar las últimas actualizaciones publicadas por el desarrollador del sistema operativo.
- Habilitar funciones de seguridad integradas (Microsoft Defender o software de plataformas de Protección de Endpoint o EPP, Endpoint Detection Rate o EDR de terceros). Esto realizará una búsqueda de malware en el sistema (caballos de troya, sniffer, capturadores de contraseñas, sistemas de control remoto, etc).
- Eliminar controladores innecesarios y actualizar los que se utilizan.
- Eliminar software instalado en la máquina innecesario.
- Habilitar el arranque seguro.
- Restringir los privilegios de acceso al sistema.
- Usar biometría o autenticación FIDO (Fast Identity Online) además de las contraseñas.
También, se puede implementar una política de contraseñas segura, proteger datos confidenciales con cifrado AES o unidades de autocifrado, tecnologías de resiliencia de firmware y/o autenticación multifactor.
4.Hardening de Servidor
Eliminación de vulnerabilidades (también conocidos como vectores de ataque) que un pirata informático podría utilizar para acceder al servidor. Se centra en asegurar datos, puertos, componentes y funciones del servidor, implementando protocolos de seguridad a nivel de hardware, firmware y software. Se recomienda:
- Parchear y actualizar los sistemas operativos periódicamente.
- Actualizar el software de terceros necesario para ejecutar los servidores de acuerdo con los estándares de seguridad de la industria.
- Exigir a los usuarios crear y mantener contraseñas complejas que consten de letras, números y caracteres especiales, además de actualizar estas contraseñas con frecuencia.
- Bloquear una cuenta después de un número determinado de intentos fallidos de inicio de sesión.
- Desactivar ciertos puertos USB cuando se arranca un servidor.
- Aprovechar la autenticación multifactor (MFA)
- El uso de cifrado AES o unidades autocifradas para ocultar y proteger información crítica para el negocio.
- Utilizar protección antivirus y firewall, así como otras soluciones de seguridad avanzadas.
5.Hardening de red
Protección de la infraestructura de la red y los canales de comunicación. Implica configurar firewalls, implementar sistemas de prevención de intrusiones (IPS) y sistemas de detección de intrusiones (IDS), protocolos de cifrado como SSL/TLS, y segmentar la red para reducir el impacto de una infracción e implementar fuertes controles de acceso a la red. Se recomienda combinar los sistemas IPS y de IDS, además de:
- Configurar adecuadamente los firewalls de red.
- Auditorías de reglas de red y privilegios de acceso.
- Deshabilitar puertos de red y protocolos de red innecesarios.
- Deshabilitar servicios y dispositivos de red no utilizados.
- Cifrar el tráfico de red.
Cabe mencionar que la implementación de mecanismos sólidos de monitorización y registro es esencial para fortalecer nuestro sistema. Implica configurar un registro de eventos de seguridad, monitorizar los registros del sistema en busca de actividades sospechosas, implementar sistemas de detección de intrusiones y realizar auditorías y revisiones de seguridad periódicas para identificar y responder a posibles amenazas de manera oportuna.
Aplicación práctica de Hardening en 9 Pasos
Aun cuando cada organización tiene sus particularidades en los sistemas empresariales, existen tareas de hardening generales y aplicables a la mayoría de los sistemas. A continuación, se muestra una lista de las tareas más importantes a modo de checklist básica:
1. Administrar el acceso: Asegúrate de que el sistema está físicamente seguro y que el personal está informado sobre los procedimientos de seguridad. Configura roles personalizados y contraseñas seguras. Elimina los usuarios innecesarios del sistema operativo y evita el uso de cuentas raíz o de “superadministrador” con privilegios excesivos. También, hay que limitar los permisos de grupos de administradores: sólo otorga privilegios elevados cuando sea necesario.
2. Controlar el tráfico de la red: Instala sistemas reforzados detrás de un firewall o, si es posible, aislados de las redes públicas. Se debe requerir un VPN o proxy inverso para conectarse. También, se deben cifrar las comunicaciones y establecer reglas de firewall para restringir el acceso a rangos de IP conocidos.
3. Aplicar parches en las vulnerabilidades: Mantén actualizados los sistemas operativos, los navegadores y cualquier otra aplicación y aplica todos los parches de seguridad. Se recomienda realizar un seguimiento de los avisos de seguridad de los proveedores y los CVE más recientes.
4. Eliminar el software innecesario: Desinstala cualquier software innecesario y elimina los componentes redundantes del sistema operativo. Hay que desactivar los servicios innecesarios y cualquier componente o función de la aplicación que no sea necesario y que pueda ampliar la superficie de amenazas.
5. Implementa la monitorización continua: Revisa periódicamente los registros para detectar actividades anómalas, con especial atención a las autenticaciones, al acceso de los usuarios y a la escalada de privilegios. Refleja los registros en una ubicación separada para proteger la integridad de los registros y evitar manipulaciones. Realiza análisis periódicos de vulnerabilidades y malware y, si es posible, realiza una auditoría externa o una prueba de penetración.
6. Implementar comunicaciones seguras: Asegura la transferencia de datos mediante cifrados seguros. Cierra todos los puertos de red excepto los esenciales y desactiva protocolos no seguros como SMBv1, Telnet y HTTP.
7. Realizar copias de seguridad periódicas: Los sistemas reforzados son, por definición, recursos sensibles y se les debe realizar copias de seguridad periódicamente utilizando la regla 3-2-1 (tres copias de la copia de seguridad, en dos tipos de medios, con una copia almacenada fuera del sitio).
8. Fortalecer las sesiones remotas: Si debe permitirse Secure Shell o SSH (protocolo de administración remota), asegúrate de que se use una contraseña o certificado seguro. Hay que evitar el puerto predeterminado, además de deshabilitar los privilegios elevados para el acceso SSH. Supervisa los registros SSH para identificar usos anómalos o escalada de privilegios.
9. Monitorizar las métricas importantes para la seguridad: Monitoriza logs, accesos, número de conexiones, carga de servicios (CPU , Memoria) o crecimiento del disco. Todas estas métricas y muchas más son importantes para saber si estás sufriendo un ataque. Tenerlas monitorizadas y conocerlas en tiempo real puede librarte de muchos ataques o degradaciones del servicio.
Hardening en Pandora FMS
Pandora FMS incorpora una serie de funcionalidades específicas para monitorizar el hardening de servidores, tanto Linux como Windows. Para ello, ejecuta un plugin especial que realizará una serie de verificaciones, puntuando si pasa o no el registro. Dichas comprobaciones se programan para que se ejecuten cada cierto tiempo. La interfaz gráfica estructura lo encontrado en diferentes categorías, y se puede analizar visualmente la evolución de la seguridad del sistema a lo largo del tiempo, como una gráfica temporal. Además, se pueden generar informes técnicos detallados de cada máquina, por grupos o realizar comparativas.
Es importante abordar las tareas de securización de los sistemas de una manera metódica y organizada, atendiendo primero a lo más crítico y siendo metódico, para poder hacerlo en todos los sistemas por igual. Uno de los pilares fundamentales de la seguridad informática es el hecho de no dejar grietas, si hay una puerta de entrada, por pequeña que sea, y por más que tengamos securizado el resto de máquinas, puede ser suficiente para tener una intrusión en nuestros sistemas.
El Centro para la Seguridad en Internet (CIS) lidera el desarrollo de normas internacionales de hardening y publica directrices de seguridad para mejorar los controles de ciberseguridad. Pandora FMS utiliza las recomendaciones del CIS para implementar un sistema de auditoría de seguridad, integrado con la monitorización para observar la evolución del hardening en toda tu organización, sistema por sistema.
Utilización de categorías CIS para verificaciones de seguridad
Existen más de 1500 comprobaciones individuales para garantizar la seguridad de los sistemas gestionados por Pandora FMS. A continuación, mencionamos las categorías CIS auditadas por Pandora FMS y algunas recomendaciones:
- Inventario y control de activos hardware y software
Se refiere a todos los dispositivos y software en tu organización. Se recomienda mantener un inventario actualizado de tus activos tecnológicos y usar la autenticación para bloquear los procesos no autorizados.
- Inventario y control de dispositivos
Consiste en identificar y gestionar tus dispositivos de hardware para que solamente los autorizados tengan acceso a los sistemas. Para ello, hay que mantener un inventario adecuado, minimizar riesgos internos, organizar tu entorno y brindar claridad a tu red.
- Gestión de vulnerabilidades
Análisis de los activos de forma continua para detectar vulnerabilidades potenciales y solucionarlas antes de que se conviertan en la entrada a un ataque. Se debe asegurar la actualización de parches y medidas de seguridad en el software y los sistemas operativos.
- Uso controlado de privilegios administrativos
Consiste en la supervisión de los controles de acceso y el comportamiento de los usuarios con cuentas privilegiadas para evitar cualquier acceso no autorizado a sistemas críticos. Se debe asegurar que solamente las personas autorizadas tengan privilegios elevados para evitar cualquier mal uso de los privilegios administrativos.
- Configuración segura de hardware y software
Configuración y mantenimiento de seguridad basadas en estándares aprobados por tu organización. Se debe crear un sistema de gestión de configuraciones riguroso que detecte y alerte sobre cualquier configuración incorrecta, junto con un proceso de control de cambios para evitar que los atacantes se aprovechen de servicios y configuraciones vulnerables.
- Mantenimiento, supervisión y análisis de logs y registros de auditoría
Recopilación, administración y análisis de los logs de auditoría de eventos para identificar posibles anomalías. Se requieren registros detallados para comprender a fondo los ataques y poder responder de manera eficaz a los incidentes de seguridad.
- Defensas contra malware
Supervisión y control de instalación y ejecución de código malicioso en varios puntos de la organización para prevenir ataques. Se debe configurar y usar software antimalware y aprovechar la automatización para garantizar actualizaciones rápidas de defensas y una acción correctiva ágil en caso de ataques.
- Protección del correo electrónico y los navegadores web
Protección y administración de tus navegadores web y sistemas de correo electrónico contra amenazas en línea para reducir la superficie de ataque. Hay que desactivar complementos de correo electrónico no autorizados y asegurarse de que los usuarios solo accedan a sitios web de confianza mediante filtros de URL basados en la red. Recuerda mantener seguras estas puertas de entrada más comunes para los ataques.
- Capacidades de recuperación de datos
Procesos y herramientas para asegurar que la información crítica de tu organización esté respaldada adecuadamente. Asegúrate de contar con un sistema de recuperación de datos confiable para restaurar la información en caso de ataques que pongan en peligro los datos críticos.
- Defensa de límites y protección de datos
Identificación y clasificación de los datos sensibles, junto con una serie de procesos que incluyan la codificación, planes de protección contra la infiltración de datos y técnicas de prevención de pérdida de datos. Establece barreras sólidas para prevenir el acceso no autorizado.
- Supervisión y control de cuentas
Supervisión de todo el ciclo de vida de tus sistemas y cuentas de aplicaciones, desde su creación hasta su eliminación, pasando por su uso e inactividad. Considera que esta gestión activa previene que los atacantes se aprovechen de cuentas de usuarios legítimos pero inactivos para fines maliciosos y permite mantener un control constante sobre las cuentas y sus actividades.
Cabe mencionar que no todas las categorías son aplicables en un sistema, pero existen controles para verificar si se aplican o no. Veamos algunas pantallas a manera de ejemplo de visualización.
Ejemplo de detalle en un control de hardening de un servidor Linux (Debian)
Este control explica que es recomendable desactivar el reenvío de paquetes ICMP, tal como se contempla en las recomendaciones de CIS, PCI_DSS, NIST y TSC.
Ejemplo de listado de chequeos por grupo (en este caso, securización de red)
Ejemplo de controles, por categoría en un servidor:
La separación de los controles por categorías es clave para poder organizar el trabajo y para delimitar el alcance, por ejemplo, habrá sistemas no expuestos a la red donde podremos “ignorar” la categoría de red, o sistemas sin usuarios, donde podemos evitar el control de usuarios.
Ejemplo de evolución del hardening de un sistema a lo largo del tiempo:
Esto nos permite ver la evolución de la securización en un sistema (o en un grupo de sistemas). La securización no es un proceso fácil ya que son docenas de cambios, por lo que es importante abordarlo de una forma gradual, es decir, planificando por etapas la corrección de los mismos, esto debería producir una tendencia a lo largo del tiempo, como la que podemos ver en la imagen adjunta. Pandora FMS es una herramienta útil no solo de auditoría, si no de seguimiento del proceso de securización de los sistemas.
Otras medidas de seguridad adicionales relacionadas con el hardening
- Monitorización de vulnerabilidades permanente. Pandora FMS integra además un sistema de detección de vulnerabilidades continuo, basado en las bases de datos de Mitre (CVE, Common Vulnerabilities and Exposure, vulnerabilidades y exposición comunes) y NIST para poder realizar auditorías de software vulnerable en toda tu organización de manera continuada. Se usan tanto los agentes como el componente remoto Discovery para determinar en cuáles de tus sistemas hay software con vulnerabilidades. Más información aquí.
- Flexibilidad en el inventariado: Ya sea que utilices sistemas Linux de varias distribuciones o cualquier versión de Windows, lo importante es conocer y mapear bien nuestra infraestructura: software instalado, usuarios, rutas, direcciones, IP, hardware, discos, etc. La seguridad no se puede tener si no disponemos de un inventario detallado.
- Monitorización constante de la infraestructura de seguridad: Es importante monitorizar el estado de las infraestructuras específicas de seguridad, como backups, antivirus, VPN, firewalls, IDS/IPS, SIEM, honeypots, sistemas de autenticación, sistemas de almacenamiento, recogida de logs, etc.
- Monitorización permanente de la seguridad en servidores: Verificando en tiempo real la seguridad del acceso remoto, de las contraseñas, de los puertos abiertos y del cambio sobre ficheros clave del sistema.
- Alertas proactivas: No solo es preciso detectar posibles brechas de seguridad, sino que también es necesario ejecutar alertas proactivas y recomendaciones para abordar cualquier problema antes de que se convierta en una amenaza real.
Te invito a ver este video sobre Hardening en Pandora FMS.
Impacto positivo en la seguridad y operatividad
Como hemos visto, el hardening es parte de los esfuerzos para garantizar la continuidad del negocio. Se debe asumir una postura proactiva sobre la protección del servidor, priorizando riesgos identificados en el entorno tecnológico y aplicando cambios de manera gradual y lógica. En forma constante, se deben aplicar los parches y realizar actualizaciones como prioridad, apoyándose en herramientas de monitorización y gestión automatizadas que aseguren la rápida corrección de posibles vulnerabilidades. También se recomienda seguir las mejores prácticas específicas para cada área de hardening con el fin de garantizar la seguridad de toda la infraestructura tecnológica con un enfoque integral.
Recursos Adicionales
Accede a la documentación de Pandora FMS o consulta las referencias a las directrices de seguridad del CIS: ver entrevista a Alexander Twaradze, representante de Pandora FMS ante países que implementan estándares CIS.

por Olivia Díaz | Last updated Mar 4, 2024 | Control Remoto
Desde la computadora, cada vez más realizamos diferentes tareas de forma simultánea (escuchando música mientras escribimos un informe, recibiendo archivos por email y descargando videos), que implican ejecutar comandos, y enviar y recibir datos. Con el tiempo, el rendimiento de los ordenadores puede verse afectado si no se optimiza el uso de la CPU.
Pero, ¿qué es la CPU?
CPU son las siglas de central processing unit o unidad de procesamiento central. En sí, la CPU es el cerebro de un ordenador en la que se realizan la mayoría de los cálculos y procesos. Los dos componentes de una CPU son:
- La unidad lógica aritmética (Arimethic Logic Unit, ALU), que realiza operaciones aritméticas y lógicas.
- La unidad de control (Control Unit, CU), que extrae instrucciones de la memoria, las decodifica y ejecuta, llamando a la ALU cuando es necesario.
En este diagrama podemos ver que en la CPU también se encuentra la unidad de memoria, que contiene los siguientes elementos:
- La ROM (Read Only Memory, memoria de lectura): Es una memoria de sólo lectura; es decir, sólo podremos leer los programas y datos almacenados en ella. También es una unidad de memoria primaria del sistema informático, y contiene algunos fusibles electrónicos que se pueden programar para una información específica. La información es almacenada en ROM en formato binario. También se la conoce como memoria permanente.
- La RAM (Random Access Memory, memoria de acceso aleatorio): Como dice su nombre, es un tipo de memoria de ordenador al que se puede acceder aleatoriamente, a cualquier byte de memoria sin tocar los bytes anteriores. La RAM es un componente de alta velocidad en los dispositivos que almacena temporalmente toda la información que necesita un dispositivo.
- Cache: La memoria caché almacena datos y permite acceder a ellos de manera rápida. La velocidad y capacidad de la memoria caché mejora el desempeño del dispositivo.
Su papel crucial en el funcionamiento de un ordenador
Por sus componentes, la velocidad y el rendimiento de un equipo están directamente relacionados con las características de la CPU, tales como:
- El consumo energético. Hace referencia a la cantidad de energía que consume la CPU al ejecutar acciones, a mayor calidad, mayor consumo energético.
- La frecuencia de reloj. Se refiere a la velocidad de reloj que tiene el CPU y que determina la cantidad de acciones que puede ejecutar en un período de tiempo.
- El número de núcleos. A mayor cantidad de núcleos, mayor la cantidad de acciones que pueden realizarse de forma simultánea.
- El número de hilos. Ayuda al procesador a manejar y ejecutar acciones de forma más eficiente. Divide las tareas o procesos para optimizar los tiempos de espera entre una acción y la otra.
- La memoria caché. Almacena datos y permite acceder a ellos de manera rápida.
- El tipo de bus. Se refiere a la comunicación que establece el CPU con el resto del sistema.
Relación entre velocidad/potencia de la CPU y rendimiento del ordenador
Impacto de la velocidad y potencia en la eficacia del sistema
Las CPU se clasifican por el número de núcleos:
- De un solo núcleo, en el que el procesador sólo puede realizar una acción a la vez, es el procesador más antiguo.
- De dos núcleos, que permite realizar más de una acción a la vez.
- De cuatro núcleos independientes entre sí, lo que les permite realizar varias acciones a la vez y son mucho más eficientes.
Considerando esto, entendemos por qué las CPU actuales tienen dos o más núcleos para poder realizar varias operaciones al mismo tiempo o equilibrar la carga para que el procesador no llegue a estar 100% ocupado, lo que impediría realizar algunas operaciones.
Consecuencias de una CPU lenta o sobrecargada
Cuando una CPU está sobrecargada, las consecuencias son las siguientes, y en el orden indicado:
- Pérdida de rendimiento, alentando el procesamiento de tareas.
- Sobrecalentamiento de la computadora, señal de que los componentes reciben más demanda de la capacidad de la que disponen.
- Si la temperatura de un procesador supera su límite, se ralentiza e incluso puede llevar a un apagado total del sistema.
Con esto, si no queremos llegar a la última consecuencia que ponga en riesgo a nuestros equipos, se debe optimizar la carga de la CPU.
Importancia de reducir el uso de la CPU
Beneficios de optimizar la carga de la CPU
Cuando se minimiza el consumo de CPU, los beneficios son evidentes en:
- Ahorro de energía: Menor consumo de energía, evitando el uso innecesario de recursos del procesador.
- Duración de la batería: Se extiende la vida de la batería al reducir el consumo de energía.
- Mayor rendimiento: Mejoras en el rendimiento en todo momento.
- Menor sobrecalentamiento y agotamiento del procesador.
- Menor impacto ambiental: Con menor consumo de energía se disminuye la huella de carbono de la organización y es posible contribuir a las metas ESG (ambiente, social y gobernabilidad, Environment, Social, Governance).
Supervisión del uso de la CPU en entornos de TI
Rol de los agentes del servicio de soporte de TI
Para dar continuidad al negocio, siempre se necesita supervisión de los sistemas y equipos para asegurar la entrega de los servicios sin interrupciones o eventos que pongan en riesgo a la empresa. Los agentes del servicio de soporte de TI precisamente prestan apoyo presencial o remoto en:
- Instalar y configurar equipos, sistemas operativos, programas y aplicaciones.
- Dar mantenimiento periódico a los equipos y sistemas.
- Apoyar a los empleados sobre el uso o necesidades de tecnología.
- Detectar riesgos y problemas en equipos y sistemas, y emprender acciones para prevenir o corregirlos.
- Realizar diagnósticos sobre el funcionamiento de hardware y software.
- Reemplazar partes (o todo) de los equipos cuando es necesario.
- Realizar y analizar informes sobre el estado de los equipos y sistemas.
- Solicitar las piezas y refacciones, y, de ser posible, planificar inventarios.
- Orientar sobre la ejecución de nuevos equipos, aplicaciones o sistemas operativos.
- Realizar pruebas y evaluar sistemas y equipos antes de su implementación.
- Configurar perfiles y accesos a redes y equipos.
- Realizar revisiones de seguridad en todos los equipos y sistemas.
Herramientas de supervisión y gestión remotas (RMM) para una monitorización efectiva
Para poder llevar a cabo las funciones del agente del servicio de soporte técnico, existen herramientas para la supervisión y gestión en forma remota. Remote Monitoring and Management (RMM, monitoreo y gestión remoto) es un software que ayuda a ejecutar y automatiza tareas de TI como actualizaciones y administración de parches, comprobaciones del estado de los dispositivos y monitorización de la red. El acercamiento de RMM, de gran apoyo para los equipos internos de TI como también para los Proveedores de Servicios Gestionados (MSP), es de centralizar el proceso de gestión de soporte de forma remota, desde rastrear dispositivos, conocer su estado, hasta realizar mantenimientos de rutina y resolver los problemas que surjan en los equipos y sistemas. Esto resulta de valor si consideramos que los servicios y recursos de TI están en ambientes híbridos, sobre todo para soportar la demanda de los usuarios que no solo trabajan en la oficina sino aquellos que están trabajando de forma remota. Hacer un seguimiento o mantenimiento de los recursos en forma manual es literalmente imposible.
Para saber más sobre RMM, visita este post: ¿Qué es el software RMM?
Consejos para reducir el uso de la CPU en Chromebooks y Windows
Cierre de pestañas o aplicaciones innecesarias
Este es uno de los métodos más sencillos para reducir el uso de la CPU. Cierra las pestañas o aplicaciones que no estés utilizando en tu navegador web. Esto libera recursos en tu ordenador, permitiéndote realizar otras tareas.
Para abrir el Administrador de Tareas en un Chromebook, pulsa “Ctrl”+”Mayús”+”T”.
Haz clic con el botón derecho en la barra de tareas de Windows y selecciona “Administrador de tareas”.
En el Administrador de Tareas, cierra las pestañas o aplicaciones que ya no estás usando.
Desactivación de animaciones o efectos no esenciales
Algunas animaciones y efectos pueden consumir grandes recursos de la CPU, por lo que es mejor desactivarlos. Primero ve a la configuración del sistema y busca una opción llamada “Rendimiento” o “Gráficos”, desde la cual puedes desactivar animaciones y efectos.
En Chromebook, ve a Configuración > Avanzado > Rendimiento y desactiva cualquier animación o efecto innecesario.
En Windows, ve a Panel de control > Sistema y seguridad > Rendimiento y desactiva las animaciones o efectos innecesarios.
Actualización de controladores
Los controladores obsoletos pueden degradar el rendimiento del ordenador, provocando un uso excesivo de la CPU. Para actualizar los controladores, visita el sitio web del fabricante de tu ordenador y descarga los controladores más recientes para tu hardware. Instala y luego reinicia el ordenador.
Desfragmentación del disco duro
Con el tiempo, el disco duro puede fragmentarse afectando el rendimiento del ordenador. Abre la herramienta “Desfragmentador de Disco” del menú Inicio para desfragmentarlo. Selecciona “Desfragmentador de disco” en el menú Inicio. Reinicia el ordenador después de desfragmentar el disco duro.
Escaneo de malware
El malware es un software malicioso que pretende provocar daños a los sistemas y equipos. En ocasiones, el malware puede consumir recursos de la CPU, por lo que es fundamental analizar el ordenador y realizar un escaneo de forma regular para encontrar malware. Para ello, utiliza un programa antivirus de confianza. Una vez finalizado el análisis, elimina cualquier malware que se haya detectado.
Restauración del sistema
Si estás experimentando un alto uso de CPU, puedes intentar realizar una restauración del sistema. Puede ser una solución drástica, pero devolverá el ordenador a un estado anterior en el que funcionaba con normalidad. Para ello, abre el menú Inicio y busca “Restaurar sistema”.
Haz clic en el botón “Inicio” y escribe “Restaurar sistema”.
Elige un punto de restauración que se haya creado antes de que empezara a experimentar problemas por el uso elevado de la CPU. Reinicia el ordenador.
Actualización de software
El software obsoleto también causa problemas de rendimiento en tu ordenador, incluyendo un alto uso de la CPU. Para actualizar el software, abre el Panel de control y ve a la configuración de “Windows Update”, Comprueba si hay actualizaciones e instala las que estén disponibles.
Además de estos consejos, se recomienda emplear herramientas RMM y agentes instalados en los ordenadores, servidores, estaciones de trabajo y dispositivos de la compañía, que se se ejecutan en segundo plano con el fin de ir recopilando información sobre la actividad en la red, el rendimiento y la seguridad de los sistemas en tiempo real. Mediante su análisis, es posible detectar patrones y anomalías para generar tickets de soporte (y escalarlos si es necesario según su gravedad) o, lo que es ideal, actuar en forma preventiva.
También, se recomienda la monitorización proactiva, realizada por los equipos de TI internos o por los proveedores MSP, para garantizar un entorno TI estable y seguro para los usuarios. Algo muy importante es que la proactividad reduce los costos asociados a la reparación de equipos y la recuperación de datos.
Optimización avanzada: Overclocking y cambio de CPU
Explicación de opciones avanzadas como overclocking
El overclocking es una técnica utilizada para aumentar la frecuencia de reloj de un componente electrónico, como la CPU (procesador) o la GPU (tarjeta gráfica), más allá de las especificaciones establecidas por el fabricante del equipo. Es decir, el overclocking trata de forzar al componente a funcionar a una velocidad superior a la que originalmente ofrece.
Consideraciones sobre la instalación de una nueva CPU
Aunque pudiera parecer una cuestión sencilla la instalación de una nueva CPU, existen consideraciones para instalar una nueva CPU para asegurar el rendimiento de tu ordenador. Se recomienda tener a la mano lo siguiente:
- Un destornillador: Dependiendo de tu PC y del contenido que esté instalado en él, es posible que necesites uno o más destornilladores para quitar los tornillos de tu CPU e incluso de la placa base, en el caso de que necesites quitarla.
- Pasta térmica: Esto es imprescindible al instalar una nueva CPU, especialmente si no se tiene un enfriador de CPU con pasta térmica previamente aplicada.
- Toallitas con alcohol isopropílico: Las necesitarás para limpiar la pasta térmica residual del procesador y el punto de contacto del enfriador de la CPU. Incluso puedes usar alcohol isopropílico junto con unas toallas de papel muy absorbentes.
- Muñequera antiestática: Dado que se trabajará con componentes frágiles y costosos como la CPU, la placa base y el enfriador, te sugerimos usar una pulsera antiestática para proteger los componentes de las descargas estáticas.
Con esto a mano, ahora sí te hacemos saber tres consideraciones importantes:
- Toma precauciones estáticas:
La CPU es sensible a las descargas estáticas. Sus pins son delicados y trabajan a altas temperaturas, por lo que hay que tomar precauciones. Se recomienda usar una pulsera antiestática o tomar una superficie metálica para “descargarte”. En caso de que la CPU se haya utilizado en otra máquina o si se está reemplazando el ventilador, es posible que debas quitar el compuesto térmico antiguo con alcohol isopropílico (no en los contactos de la CPU). No es necesario retirar la batería de la placa base durante la instalación de la CPU. Esto provocaría que se pierdan las configuraciones guardadas de la BIOS. Se debe necesitar una fuerza mínima para bloquear la palanca de carga de la CPU en su lugar.
- Compatibilidad de la placa base:
Es importante verificar la documentación de tu placa base para conocer el tipo de socket que se utiliza. Recuerda que AMD e Intel emplean diferentes sockets, por lo que no puedes instalar un procesador de Intel en una placa AMD (y viceversa). En caso de no hallar esta información, puedes usar el programa CPU-Z para determinar el tipo de socket que debes usar.
- Ubicación y alineación correctas:
Se debe colocar la CPU en el socket de manera adecuada. Si no lo haces correctamente, la CPU no funcionará. Debes asegurarte de instalar correctamente el ventilador y disipador térmico para evitar problemas de temperatura.
En resumen
La demanda de recursos en nuestras computadoras para poder procesar diversas tareas simultáneamente ha dejado claro por qué se debe prestar atención al uso de la CPU con velocidad y potencia. Por esa razón, las herramientas de supervisión y gestión remotas son un recurso para los empleados de TI (o el Proveedor de Servicios Gestionados) con el fin de poder conocer desde un punto central el estado de los sistemas y equipos y emprender acciones de mantenimiento y prevención en forma remota, tales como actualización de controladores, escaneo de malware, actualización de software, entre otros. Los resultados de estos esfuerzos serán el ahorro de energía, un mayor rendimiento y la extensión de la vida de la batería, junto con un menor sobrecalentamiento del procesador y la reducción del impacto ambiental.

por Pandora FMS team | Last updated Mar 7, 2024 | Pandora FMS
Collectd es un demonio (i.e. que se ejecuta en segundo plano en equipos y dispositivos) que recopila periódicamente métricas desde diversas fuentes como sistemas operativos, aplicaciones, archivos de registro y dispositivos externos, proporcionando mecanismos para almacenar los valores de diversas formas (ej. archivos RRD) o la pone a disposición a través de la red. Con estos datos y sus estadísticas se puede monitorizar sistemas, hallar cuellos de botella en el rendimiento (por análisis de rendimiento) y predecir la carga del sistema (planificación de capacidad).
Lenguaje de programación y compatibilidad con sistemas operativos
Collectd está escrito en C para sistemas operativos *nix; es decir, basados en Unix, como BSD, macOS y Linux, para su portabilidad y desempeño, ya que su diseño permite ejecutarse en sistemas sin lenguaje de secuencias de comandos (scripting language) o demonio cron, como sistemas integrados. Para Windows puede conectarse mediante Cygwin (herramientas GNU y de código abierto que brindan una funcionalidad similar a una distribución de Linux en Windows).
También, Collectd se ha optimizado para consumir la menor cantidad de recursos del sistema, lo que lo cualifica como una gran herramienta para monitorizar el rendimiento con un bajo costo.
Plug-ins de collectd
Collectd como un Demonio Modular
El sistema collectd es modular. En su core tiene funcionalidades limitadas y para usarlo, es necesario saber cómo compilar un programa en C. También se necesita saber cómo iniciar el ejecutable de la manera correcta para que los datos se envíen a donde se necesitan. Sin embargo, a través de los plug-ins, se obtiene valor de los datos recolectados y enviados, extendiendo su funcionalidad para varios casos de uso. Esto hace que el demonio sea modular y flexible y que las estadísticas obtenidas (y su formato) se pueden definir por plug-ins.
Tipos de plug-ins
Actualmente, existen 171 plug-ins disponibles para collectd. No todos los plug-ins definen temas de recopilación de datos, ya que algunos extienden las capacidades con interfaces para tecnologías específicas (ej. lenguaje de programación como Python).
- Los plug-ins de lectura obtienen datos y se clasifican generalmente en tres categorías:
- Plug-ins del sistema operativo, que recopilan información como el uso de CPU, la memoria o la cantidad de usuarios que iniciaron sesión en un sistema. Por lo general, estos plug-ins deben trasladarse a cada sistema operativo.
- Plug-ins de aplicaciones, que recopilan datos de rendimiento sobre una aplicación que se ejecuta en la misma computadora o en un sitio remoto. Estos plug-ins suelen utilizar bibliotecas de software, pero por lo demás suelen ser independientes del sistema operativo.
- Plug-ins genéricos, que ofrecen funciones básicas que el usuario puede emplear para tareas específicas. Algunos ejemplos son la consulta para monitorización de redes (desde SNMP) o la ejecución de programas o scripts personalizados.
- Los plug-ins de escritura ofrecen la posibilidad de almacenar los datos recopilados en el disco utilizando archivos RRD o CSV; o bien, enviar datos a través de la red a una instancia remota del demonio.
- Los plug-ins unixsock permiten abrir un socket para conectarnos con el demonio de collectd. Gracias a la utilidad collectd podemos obtener directamente los monitores en nuestra terminal con los parámetros getval o listval, donde podemos indicar el parámetro que queremos obtener en concreto u obtener una lista con todos los parámetros que ha recolectado collectd.
- También tenemos el plug-in de red, que se usa para enviar y recibir datos hacia y desde otras instancias del demonio. En una configuración de red típica, el demonio se ejecutaría en cada host monitoreado (llamado “clientes”) con el plug-in de red configurado para enviar los datos recopilados a una o más direcciones de red. En uno o más de los llamados “servidores”, se ejecutaría el mismo demonio, pero con una configuración diferente, de modo que el plug-in de red reciba datos en lugar de enviarlos. A menudo, el complemento RRDtool se utiliza en servidores para almacenar los datos de rendimiento (ej. ancho de banda, temperatura, carga de trabajo en el CPU, etc.)
TIP de collectd en Pandora FMS: Se pueden activar y desactivar los plug-ins que se tienen desde el fichero de configuración “collectd.conf”, además de configurarlos o añadir plugins personalizados.
Beneficios de collectd
- Naturaleza de código abierto
Collectd es un software de código abierto, al igual que sus plug-ins, aunque, algunos plug-ins no tienen la misma licencia de código abierto.
- Extensibilidad y modularidad
Collectd tiene 171 plug-ins, es compatible con una diversidad de sistemas operativos y es muy fácil de configurar. También permite la personalización según la necesidad de la empresa y su funcionalidad puede extenderse fácilmente agregando algunos plug-ins confiables, además de poder escribirse en varios lenguajes como Perl y Python.
- Escalabilidad
Collectd recopila datos de muchas fuentes y los envía a un grupo o servidor de multidifusión. Ya sean uno o mil hosts, collectd puede recopilar estadísticas y métricas de rendimiento. También collectd permite fusionar múltiples actualizaciones en una sola operación o valores grandes en un solo paquete de red.
- Soporte SNMP
Collectd admite el protocolo simple de administración de red (Simple Network Management Protocol, SNMP), lo que permite a los usuarios recopilar métricas de una amplia gama de recursos y dispositivos de red.
- Flexibilidad
Brinda flexibilidad y la oportunidad de decidir qué estadísticas se desea recopilar y con qué frecuencia.
Integración de collectd con Pandora FMS
Monitorización de entornos de TI
Collectd proporciona estadísticas a un paquete de interpretación, por lo que en herramienta de terceros debe configurarse para generar gráficos y análisis a partir de los datos obtenidos, con el fin de visualizar y optimizar la monitorización de entornos de TI. Hoy, Collectd cuenta con una gran comunidad que contribuye con mejoras, nuevos plug-ins y correcciones de errores.
Ejecución efectiva en Pandora FMS.
El plugin pandora_collectd permite recolectar información generada por el propio collectd y mandarla a nuestro servidor de Pandora FMS para su posterior tratamiento y almacenamiento.
La ejecución de nuestro plugin genera un agente con toda la información de collectd transformada en los módulos de Pandora FMS; con ello, podremos tener cualquier dispositivo monitorizado con collectd y obtener un histórico de datos, crear informes, dashboards, consolas visuales, disparar alertas y un largo etcétera.
Una característica importante de “pandora_collectd” es que es un plug-in muy versátil, ya que nos permite tratar los datos recolectados de collectd antes de mandarlos a nuestro servidor de Pandora FMS. Mediante expresiones regulares, nos permite decidir, según las características que tengamos, qué métricas queremos recolectar y cuáles queremos descartar para enviar las métricas deseadas a nuestro servidor de Pandora FMS de una manera óptima. Además, nos permite modificar parámetros como el puerto o la dirección IP del servidor que queremos usar.
También, es posible personalizar cómo queremos que se llame nuestro agente, donde se crearán los módulos, y modificar su descripción.
Otro aspecto importante de este plug-in es que se puede ejecutar tanto como plug-in de agente como en calidad de plug-in de servidor. Al poder modificar los agentes resultantes de la monitorización, podremos diferenciar fácilmente unos de otros y monitorizar gran cantidad de dispositivos en nuestro entorno de Pandora FMS,
Además, nuestro plugin es compatible con la inmensa mayoría de dispositivos Linux y Unix por lo que no habrá problemas con su implementación con collectd.
Para saber cómo configurar collectd en Pandora FMS, visita Pandora FMS Guides para más detalles.
Collectd vs StatsD: Una Comparación
Diferencias Clave
Como hemos visto, collectd es adecuado para monitorizar CPU, red, uso de memoria y varios complementos para servicios específicos como NGinx. Por sus características, recopila métricas listas para usar y debe instalarse en máquinas que necesitan monitorización.
Mientras que StatsD (escrito en Node.js) se utiliza generalmente para aplicaciones que requieren agregar datos de forma precisa y envía datos a los servidores en intervalos regulares. También, StatsD proporciona bibliotecas en varios lenguajes de programación para facilitar el seguimiento de datos.
Con esto entendido, collectd es un demonio de recopilación de estadísticas, mientras que StatsD es un servicio de agregación o contador de eventos. La razón de explicar sus diferencias es que collectd y StatsD pueden utilizarse juntos (y es una práctica común) dependiendo de las necesidades de monitorización en la organización.
Casos de uso y enfoques
- Casos de uso de StatsD:
- Monitorización de aplicaciones web: Rastreo del número de solicitudes, errores, tiempos de respuesta, etc.
- Análisis de rendimiento: Identificación de cuellos de botella y optimización del rendimiento de la aplicación.
- Casos de uso de collectd:
- Monitoreo de recursos de hardware como uso de CPU, memoria utilizada, uso del disco duro, etc.
- Monitorización sobre métricas específicas de servicios de TI disponibles.
Importancia de collectd en la integración con Pandora FMS
-
- Ligero y eficiente
Collectd en Pandora FMS es ligero y eficiente, con la capacidad de escribir métricas a través de la red, por su misma una arquitectura modular y porque se ejecuta principalmente en la memoria.
- Versatilidad y flexibilidad
Este plug-in permite decidir qué métricas queremos recolectar y cuáles descartar para enviar sólo las métricas que queramos a nuestro servidor de Pandora FMS. También permite ajustar los datos recolectados cada determinado tiempo, según las necesidades de la organización.
- Soporte comunitario y mejoras continuas
Además de que collectd es un plug-in popular, cuenta con el soporte comunitario quienes constantemente realizan mejoras, incluyendo documentación especializada y guías de instalación.
Todo esto nos hace comprender por qué collectd ha sido ampliamente adoptado para la monitorización de los recursos y servicios de TI.
Conclusión
Collectd es un demonio bastante popular para medir métricas desde diversas fuentes como sistemas operativos, aplicaciones, archivos de registro y dispositivos externos, pudiendo aprovechar la información para la monitorización de sistemas. Dentro de sus características clave podemos mencionar que, al estar escrito en C, en código abierto, puede ejecutarse en los sistemas sin necesidad de un lenguaje de secuencias de comandos. Al ser modular, es bastante portable a través de plug-ins y se obtiene el valor de los datos recolectados y enviados, la funcionalidad de collectd se extiende para dar un mejor uso en la monitorización de los recursos de TI. También es escalable, ya sean uno o mil hosts, para recopilar estadísticas y métricas de rendimiento. Esto es de sumo valor en los ecosistemas de TI que siguen extendiéndose para cualquier empresa en cualquier industria.
El plugin pandora_collectd recolecta información generada por el propio collectd y la envía al servidor de Pandora FMS, desde el cual se puede potenciar la monitorización de cualquier dispositivo monitorizado y obtener datos desde los cuales generar reportes o dashboards de productividad, programar alertas y obtener información histórica para la planeación de la capacidad, entre otras funciones de alto valor en la gestión de TI.
Para un mejor aprovechamiento de collectd, con la capacidad de ser tan granular en la recopilación de datos, también es bueno consolidar estadísticas para hacerlos más comprensibles para el ojo humano y simplificar las cosas para el administrador del sistema que analiza los datos. También, se recomienda apoyarse en expertos en monitorización de TI como Pandora FMS, con mejores prácticas de monitorización y observabilidad. Contacta a nuestros expertos en Professional services | Pandora FMS

por Ahinóam Rodríguez | Last updated Feb 23, 2024 | Pandora FMS
Hasta hace poco tiempo el modelo que se utilizaba por defecto para el desarrollo de aplicaciones era SQL. Sin embargo, en los últimos años NoSQL se ha convertido en una alternativa popular.
La gran variedad de datos que se almacenan hoy en día y la carga de trabajo que deben soportar los servidores obligan a los desarrolladores a tomar en cuenta otras opciones más flexibles y escalables. Las bases de datos NoSQL proporcionan un desarrollo ágil y facilidad para adaptarse a los cambios. Aún así, no pueden considerarse como un reemplazo de SQL ni son la elección más acertada para todo tipo de proyectos.
Elegir entre NoSQL vs SQL es una decisión importante, si queremos evitar que aparezcan dificultades técnicas durante el desarrollo de una aplicación. En este artículo nos proponemos explorar las diferencias entre estos dos sistemas de gestión de bases de datos y orientar al lector sobre el uso de cada uno de ellos, teniendo en cuenta las necesidades del proyecto y el tipo de datos que se van a manejar.
¿Qué es NoSQL?
El término NoSQL es la abreviatura de “Not only SQL” y se refiere a una categoría de DBMS que no utilizan SQL como lenguaje de consulta principal.
El boom de las BBDD NoSQL se inició en el año 2.000, coincidiendo con la llegada de la web 2.0. A partir de entonces las aplicaciones se volvieron más interactivas y comenzaron a manejar grandes volúmenes de datos, muchas veces no estructurados. Pronto las bases de datos tradicionales se quedaron cortas en cuanto a rendimiento y escalabilidad.
Las grandes empresas tecnológicas de la época decidieron buscar soluciones para abordar sus necesidades específicas. Google fue la primera en lanzar un DBMS distribuido y altamente escalable: BigTable, en el año 2005. Dos años después, Amazon anunció el lanzamiento de Dynamo DB (2007). Estas BBDD (y otras que fueron apareciendo) no utilizaban tablas ni un lenguaje estructurado, así que eran mucho más veloces en el procesamiento de datos.
Actualmente, el enfoque NoSQL se ha vuelto muy popular debido al auge del Big Data y de los dispositivos IoT, que generan enormes cantidades de datos, tanto estructurados como no estructurados.
Gracias a su rendimiento y capacidad de manejar diferentes tipos de datos, NoSQL logró superar muchas limitaciones presentes en el modelo relacional. Netflix, Meta, Amazon o LinkedIn son ejemplos de aplicaciones modernas que utilizan BBDD NoSQL para gestionar información estructurada (transacciones y pagos), así como no estructurada (comentarios, recomendaciones de contenido y perfiles de usuario).
Diferencia entre NoSQL y SQL
NoSQL y SQL son dos sistemas de gestión de bases de datos (DBMS) que se diferencian en la forma de almacenar, acceder y modificar la información.
El sistema SQL
SQL sigue el modelo relacional, formulado por E.F. Codd en 1970. Este científico inglés propuso sustituir el sistema jerárquico que utilizaban los programadores de la época por un modelo en el que los datos se almacenan en tablas y se relacionan entre sí mediante un atributo común conocido como “clave primaria”. Basándose en sus ideas, IBM creó SQL (Structured Query Language), el primer lenguaje diseñado específicamente para bases de datos relacionales. La compañía intentó sin éxito desarrollar su propio RDBMS, así que hubo que esperar a 1979, año del lanzamiento de Oracle DB.
Las bases de datos relacionales resultaron ser mucho más flexibles que los sistemas jerárquicos y resolvieron el problema de la redundancia, siguiendo un proceso conocido como “normalización” que permite a los desarrolladores expandir o modificar las BBDD sin tener que cambiar toda su estructura. Por ejemplo, una función importante en SQL es JOIN, la cual permite a los desarrolladores realizar consultas complejas y combinar datos de diferentes tablas para su análisis.
El sistema NoSQL
Las bases de datos NoSQL son todavía más flexibles que las relacionales ya que no tienen una estructura fija. En su lugar emplean una amplia variedad de modelos optimizados para los requisitos específicos de los datos que almacenan: hojas de cálculo, documentos de texto, emails, publicaciones en redes sociales, etc.
Algunos modelos de datos que utiliza NoSQL son:
- Clave-valor: Redis, Amazon DynamoDB, Riak. Organizan los datos en parejas de clave y valor. Son muy rápidas y escalables.
- Documentales: MongoDB, Couchbase, CouchDB. Organizan los datos en documentos, normalmente de formato JSON.
- Orientadas a grafos: Amazon Neptune, InfiniteGraph. Usan estructuras de grafos para realizar consultas semánticas y representan datos como nodos, bordes y propiedades.
- Orientadas a columnas: Apache Cassandra. Están diseñadas para almacenar datos en columnas en lugar de filas como ocurre en SQL. Las columnas se organizan de manera contigua para mejorar la velocidad de lectura y permitir una recuperación eficiente del subconjunto de datos.
- Bases de datos en memoria: Eliminan la necesidad de acceder a los discos. Se utilizan en aplicaciones que requieren tiempos de respuesta de microsegundos o que tienen picos altos de tráfico.
En resumen, para trabajar con bases de datos SQL los desarrolladores deben declarar antes la estructura y los tipos de datos que utilizarán. Por el contrario, NoSQL es un modelo de almacenamiento abierto que permite incorporar nuevos tipos de datos sin que esto implique la reestructuración del proyecto.
Base de datos relacional vs. no relacional
Para elegir entre un sistema de gestión de bases de datos SQL o NoSQL debemos estudiar detenidamente las ventajas e inconvenientes de cada uno de ellos.
Ventajas de las bases de datos relacionales
- Integridad de los datos: Las BBDD SQL aplican una gran variedad de restricciones con el fin de garantizar que la información almacenada sea precisa, completa y confiable en todo momento.
- Posibilidad de realizar consultas complejas: SQL ofrece a los programadores una gran variedad de funciones que les permiten realizar consultas complejas que involucran múltiples condiciones o subconsultas.
- Soporte: Los RDBMS existen desde hace décadas; han sido ampliamente probados y cuentan con documentación detallada y completa que describe sus funciones.
Desventajas de las bases de datos relacionales
- Dificultad para manejar datos no estructurados: Las BBDD SQL han sido diseñadas para almacenar datos estructurados en una tabla relacional. Esto significa que pueden tener dificultades a la hora de manejar datos no estructurados o semi-estructurados como documentos JSON o XML.
- Rendimiento limitado: No están optimizadas para realizar consultas complejas y rápidas en grandes conjuntos de datos. Esto puede resultar en tiempos de respuesta prolongados y periodos de latencia.
- Mayor inversión: Trabajar con SQL supone asumir el coste de las licencias. Además, las bases de datos relacionales escalan verticalmente, lo que implica que a medida que un proyecto crece es necesario invertir en servidores más potentes y con más memoria RAM para aumentar la carga de trabajo.
Ventajas de las bases de datos no relacionales
- Flexibilidad: Las BBDD NoSQL permiten almacenar y gestionar datos estructurados, semi-estructurados y no estructurados. Los desarrolladores pueden cambiar el modelo de datos de forma ágil o trabajar con diferentes esquemas según las necesidades del proyecto.
- Alto rendimiento: Están optimizadas para realizar consultas rápidas y trabajar con grandes volúmenes de datos en contextos donde las BBDD relacionales encuentran limitaciones. Un paradigma de programación muy utilizado en bases de datos NoSQL como MongoDB es “MapReduce” que permite a los desarrolladores procesar enormes cantidades de datos en lotes, dividiéndolos en fragmentos más pequeños en diferentes nodos del clúster para analizarlos después.
- Disponibilidad: NoSQL utiliza una arquitectura distribuida. La información se replica en diferentes servidores remotos o locales para garantizar que siempre estará disponible.
- Evitan los cuellos de botella: En las BBDD relacionales, cada sentencia necesita ser analizada y optimizada antes de ejecutarse. Si hay muchas peticiones a la vez, puede producirse un cuello de botella, lo que limita la capacidad del sistema para seguir procesando solicitudes nuevas. En cambio, las bases de datos NoSQL distribuyen la carga de trabajo en varios nodos del clúster. Al no haber un único punto de entrada para las consultas, la posibilidad de que se produzcan cuellos de botella es muy escasa.
- Mayor rentabilidad: NoSQL ofrece una escalabilidad rápida y horizontal gracias a su arquitectura distribuida. En lugar de invertir en servidores caros, se añaden más nodos al clúster para ampliar la capacidad de procesamiento de datos. Además, muchas BBDD NoSQL son de código abierto lo que permite ahorrar los costes en licencias.
Desventajas de las bases de datos NoSQL
- Limitación a la hora de realizar consultas complejas: Las BBDD NoSQL carecen de un lenguaje de consulta estándar y pueden tener dificultades a la hora de realizar consultas complejas o que requieren la combinación de múltiples conjuntos de datos.
- Menor coherencia: NoSQL flexibiliza algunas de las restricciones de coherencia de las BBDD relacionales para lograr mayor rendimiento y escalabilidad.
- Menos recursos y documentación: Aunque NoSQL está en constante crecimiento, la documentación disponible es poca en comparación con la de las bases de datos relacionales que llevan más años en funcionamiento.
- Mantenimiento complejo: Algunos sistemas NoSQL pueden requerir un mantenimiento complejo por su arquitectura distribuida y a la variedad de configuraciones. Esto implica optimizar la distribución de los datos, equilibrar la carga o resolver problemas de red.
¿Cuándo utilizar bases de datos SQL y cuándo usar NoSQL?
La decisión de utilizar una base de datos relacional o una no relacional dependerá del contexto. Primero, debemos estudiar los requisitos técnicos de la aplicación como la cantidad y el tipo de datos que se van a utilizar.
En líneas generales, se recomienda utilizar bases de datos SQL en los siguientes casos:
- Si vamos a trabajar con estructuras de datos bien definidas, por ejemplo, un CRM o un sistema de gestión de inventario.
- Si estamos desarrollando aplicaciones empresariales donde la integridad de los datos es lo más importante: programas de contabilidad, sistemas bancarios, etc.
En cambio, NoSQL es la opción más interesante en estas situaciones:
- Si vamos a trabajar con datos no estructurados o semi-estructurados como documentos JSON o XML.
- Si necesitamos crear aplicaciones que procesan datos en tiempo real y requieren baja latencia, por ejemplo, juegos online.
- Cuando queremos almacenar, gestionar y analizar grandes volúmenes de datos en entornos de Big Data. En estos casos las BBDD NoSQL nos ofrecen escalabilidad horizontal y la posibilidad de distribuir la carga de trabajo en múltiples servidores.
- Cuando vamos a lanzar un prototipo de una aplicación NoSQL nos proporciona un desarrollo rápido y ágil.
En la mayoría de los casos, los desarrolladores back-end deciden utilizar una base de datos relacional, a menos que no sea factible porque la aplicación maneja una gran cantidad de datos desnormalizados o tiene necesidades de rendimiento muy elevadas.
En algunos casos es posible adoptar un enfoque híbrido y utilizar ambos tipos de bases de datos.
Comparación de SQL vs NoSQL
El CTO Mark Smallcombe publicó un artículo titulado “SQL vs NoSQL: 5 Critical Differences” donde detalla las diferencias entre estos dos DBMS.
A continuación, presentamos un resumen de los puntos esenciales de su artículo, junto con otras consideraciones importantes en la comparación de SQL vs NoSQL.
Forma de almacenar los datos
En las BBDD relacionales los datos se organizan en un conjunto de tablas formalmente descritas y se relacionan entre sí mediante identificadores comunes que facilitan el acceso, consulta y modificación.
Las BBDD NoSQL almacenan los datos en su formato original. No tienen una estructura predefinida y pueden utilizar documentos, columnas, grafos o un esquema clave-valor.
Lenguaje
Las BBDD relacionales utilizan el lenguaje de consulta estructurado SQL.
Las BBDD no relacionales tienen sus propios lenguajes de consulta y APIs. Por ejemplo, MongoDB utiliza MongoDB Query Language (MQL) que es similar a JSON y Cassandra utiliza Cassandra Query Language (CQL) que se parece a SQL, pero está optimizado para trabajar con datos en columnas.
Cumplimiento de las propiedades ACID
Las BBDD relacionales siguen las directrices ACID (atomicity, consistency, isolation, durability) que garantizan la integridad y validez de los datos, aunque se presenten errores inesperados. Adoptar el enfoque ACID es una prioridad en las aplicaciones que manejan datos críticos, pero tiene un coste en cuanto a rendimiento ya que los datos deben escribirse en disco antes de ser accesibles.
Las BBDD NoSQL optan en su lugar por el modelo BASE (basic availability, soft state, eventual consistency), que prioriza el rendimiento frente a la integridad de los datos. Un concepto clave es el de “consistencia eventual”. En vez de esperar a que los datos se escriban en disco, se tolera cierto grado de inconsistencia temporal asumiendo que, aunque pueda haber un retraso en la propagación de los cambios, una vez finalizada la operación de escritura todos los nodos tendrán la misma versión de los datos. Este enfoque garantiza mayor rapidez en el procesamiento de datos y es ideal en aplicaciones donde el rendimiento es más importante que la coherencia.
Escalabilidad vertical u horizontal
Las BBDD relacionales escalan verticalmente aumentando la potencia del servidor.
Las BBDD no relacionales tienen una arquitectura distribuida y escalan de manera horizontal añadiendo servidores al clúster. Esta característica hace que NoSQL sea una opción más sostenible para el desarrollo de aplicaciones que gestionan un gran volumen de datos.
Flexibilidad y capacidad de adaptación a los cambios
Las BBDD SQL siguen esquemas rígidos de programación y requieren una planificación detallada ya que los cambios posteriores suelen ser difíciles de implementar.
Las BBDD NoSQL proporcionan un modelo de desarrollo más flexible, lo que permite una adaptación sencilla a los cambios sin tener que realizar migraciones complejas. Son una opción práctica en entornos ágiles donde los requisitos cambian con frecuencia.
Papel de Pandora FMS en la gestión de bases de datos
Pandora FMS proporciona a los equipos TI capacidades avanzadas para monitorear bases de datos SQL y NoSQL, incluyendo MySQL, PostgreSQL, Oracle y MongoDB, entre otras. Además, es compatible con entornos de virtualización y Cloud Computing (por ejemplo, Azure) para gestionar eficazmente servicios y aplicaciones en la nube.
Algunos ejemplos prácticos del uso de Pandora FMS en bases de datos SQL y NoSQL:
- Optimiza la distribución de los datos en NoSQL: Supervisa el rendimiento y la carga de trabajo en los nodos del clúster evitando sobrecargas en nodos individuales.
- Garantiza la disponibilidad de los datos: Replica la información en diferentes nodos minimizando así el riesgo de pérdidas.
- Envía alertas de rendimiento: Monitorea los recursos del servidor y envía alertas a los administradores cuando detecta errores de consulta o tiempos de respuesta lentos. Esto es especialmente útil en las BBDD SQL cuyo rendimiento depende de la potencia del servidor donde se almacenan los datos.
- Favorece la escalabilidad: Permite agregar o eliminar nodos del clúster y ajustar los requerimientos del sistema a la carga de trabajo en aplicaciones que funcionan con BBDD NoSQL.
- Reduce la latencia: Ayuda a los administradores a identificar y solucionar problemas de latencia en aplicaciones que trabajan con datos en tiempo real. Por ejemplo, permite ajustar configuraciones de las BBDD NoSQL, como el número de conexiones simultáneas o el tamaño del búfer de red, mejorando así la rapidez de las consultas.
Conclusión
Hacer una elección correcta del tipo de base de datos es clave para que no surjan contratiempos durante el desarrollo de un proyecto y ampliar las posibilidades de crecimiento en un futuro.
Históricamente, las BBDD SQL fueron la piedra angular de la programación de aplicaciones, pero la evolución de Internet y la necesidad de almacenar grandes cantidades de datos estructurados y no estructurados, empujaron a los desarrolladores a buscar alternativas fuera del modelo relacional. Las bases de datos NoSQL destacan por su flexibilidad y rendimiento, aunque no son una buena alternativa en entornos donde la integridad de los datos es lo primordial.
Es importante tomarse un tiempo para estudiar las ventajas e inconvenientes de estos dos DBMS. Además, debemos comprender que tanto las bases de datos SQL como NoSQL requieren un mantenimiento continuo para optimizar su rendimiento.
Pandora FMS proporciona a los administradores las herramientas necesarias para mejorar el funcionamiento de cualquier tipo de base de datos, haciendo que las aplicaciones sean más rápidas y seguras, lo que se traduce en una buena experiencia para los usuarios.

por Pandora FMS team | Last updated Feb 16, 2024 | Pandora FMS
Entrevista a Alexander Twaradze, representante de Pandora FMS en los países de la CEI.
Ver original aquí.
La infraestructura de TI moderna de la compañía se compone de varios sistemas y servicios. Estos son servidores, equipos de red, software, canales de comunicación, servicios de terceros. Todos ellos se comunican a través de múltiples canales y protocolos. Monitorizar el funcionamiento de toda la infraestructura de TI es una tarea compleja que lleva mucho tiempo. En caso de error, podría enfrentarse a comentarios negativos de clientes, perder dinero y reputación, perder tiempo y causar estrés. El desafío es descubrir rápidamente el origen y la causa del fallo. Es necesario que el sistema de monitorización también permita automatizar la respuesta a fallos, por ejemplo, reiniciar el sistema, elevar el canal de comunicación de backup o agregar recursos al servidor virtual. Al mismo tiempo, es necesario que dicho sistema admita toda la variedad de sistemas y fabricantes que haya en la empresa. Hemos hablado con el director de la compañía, representante de Pandora FMS en los países de la CEI, Alexander Twaradze, acerca de cómo el software Pandora FMS ayuda a resolver este difícil problema.
Cuéntanos sobre Pandora FMS.
La sede central de Pandora FMS se encuentra en Madrid. La compañía ha estado en el mercado durante más de 15 años y actualmente ofrece tres productos principales:
Sistema de monitorización de infraestructura de TI;
Helpdesk, sistema de tickets de soporte;
Sistema de administración remota de servidores.
La compañía opera con éxito en el mercado internacional, y entre sus clientes hay un gran número de empresas del sector público y privado en Europa y Oriente medio, incluidos Viber, MCM Telecom, telefónica y otros.
¿Qué le aporta a una empresa la monitorización de la infraestructura de TI y qué importancia tiene?
Ahora el negocio está relacionado de una manera u otra con TI, por lo que el rendimiento de los servidores, servicios, redes y estaciones de trabajo afecta directamente a la empresa. Por ejemplo, las interrupciones en los centros de procesamiento pueden afectar los pagos de muchas empresas y servicios. El monitoreo de sistemas y servicios ayuda a resolver varios problemas a la vez:
- Realizar un seguimiento de los parámetros de hardware y servicios de antemano, toma medidas para resolver un problema potencial. Por ejemplo, Pandora FMS puede rastrear el nivel de consumo de memoria y advertir a los administradores de antemano que la memoria libre es insuficiente y que el Servicio puede detenerse.
- Comprender rápidamente dónde se produjo el error. Por ejemplo, la empresa tiene integración con el Servicio bancario a través de una API. Pandora FMS no solo puede rastrear que el canal de comunicación esté funcionando y tenga acceso al servidor, sino también que el Servicio bancario no responde correctamente a los comandos de la API.
- Realizar acciones para prevenir el problema. Por ejemplo, una organización tiene un servidor de informes. El pico de carga cae al final de la semana, y cuando el servidor está sobrecargado, esto causa problemas en la experiencia del usuario. Pandora FMS puede monitorizar la carga actual del servidor. Una vez que supera un cierto umbral, Pandora FMS ejecuta un servidor más potente en paralelo, migrando los servicios a este. Cuando pasa el pico de carga, Pandora FMS migra de nuevo al servidor estándar, mientras que el más potente se apaga.
Para realizar tales capacidades, el sistema debe ser capaz de ser flexible y trabajar con diferentes servicios y sistemas…
Es así, y Pandora FMS lo sabe. El sistema funciona con una variedad de fabricantes de hardware de red y servidor, tanto marcas conocidas como otras que no lo son tanto. Si aparece un hardware específico, basta con cargar su archivo MIB y especificar qué parámetros deben monitorizarse. Por ejemplo, nuestro socio en Arabia Saudí ahora está implementando un proyecto con una de las principales empresas estatales. Tienen un gran “zoológico” de sistemas de varios fabricantes, que incluye dispositivos de hace 10 años y soluciones modernas.
Pandora FMS es capaz de monitorizar una variedad de software: sistemas operativos, servidores web, bases de datos, contenedores, estibadores, sistemas de virtualización. Además, Pandora FMS es una solución certificada para la monitorización de SAP R/ 3, s/3, CRM, etc., incluida la monitorización de bases de datos SAP HANA.
El sistema tiene un alto grado de flexibilidad. En uno de los proyectos en la CEI, el cliente necesitaba monitorizar los parámetros de un equipo satelital especial. Al mismo tiempo, no hay protocolos de monitorización estándar, como SNMP, el hardware no era compatible, solo la interfaz web. Se creó un script que recopila datos de una página de interfaz web y los descarga en un archivo xml. Pandora FMS luego descarga los datos de ese archivo y los muestra al cliente como gráficos. Los datos se transmiten a dos centros de monitorización ubicados en diferentes partes del país. Si se desvía de los valores de referencia, la advertencia se envía a los administradores por correo electrónico y Telegram.
Pandora FMS no solo puede monitorizar, sino también administrar configuraciones de dispositivos de red, proporcionar inventario, CMDB, automatización de scripts, monitorización de servicios en la nube e interfaces web (monitorización UX), monitorización de direcciones IP, etc.
¿Qué tamaño de sistema de TI se puede monitorizar con Pandora FMS?
Ilimitadamente grande y desafiante. Un servidor de monitorización puede servir hasta 50,000 sensores diferentes. Se pueden combinar varios servidores en un solo sistema con la consola Enterpise. Para clientes con una estructura compleja, existe la posibilidad de monitorización distribuida utilizando servidores Satellite. Por ejemplo, dichos servidores pueden estar en sucursales y transmitir información a un servidor central Pandora FMS con una sola conexión. Esta solución permite fallos debido al hecho de que existe la posibilidad de instalar un servidor de copia de seguridad Pandora FMS. A diferencia de la competencia, esta función es gratuita. También se admite el modo Multy-tenancy. Por ejemplo, un servidor Pandora FMS puede servir de forma independiente a diferentes departamentos o empresas dentro de un Holding.
¿Es difícil instalar e implementar el sistema?
El sistema se coloca en una plataforma Linux. Todas las distribuciones principales son compatibles: RedHat, SUSE y Rocket. MySQL se utiliza como base de datos. Pandora FMS se implementa automáticamente mediante un script durante unos 15 minutos y no se requiere un conocimiento profundo de Linux por parte del usuario. A petición del cliente, podemos proporcionar imágenes completas. El equipo de red se puede conectar a través del escaneo automático de la red, la importación de datos a través de archivos o manualmente. La supervisión de los servidores se realiza a través de SNMP, WMI y / o agentes que se pueden instalar de forma automática o manual.
¿Cuál es la diferencia entre el modelo de licencia Pandora FMS?
La compañía ofrece licencias permanentes, que es conveniente, en particular, para las organizaciones gubernamentales. Esto asegura que el sistema de monitorización nunca se detenga. Licenciado por número de hosts, en incrementos de 100. Por ejemplo, si tiene 100 servidores y 200 equipos de red, necesita 300 licencias. Incluyen todos los módulos del sistema y acceso a más de 400 plugins. El host puede ser tanto un servidor como un equipo de red. En el futuro, al comprar licencias, el cliente puede comprar bloques de hosts 50. La diferencia de precio en comparación con las soluciones de los competidores a veces alcanza el 200-300%. Debido al hecho de que Pandora FMS se ejecuta en plataformas Linux, no necesita gastar dinero en licencias de Windows y servidor MS SQL.
Para obtener más información, póngase en contacto con Advanced Technologies Solutions, que es el representante de Pandora FMS en los países de la CEI. Puede comprar Pandora FMS a través de socios en Azerbaiyán y el distribuidor Mont Azerbaijan.

por Pandora FMS team | Last updated Feb 16, 2024 | Pandora FMS
Pandora FMS sobresale como una potente solución de software de monitorización que ayuda a individuos y organizaciones de todos los tamaños. Facilita la supervisión efectiva del rendimiento y estado de servidores, aplicaciones, dispositivos de red y otros componentes esenciales de la infraestructura de tecnologías de la información.
Ya conoces de buena mano Pandora FMS y la plataforma G2, así que queremos hacerte una propuesta para aprovechar tus vastos conocimientos:
Opina sobre Pandora FMS en G2 y ayuda a otros
Pandora FMS con una amplia gama de características como mapeo de red, correlación de eventos y generación de informes, es una excelente opción para las empresas que buscan mejorar sus capacidades. Y G2 es una plataforma de opiniones de usuarios sobre soluciones de software que les permite compartir sus experiencias y puntos de vista sobre diversos productos, ayudando a otros a tomar decisiones formadas sobre soluciones tecnológicas. Por ello hemos unido fuerzas para beneficiarte a ti y a todos los usuarios que conocerán de primera mano, gracias a tu review, todas la ventajas que Pandora FMS puede aportar a sus vidas.
Nos esforzamos por mejorar el software de Pandora FMS, por eso, tu opinión puede ayudarnos mucho a entender lo que funciona bien y en qué podemos mejorar. Sabemos que tu tiempo es oro así que, como agradecimiento, G2 te ofrece una tarjeta regalo de 25$. Queremos posicionar bien ¡Y necesitamos tu ayuda para lograrlo!
¿Cuáles son los pasos para dejar una opinión sobre Pandora FMS en G2?
- Accede a la Plataforma a través de este link de G2 y asegúrate de tener una cuenta. Es posible que necesites registrarte si aún no lo has hecho.
- Deja tu Opinión: Proporciona la información requerida, como una puntuación y tu comentario.
- Incluye detalles Relevantes: Sé específico en tu opinión. Comparte detalles sobre tu experiencia con Pandora FMS, tanto aspectos positivos como negativos. Esto ayudará a otros usuarios a obtener una visión más completa.
- Confirma y Envía: Revisa tu opinión para asegurarte de que esté completa y precisa. Después, confirma y envía tu reseña.
Date prisa, tómate unos minutos en G2 y recibe tu recompensa ¡qué se acaban!*
Tu feedback es crucial para nosotros. ¡Participa y benefíciate!
*Válido para las primeras 50 reviews aprobadas.

por Olivia Díaz | Last updated Apr 1, 2024 | Pandora FMS
Los sistemas distribuidos permiten implementar proyectos de forma más eficiente y a un menor costo, pero requieren de procesamientos complejos por el hecho de que se usan diversos nodos para procesar una o varias tareas con un mayor rendimiento en distintos sitios de la red. Para comprender esta complejidad, veamos primero sus fundamentos.
Los Fundamentos de Sistemas Distribuidos
¿Qué son los sistemas distribuidos?
Un sistema distribuido es un entorno informático en que conviven múltiples dispositivos, coordinando sus esfuerzos para completar una tarea de forma mucho más eficiente que si se realizara con solo un dispositivo. Esto ofrece muchas ventajas en comparación con los entornos informáticos tradicionales, tales como mayor escalabilidad, mejoras en la fiabilidad y menos riesgos al evitar un único punto vulnerable a fallas o ataques cibernéticos.
En la arquitectura moderna los sistemas distribuidos cobran mayor relevancia al poder distribuir la carga de trabajo entre varias computadoras, servidores, dispositivos en Edge Computing, etc. (nodos), para que las tareas se ejecuten de manera confiable y más rápida, sobre todo en estos tiempos en los que existe una alta demanda de disponibilidad continua, velocidad y alto rendimiento de parte de los usuarios y las infraestructuras se extienden más allá de la organización (no solo en otras geografías, sino también en Internet de las Cosas, Edge Computing, etc.).
Tipos y Ejemplo de sistemas distribuidos:
Existen varios modelos y arquitecturas de sistemas distribuidos:
- Sistemas cliente/servidor: Son el tipo más tradicional y sencillo de sistema distribuido, en el que varios ordenadores conectados en red interactúan con un servidor central para almacenar datos, procesarlos o realizar cualquier otro objetivo común.
- Redes de telefonía móvil: Son un tipo avanzado de sistema distribuido que comparte cargas de trabajo entre terminales, sistemas de conmutación y dispositivos basados en Internet.
- Redes peer-to-peer (igual a igual): Distribuyen cargas de trabajo entre cientos o miles de ordenadores que ejecutan el mismo software.
- Instancias de servidor virtual basadas en la nube: Son actualmente las formas más comunes de sistemas distribuidos en la empresa, ya que transfieren cargas de trabajo a decenas de instancias de servidor virtual basadas en la nube que se crean según sea necesario y se terminan cuando la tarea se ha completado.
Podemos ver ejemplos de sistemas distribuidos en una red de computadoras dentro de la misma organización, los sistemas de almacenamiento en sitio local o en la nube y los sistemas de bases de datos distribuidas en un consorcio empresarial. También, varios sistemas pueden interactuar entre sí, no solo desde la organización sino con otras empresas, como podemos ver en el siguiente ejemplo:
Desde casa, uno puede comprar un producto (cliente en casa) e inicia el proceso con el servidor de la distribuidora y éste a su vez con el servidor del proveedor para abastecer el producto, conectándose también a la red del banco para realizar la transacción financiera (conectándose al mainframe regional del banco, para después conectarse con el mainframe principal del banco). O bien, en la tienda, el cliente paga en la terminal de la caja del supermercado, que a su vez conecta con el servidor del negocio y a la red del banco para registrar y confirmar la transacción financiera. Como bien puede verse, existen varios nodos (terminales, computadoras, dispositivos, etc.) que se conectan e interactúan. Para comprender cómo es posible lograr una sintonía en los sistemas distribuidos, veamos cómo colaboran los nodos entre sí.
Colaboración entre Nodos: La Sinfonía de la Distribución
- Cómo interactúan los nodos en sistemas distribuidos: los sistemas distribuidos usan un software específico para poder comunicarse y compartir recursos entre diferentes máquinas o dispositivos, además de orquestar las actividades o tareas. Para ello, se usan de protocolos y algoritmos para coordinar las acciones y el intercambio de datos. Siguiendo el ejemplo anterior, la computadora o la caja de la tienda son el cliente a partir del cual se solicita un servicio a un servidor (servidor del negocio), el cual a su vez solicita el servicio de la red del banco, el cual lleva a cabo la tarea de registrar el pago y devuelve los resultados al cliente (la caja de la tienda) de que el pago ha sido exitoso.
- Los desafíos más comunes: son el poder coordinar tareas de los nodos interconectados, garantizar la consistencia de los datos que se intercambian entre los nodos y administrar la seguridad y privacidad de los nodos y los datos que viajan en un entorno distribuido.
- Para mantener la coherencia en los sistemas distribuidos, se requieren servicios de comunicación o mensajería asincrónica, sistemas de archivos distribuidos para almacenamiento compartido y plataformas de gestión de nodos y/o clústeres para administrar los recursos.
Diseñando para la escalabilidad: Principios clave
- Importancia de la escalabilidad en entornos distribuidos: La escalabilidad es la capacidad de crecer a medida que aumenta el tamaño de la carga de trabajo, lo que se consigue añadiendo unidades de procesamiento o nodos adicionales a la red según sea necesario.
- Principios de diseño para fomentar la escalabilidad: La escalabilidad se ha vuelto vital para soportar una mayor demanda de agilidad y eficiencia por parte de los usuarios, además del creciente volumen de datos. Se debe combinar el diseño arquitectónico, actualizaciones de hardware y software para garantizar el rendimiento y la confiabilidad, con base en:
- Escalabilidad horizontal: Agregando más nodos (servidores) al conjunto de recursos existente, lo que permite que el sistema maneje mayores cargas de trabajo distribuyendo la carga entre múltiples servidores.
- Balanceo de carga: Para lograr escalabilidad técnica, se distribuyen las solicitudes entrantes de manera uniforme entre varios servidores, de manera que ningún servidor se vea abrumado.
- Escalado automatizado: Mediante algoritmos y herramientas para ajustar dinámica y automáticamente los recursos según la demanda. Esto ayuda a mantener el rendimiento durante los picos de tráfico y reducir costos durante períodos de baja demanda. Las plataformas en la nube suelen ofrecer funciones de escalamiento automático.
- Almacenamiento en caché: Mediante almacenamiento de datos a los que se accede con frecuencia o resultados de respuestas anteriores, mejorando la capacidad de respuesta y reduciendo la latencia de la red en lugar de realizar solicitudes repetidas a la base de datos.
- Escalabilidad geográfica: Agregando nuevos nodos en un espacio físico sin afectar el tiempo de comunicación entre nodos, lo cual garantiza que los sistemas distribuidos puedan manejar el tráfico global de manera eficiente.
- Escalabilidad administrativa: Gestionando nuevos nodos agregados al sistema, lo que minimiza la sobrecarga administrativa.
El rastreo o monitorización distribuida es un método para monitorizar aplicaciones construidas sobre una arquitectura de microservicios que se despliegan habitualmente en sistemas distribuidos. El seguimiento supervisa el proceso paso a paso, ayudando a los desarrolladores a descubrir errores, cuellos de botella, latencia u otros problemas con la aplicación. La importancia de la monitorización en sistemas distribuidos radica en que se puede rastrear múltiples aplicaciones y procesos simultáneamente a través de numerosos nodos y entornos informáticos concurrentes, que se han vuelto el común en las arquitecturas de los sistemas de la actualidad (en sitio, en la nube o ambientes híbridos), que también demandan estabilidad y confiabilidad en sus servicios.
Diseñando para la escalabilidad: Principios clave
Para optimizar la administración de sistemas IT y lograr la eficiencia en la entrega de los servicios de TI, es indispensable la monitorización de sistemas adecuado, ya que los datos en los sistemas de monitorización y logs permiten detectar posibles problemas como también analizar incidencias para no sólo reaccionar sino ser más proactivos.
Herramientas esenciales y mejores prácticas
Una herramienta esencial es un sistema de monitorización centrado en procesos, memoria, almacenamiento y conexiones red, con los objetivos de:
- Aprovechar al máximo los recursos de hardware de una empresa.
- Notificar posibles problemas.
- Prevenir incidencias y detectar problemas.
- Reducir costos y tiempos de implementación de sistemas.
- Mejorar la experiencia de los usuarios y la satisfacción en atención al cliente.
Además del sistema de monitorización, se deben implementar las mejores prácticas es establecer un protocolo de resolución de incidencias, que marcará una gran diferencia a la hora de resolver problemas o simplemente reaccionar, con base en:
- Predicción y prevención. Las herramientas de monitoreo adecuadas no solo permiten actuar a tiempo sino también analizar para prevenir problemas que impacten en los servicios de TI.
- Personalizar alertas e informes que realmente se necesitan y que te permitan la mejor visualización del estado y desempeño de la red y los equipos.
- Apoyarse en la automatización, aprovechando las herramientas que cuentan con algunas reglas predefinidas.
- Documentar cambios (y su seguimiento) en las herramientas de monitoreo de sistemas, que faciliten su interpretación y auditoría (quién y cuándo realizó cambios).
Por último, se recomienda elegir la herramienta adecuada de acuerdo con el entorno de TI y madurez de la organización, los procesos críticos del negocio y su dispersión geográfica.
Resiliencia Empresarial: Monitorización Proactiva
Acceder en tiempo real para conocer el estado de los sistemas y activos informáticos críticos para la empresa permite detectar el origen de los incidentes. Sin embargo, la resiliencia mediante la monitorización proactiva se logra a partir de protocolos de actuación para resolver problemas en forma eficaz cuando se tiene claro qué y cómo hacer, además de contar con datos para emprender acciones proactivas y alertas frente a llenado de discos duros, límites en el uso de memoria y posibles vulnerabilidades al acceso a discos, etc., antes de que se conviertan en un posible problema, ahorrando también costos y tiempos del staff de TI para resolver incidentes. Veamos algunos casos de estudio que destacan la resolución rápida de problemas.
- Caso Cajasol: Necesitábamos un sistema que tuviera disponible una planta productiva muy amplia, en la que convivieran diferentes arquitecturas y aplicaciones, las cuales es necesario tener controladas y ser transparentes y proactivos.
- Caso Fripozo: Era necesario enterarse a tiempo de los fallos y corregirlos lo antes posible, pues esto redundaba en un peor servicio del departamento de sistemas al resto de la compañía.
Optimizando rendimiento: estrategias de monitorización efectiva
La supervisión constante de los sistemas permite gestionar los desafíos en su rendimiento, ya que permite identificar los problemas antes de que se conviertan en una suspensión o el fallo total que impida la continuidad del negocio, basándose en:
- La recopilación de datos sobre rendimiento y el estado de los sistemas.
- La visualización de métricas para detectar anomalías y patrones de comportamiento de los equipos, redes y aplicaciones.
- La generación de alertas personalizadas, que permitan accionar en tiempo y forma.
- La integración con otras plataformas y herramientas de gestión y automatización.
Monitorización con Pandora FMS en entornos distribuidos
Monitorización con agentes
La monitorización con agentes es una de las formas más efectivas de obtener información detallada sobre sistemas distribuidos. Se instala un software ligero en los sistemas operativos que recopila continuamente datos del sistema en el que está instalado. Pandora FMS utiliza agentes para acceder a información más profunda que los chequeos de red, permitiendo monitorizar “desde dentro” las aplicaciones y servicios en un servidor. La información comúnmente recopilada mediante la monitorización con agentes incluye:
- Uso de CPU y memoria.
- Capacidad de discos.
- Procesos en ejecución.
- Servicios levantados.
Monitorización interna de aplicaciones
Chequeos remotos con agentes – Modo broker
En escenarios donde se necesita monitorizar una máquina remota y no se puede llegar a ella directamente desde el servidor central de Pandora FMS, se utiliza el modo broker de los agentes instalados en sistemas locales. El agente broker ejecuta chequeos remotos en sistemas externos y envía la información al servidor central, actuando como un intermediario.
Monitorización de redes remotas con proxy de agentes – Modo proxy
Cuando se desea monitorizar una subred completa y el servidor central de Pandora FMS no puede llegar directamente a ella, se utiliza el modo proxy. Este modo permite que los agentes en sistemas remotos reenvíen sus datos XML a un agente proxy, que luego los transmite al servidor central. Es útil cuando solo una máquina puede comunicarse con el servidor central.
Monitorización distribuida con varios servidores
En situaciones donde se necesita monitorizar un gran número de dispositivos y un solo servidor no es suficiente, se pueden instalar varios servidores de Pandora FMS. Todos estos servidores están conectados a la misma base de datos, lo que permite distribuir la carga y manejar subredes diferentes de manera independiente.
Monitorización distribuida delegada – Export Server
Cuando se brindan servicios de monitorización a múltiples clientes, cada uno con su instalación independiente de Pandora FMS, se puede utilizar la funcionalidad de Export Server. Este servidor exportador permite tener una visión consolidada de la monitorización de todos los clientes desde una instalación central de Pandora FMS, con la capacidad de establecer alertas y umbrales personalizados.
Monitorización de redes remotas con chequeos locales y de red – Satellite Server
Cuando se necesita monitorizar una red externa tipo DMZ y se requiere tanto chequeos remotos como monitorización con agentes, se utiliza el Satellite Server. Este servidor satélite se instala en la DMZ y realiza chequeos remotos, recibe datos de agentes y los reenvía al servidor central de Pandora FMS. Es especialmente útil cuando el servidor central no puede abrir conexiones directas a la base de datos de la red interna.
Monitorización de redes aisladas securizadas – Sync Server
En entornos donde la seguridad impide abrir comunicaciones desde ciertas ubicaciones, como datacenters en diferentes países, se puede utilizar el Sync Server. Este componente, introducido en la versión 7 “Next Generation” de Pandora FMS, permite que el servidor central inicie comunicaciones hacia entornos aislados, donde se instala un servidor satélite y varios agentes para la monitorización.
La monitorización distribuida con Pandora FMS ofrece soluciones flexibles y eficientes para adaptarse a diversas topologías de red en entornos distribuidos.
Conclusión:
Emprender las mejores prácticas para implementar sistemas distribuidos son críticas para desarrollar la resiliencia de las organizaciones en infraestructuras y servicios de TI más complejos de gestionar, que requieren adaptación y proactividad ante las necesidades de las organizaciones de rendimiento, escalabilidad, seguridad y optimización de costos. Los estrategas de TI deben apoyarse en la monitorización de sistemas más robusta, informada y confiable, sobre todo cuando en las organizaciones de hoy y aquellas que miran hacia el futuro, los sistemas estarán cada vez más descentralizados (ya no todo en uno o varios data centers sino también en distintas nubes) y extendiéndose más allá de sus paredes, con centros de datos más cercanos a sus consumidores o usuarios finales y más cómputo de borde (Edge Computing). Para poner un ejemplo, según el Índice de Interconexión global 2023 (GXI) de la empresa Equinix, las organizaciones están interconectando la infraestructura de borde un 20% más rápidamente que el núcleo. Además, el mismo índice indica que el 30% de la infraestructura digital se ha trasladado a Edge Computing. Otra tendencia es que las empresas están cada vez más conscientes de los datos para tener más detalles sobre su operación, sus procesos e interacciones con los clientes, buscando una mejor interconexión con su ecosistema, directamente con sus proveedores o socios para ofrecer servicios digitales. Del lado de la experiencia de los usuarios y clientes estará siempre la necesidad de servicios de TI con respuestas inmediatas, estables y confiables las 24 horas del día y los 365 días del año.
Si te interesó este artículo, puedes leer también: opología de red y monitorización distribuida

por Olivia Díaz | Last updated Feb 23, 2024 | Pandora FMS
Para abordar este tema, primero hay que comprender que, en la digitalización que estamos viviendo, existen múltiples recursos y dispositivos que conviven en una misma red y que requieren de un conjunto de reglas, formatos, políticas y estándares para poder reconocerse entre sí, intercambiar datos y, de ser posible, identificar si existe algún problema para comunicarse, no importando la diferencia de diseño, hardware o infraestructura, usando un mismo lenguaje para enviar y recibir información. Esto es lo que denominamos protocolos de red (network protocols), que podemos clasificar en:
- Protocolos de comunicación de red para la comunicación entre los dispositivos de la red, ya sea en transferencia de archivos entre ordenadores o a través de Internet, hasta intercambio de mensajes de texto y la comunicación entre enrutadores y dispositivos externos o de Internet de las Cosas (IoT). Ejemplos: Bluetooth, FTP, TCP/IP y HTTP.
- Protocolos de seguridad de red para implementar la seguridad en las comunicaciones de la red, de manera que los usuarios no autorizados no puedan acceder a los datos transferidos a través de una red, ya sea por medio de contraseñas, autenticación o cifrado de datos. Ejemplos: HTTPS, SSL, SSH y SFTP.
- Protocolos de administración de red que permiten implementar la gestión y el mantenimiento de la red al definir los procedimientos necesarios para operar una red. Estos protocolos se encargan de asegurar que cada dispositivo esté conectado a los demás y a la propia red, además de vigilar la estabilidad de estas conexiones. También son recursos para solucionar problemas y evaluar la calidad de la conexión de red.
Importancia y contexto en la Administración de Redes
La gestión de redes abarca desde la configuración inicial hasta el constante monitoreo de los recursos y dispositivos, con el fin de garantizar la conectividad, la seguridad y el mantenimiento adecuado de la red. Esta comunicación y flujo de datos eficientes tienen impacto en el negocio para alcanzar sus objetivos en ambientes estables, confiables, seguros, eficientes, mejor experiencia de los usuarios y, por consecuencia, la mejor experiencia de socios y clientes.
Algo importante es el conocimiento del contexto de la red (topología y diseño), ya que hay un impacto en su escalabilidad, seguridad y complejidad. Mediante diagramas de red, mapas y documentación para visualizar y comprender la topología y el diseño de la red es posible realizar análisis para identificar los potenciales cuellos de botella, vulnerabilidades e ineficiencias donde hay que tomar acción para corregirla u optimizarla.
Otro aspecto importante son los recursos compartidos no solo en la red sino en infraestructuras cada vez más extendidas en la nube, en Edge Computing e incluso en Internet de las cosas que demandan el monitoreo sobre el estado de la red, la configuración y diagnóstico de red para fomentar la eficiencia, establecer prioridades y también anticipar o resolver problemas de conexión en la red y en internet.
Más adelante hablaremos sobre los beneficios de la Administración de Redes.
Protocolos de red vs protocolos de administración de red
Como bien se explicó anteriormente, los protocolos de administración de redes forman parte de los protocolos de red. Aunque puedan parecer lo mismo, hay diferencias: los protocolos de red, por norma general, permiten una transferencia de datos entre dos o más dispositivos y no están destinados a gestionar o administrar dichos dispositivos, en tanto que los protocolos de administración de red no tienen por objetivo la transferencia de información, sino la transferencia de datos administrativos (definición de procesos, procedimientos y políticas), que permiten gestionar, monitorear y mantener una red informática.
Lo importante es comprender lo siguiente:
- Dentro de una misma red, los protocolos de comunicación de red tendrán que convivir con los protocolos de administración de red.
- Los protocolos de administración de red también tienen injerencia en el rendimiento global de las plataformas, por lo que es fundamental conocerlos y controlarlos.
- La adopción de la nube y tecnologías emergentes, como Edge Computing e Internet de las Cosas, dejan claro que la conectividad confiable y eficiente es fundamental.
Protocolos de Administración de Red en Profundidad
Los protocolos de administración de red permiten conocer el estado de los recursos, equipos y dispositivos en la red (enrutadores, computadoras, servidores, sensores, ec.), y brindan información sobre su disponibilidad, posible latencia de la red o pérdida de datos, fallos, entre otros. Los protocolos de administración de red más comunes son: Protocolo Simple de Administración de Red (Simple Network Management Protocol o SNMP), Protocolo de Mensajes de Control de Internet (Internet Control Message Protocol o ICMP) y la Instrumentación de Administración de Windows (Windows Management Instrumentation o WMI), como se ve en el siguiente diagrama y que explicaremos a continuación:
Protocolo Simple de Administración de Red (SNMP)
SNMP es un conjunto de protocolos para administrar y monitorear la red, que son compatibles con la mayoría de los dispositivos (switches, estaciones de trabajo, impresoras, módems y otros) y marcas (la mayoría de los fabricantes se aseguran de que su producto incluya el soporte a SNMP) para detectar condiciones. Los estándares SNMP incluyen un protocolo de capa de aplicación, un conjunto de objetos de datos y una metodología para almacenar, manipular y utilizar objetos de datos en un esquema de base de datos. Estos protocolos son definidos por el Consejo de Arquitectura de Internet (Internet Architecture Board, IAB) y han ido evolucionando desde su primera implementación:
- SNMPv1: primera versión que opera dentro de la especificación de información de gestión de estructuras y se describe en RFC 1157.
- SNMPv2: versión en que se mejoró el soporte para la eficiencia y el manejo de errores, que se describe en RFC 1901.
- SNMPv3: esta versión mejora la seguridad y privacidad, introducido en RFC 3410.
Desglose de la Arquitectura SNMP: Agentes y Administradores
Todos los protocolos de administración de red proponen una arquitectura y unos procedimientos para extraer, recolectar, transferir, almacenar y reportar información proveniente de los elementos administrados. Es importante entender esta arquitectura y sus procedimientos para instrumentar una solución en función de dicho protocolo.
La arquitectura de SNMP se basa en dos componentes básicos: Agentes y los Administradores o Gestores, como presentamos en el siguiente diagrama de un esquema básico de la arquitectura SNMP:
Donde:
- Los agentes SNMP son piezas de software que corren en los elementos a ser administrados. Son los encargados de reunir la información sobre el dispositivo en cuestión. Luego, cuando los administradores SNMP solicitan dicha información a través de queries (consultas), el agente hará el envío correspondiente. Los agentes SNMP también pueden enviar al Administrador SNMP información que no corresponde a una consulta sino que parte de un evento que ocurre en el dispositivo y que requiere ser notificado. Entonces, se dice que el agente SNMP envía de forma proactiva un TRAP de notificación.
- Los Administradores SNMP o gestores SNMP son encontrados como parte de una herramienta de administración o de monitorización y están diseñados para funcionar como consolas donde se centraliza toda la información captada y enviada por los agentes SNMP.
- Los OID (Object Identifier o identificador de objeto) son los elementos que se utilizan para identificar los objetos que se desea administrar. Los OID siguen un formato de números como: .1.3.6.1.4.1.9.9.276.1.1.1.1.11. Estos números se extraen de un sistema de organización jerárquico que permite identificar el fabricante del dispositivo, para luego identificar el dispositivo y finalmente el objeto en cuestión. En la siguiente imagen vemos un ejemplo de este esquema de árbol de OID.
- Las MIB (Management Information Base o Base de Información de Gestión) refieren a los formatos que cumplirán los datos enviados desde los agentes SNMP a los gestores SNMP. En la práctica, se dispone de una plantilla general con lo que necesitamos para administrar cualquier dispositivo y luego se dispone de MIB individualizadas para cada dispositivo, con sus parámetros particulares y los valores que estos parámetros pueden alcanzar.
Las funciones cruciales de SNMP son:
- Validación de fallos: Para detección, aislamiento y corrección de problemas de red. Con la operación trap de SNMP, puede obtener el informe del problema del agente SNMP que se ejecuta en esa máquina. El administrador de la red puede entonces decidir cómo, probándolo, corrigiendo o aislando esa entidad problemática. El monitor SNMP de OpManager tiene un sistema de alerta que asegura que se le notifique con suficiente anticipación sobre problemas de la red, como averías y ralentizaciones en el rendimiento.
- Métricas de rendimiento: El monitoreo del rendimiento de la red es un proceso para rastrear y analizar eventos y actividades de la red para realizar los ajustes necesarios que mejoren el rendimiento de la red. Con las operaciones get y set de SNMP, el administrador de la red puede realizar un seguimiento del rendimiento en la red. OpManager, una herramienta de monitoreo de red SNMP, viene con informes poderosos y detallados para ayudarlo a analizar las métricas de rendimiento clave, como la disponibilidad de la red, los tiempos de respuesta, el rendimiento y el uso de recursos, lo que facilita la Gestión de SNMP.
Para profundizar sobre SNMP se recomienda leer el Blog Monitorización SNMP: claves para aprender a usar el Protocolo Simple de Administración de Red.
Protocolo de Mensajes de Control de Internet (Internet Control Message Protocol o ICMP)
Éste es un protocolo de capa de red utilizado por dispositivos de red para diagnosticar problemas de comunicación y realizar consultas de gestión. Esto hace que ICMP sea utilizado para determinar si los datos llegan o no al destino previsto de manera oportuna y sus causas, además de permitir analizar métricas de rendimiento como niveles de latencia, tiempo de respuesta o pérdida de paquetes. Los mensajes contemplados de ICMP suelen clasificarse en dos categorías:
- Mensajes de error: Utilizados para reportar un error en la transmisión de paquete.
- Mensajes de control: Utilizados para informar sobre el estado de los dispositivos.
La arquitectura con la que trabaja ICMP es muy flexible, ya que cualquier dispositivo de la red puede enviar, recibir o procesar mensajes ICMP sobre errores y controles necesarios en los sistemas de red informando a la fuente original para que se evite o corrija el problema detectado. Los tipos más comunes de mensajes ICMP son clave en la detección de fallas y en los cálculos de métricas de desempeño:
- Solicitud de eco y respuesta de eco: se utilizan para probar la conectividad de la red y determinar el tiempo de ida y vuelta para los paquetes enviados entre dos dispositivos.
- Destino inalcanzable: enviado por un enrutador para indicar que un paquete no puede entregarse a su destino.
- Redireccionamiento: enviado por un enrutador para informar a un host que debe enviar paquetes a un enrutador diferente.
- Tiempo excedido: enviado por un enrutador para indicar que un paquete ha sido descartado porque excedió su valor de tiempo de vida (time-to-live o TTL).
- Problema de parámetros: enviado por un enrutador para indicar que un paquete contiene un error en uno de sus campos.
Por ejemplo, cada router que reenvía un datagrama IP tiene que disminuir el campo de tiempo de vida (TTL) de la cabecera IP en una unidad; si el TTL llega a cero, un mensaje ICMP tipo 11 (“Tiempo excedido”) es enviado al originador del datagrama.
Cabe notar que en ocasiones es necesario analizar el contenido del mensaje ICMP para determinar el tipo de error que debe enviarse a la aplicación responsable de transmitir el paquete IP que solicitará el envío del mensaje ICMP.
Para más detalle, se recomienda acceder a los Foros de Discusión de Pandora FMS, con tips y experiencias de usuarios y colegas en la Administración de Redes usando este protocolo.
Instrumentación de Administración de Windows (WMI o Windows Management Instrumentation)
Con WMI (Windows Management Instrumentation) nos moveremos en el universo compuesto por equipos que corren algún sistema operativo Windows y por las aplicaciones que dependen de dicho sistema operativo. De hecho, WMI propone un modelo para representar, obtener, almacenar y compartir información de administración sobre el hardware y el software basado en Windows, tanto en forma local como remota. También, WMI permite la ejecución de ciertas acciones. Por ejemplo, los desarrolladores y administradores de TI pueden usar scripts o aplicaciones WMI para automatizar tareas administrativas en equipos u ordenadores ubicados en forma remota, así como también obtener datos desde WMI en varios lenguajes de programación.
Arquitectura WMI
La arquitectura WMI está compuesta por Proveedores WMI, Infraestructura WMI y Aplicaciones, Servicios o Scripts como se ejemplifica en este diagrama:
Donde:
- Proveedor de WMI es la pieza encargada de obtener información de administración de uno o más objetos.
- La infraestructura WMI actúa como intermediario entre los proveedores y las herramientas de administración. Entre sus responsabilidades se encuentran las siguientes:
- Obtener de forma planificada la data generada por los proveedores.
- Mantener un repositorio con toda la data obtenida de forma planificada.
- Encontrar de forma dinámica la data solicitada por las herramientas de administración, para lo cual se hará primero una búsqueda en el repositorio y, de no encontrarse la data solicitada, se hará una búsqueda entre los proveedores apropiados.
- Las aplicaciones de administración corresponden a las aplicaciones, servicios o scripts que utilizan y procesan la información sobre los objetos administrados. WMI logra ofrecer una interfaz uniforme a través de la cual se pueden tener aplicaciones, servicios y scripts solicitando datos y ejecutando las acciones que proponen los proveedores WMI sobre los objetos que se desean administrar.
Utilización de CIM y Desglose de Clases WMI
WMI se basa en CIM (Common Information Model), que es un modelo que utiliza técnicas basadas en objetos para describir diferentes partes de una empresa. Se trata de un modelo muy extendido en los productos Microsoft; de hecho, cuando se instala Microsoft Office o un servidor Exchange, por ejemplo, la extensión del modelo correspondiente al producto es instalada automáticamente.
Justamente esa extensión que viene con cada producto es lo que se conoce como WMI CLASS, que describe el objeto que se va administrar y todo lo que se puede hacer con el mismo. Esta descripción parte de los atributos que maneja la clase, tales como:
- Propiedades: Características propias de los objetos, como su nombre, por ejemplo.
- Métodos: Acciones que se pueden realizar sobre el objeto, como ¨detener¨ para el caso de un objeto que sea un servicio.
- Asociaciones: Refieren a las posibles asociaciones entre objetos.
Los proveedores WMI utilizan las clases de los objetos para recolectar la información de administración y esta información pasa a la infraestructura WMI, para lo cual se requiere organizar los datos. Esta organización se logra a través de contenedores lógicos llamados namespaces, los cuales se definen por área de administración y contienen la data que proviene de los objetos relacionados.
Los namespaces se definen bajo un esquema jerárquico que recuerda al esquema que siguen las carpetas en un disco. Una analogía que utilizan muchos autores para explicar la organización de la data en WMI es comparar WMI con las bases de datos, donde las clases corresponden a las tablas, los namespaces a las bases de datos y la infraestructura WMI al manejador de base de datos.
Para ahondar más sobre WMI, recomendamos leer el Blog ¿Qué es WMI? Windows Management Instrumentation, ¿lo conoces?
Perspectivas clave para el análisis de Protocolos de Administración de Red
Es fácil entender que mientras más compleja y heterogénea sea la plataforma que se desea administrar, mayor será su dificultad desde tres ángulos:
- Fallos: Disponer de procedimientos de detección de los fallos y un esquema para reportarlos.
- Rendimiento: Información sobre el comportamiento de la plataforma para comprender y optimizar su rendimiento.
- Acciones: Muchos protocolos de administración incluyen la posibilidad de ejecutar acciones sobre los dispositivos de la red (actualización, cambios, instauración de alertas, reconfiguraciones, entre otros).
Es importante comprender cuál de los tres ángulos ataca cada uno de los protocolos y, por tanto, qué será lo que nos permita hacer. Un pilar fundamental es la Organización de los Datos que explicaremos a continuación.
Organización efectiva de los datos: pilar fundamental en los protocolos de administración de red
Un aspecto fundamental en los Protocolos de Administración de Red es la forma en cómo se definen e identifican los elementos a administrar, haciendo planteamientos sobre:
- ¿Qué elemento puedo administrar con este protocolo?
- ¿Solo debe ser el hardware o también se debe considerar aplicaciones, por ejemplo?
- ¿Qué formato se debe utilizar para manejar los datos? ¿Cómo se debe almacenar, si es que se almacena?
- ¿Cuáles son las opciones que tengo para acceder a esta información?
En ese sentido, la organización efectiva de los datos permite el intercambio exitoso de la información entre los dispositivos y recursos en la red. En el monitoreo de la red, se requieren datos desde enrutadores, conmutadores, firewalls, balanceadores de carga e incluso end points o puntos finales, como servidores y estaciones de trabajo. Los datos obtenidos se filtran y analizan para identificar posibles problemas de red como cambios en configuración o fallas en dispositivo, interrupciones en los enlaces, errores de interfaz, paquetes perdidos, latencia o tiempo de respuesta de aplicaciones o servicios en la red. Los datos también permiten implementar la planificación de los recursos por crecimiento de tráfico o la incorporación de nuevos usuarios o servicios.
Desafíos, Beneficios y Tareas Clave en los Protocolos de Administración de Red
Para quienes están a cargo de operar y administrar las redes empresariales, es importante conocer cinco desafíos comunes:
- Ambientes mixtos, en que existen recursos y dispositivos en redes locales y remotas (incluyendo Edge Computing e IoT), lo que hace necesario adaptarse a las demandas de redes híbridas.
- Comprender las necesidades de la red y realizar una planificación estratégica, no sólo en ambientes físicos sino también en la nube.
- Reforzar la seguridad y confiabilidad de redes cada vez más dinámicas, más cuando los ecosistemas empresariales están involucrando a clientes, proveedores y socios de negocio que se interconectan.
- Lograr la observabilidad que permita eliminar puntos ciegos de la red y obtener una visualización integral de la infraestructura de TI.
- Establecer una estrategia de administración de red que pueda conectarse, integrarse e incluso automatizarse, especialmente cuando los equipos de TI cumplen cada vez más tareas en su día a día.
Como hemos visto a lo largo de este Blog, entender cómo funcionan los protocolos de administración de redes resulta esencial para la comunicación, la continuidad de las operaciones y la seguridad, que en su conjunto tienen gran impacto en las organizaciones para:
- Establecer y mantener conexiones estables entre dispositivos en la misma red, lo que a su vez resulta en menos latencia y una mejor experiencia para los usuarios de la red.
- Gestionar y combinar múltiples conexiones de red, incluso desde un solo enlace, lo que puede fortalecer la conexión y prevenir posibles fallas.
- Identificar y solucionar errores que afectan a la red, evaluando la calidad de la conexión y resolviendo problemas (menor latencia, restablecimiento de comunicación, prevención de riesgos en operaciones, etc.)
- Establecer estrategias de protección de la red y los datos transmitidos a través de ella, apoyándose en la encriptación, autenticación de entidad (de dispositivos o usuarios), seguridad de transporte (entre un dispositivo y otro).
- Implementación de métricas de rendimiento que garanticen niveles de servicio con calidad.
Tareas y Beneficios Clave en la Gestión de Redes
En la administración de redes eficiente se involucran la conectividad de los dispositivos, los sistemas de acceso, la automatización de red, la conectividad de servidores, la gestión de switches y el aseguramiento de la red, por lo que se recomienda llevar a cabo las siguientes tareas:
- Estrategias para Actualizaciones y Mantenimiento Efectivo: uno de los grandes desafíos es lograr la visibilidad de red de punta a punta en un entorno empresarial cada vez más complejo. La mayoría de los profesionales de TI tienen un conocimiento incompleto de cómo está configurada su red, ya que constantemente se agregan nuevos componentes, hardware, conmutadores, dispositivos, etc. Por lo que es vital mantener un catálogo actualizado de su red y dar mantenimiento adecuado para guiar los principios de administración de la red y hacer cumplir las políticas correctas. También hay que considerar que hay cambios de recursos en su equipo de TI. Es posible que el administrador original que definió la topología de la red y los protocolos necesarios puede ya no estar disponible, lo que podría implicar tener que someterse a una revisión completa de la administración de la red e incurrir en costos adicionales. Esto se puede evitar mediante documentación detallada de las configuraciones, las políticas de seguridad y las arquitecturas para garantizar que las prácticas de gestión sigan siendo reutilizables a lo largo del tiempo.
- Monitoreo Riguroso del Rendimiento: La gestión de la red demanda un monitoreo del rendimiento (por ejemplo, con un tablero de mando con indicadores de desempeño) en forma constante y rigurosa con los estándares definidos para dar el mejor servicio y una experiencia de uso satisfactoria sin latencia y en forma más estable posible. Anteriormente esto era un desafío mayor cuando los entornos de red tradicionales se basaban principalmente en hardware para múltiples dispositivos, ordenadores y servidores administrados; hoy, los avances en la tecnología de redes definidas por software permiten estandarizar procesos y minimizar el esfuerzo humano para monitorear el rendimiento en tiempo real. También se recomienda asegurarse de que el software de gestión de red no esté sesgado hacia uno o unos pocos fabricantes de equipos originales (OEM) para evitar la dependencia de uno o pocos proveedores a largo plazo. El impacto también se vería en la dificultad para diversificar las inversiones en TI al paso del tiempo.
- Prevención de Tiempo de Inactividad: Un equipo designado para la gestión de fallas en la red permite anticipar, detectar y resolver incidentes en la red para minimizar el tiempo de inactividad. Además de eso, el equipo es responsable de registrar información sobre los fallos, realizar registros, analizar y ayudar en auditorías periódicas. Esto implica que el equipo de gestión de fallos de la red tenga la capacidad de informar al administrador de la red para mantener la transparencia, y estar en estrecha colaboración con el usuario final en caso de que deba informarse los fallos. También, se recomienda apoyarse en un proveedor de servicios administrados (Managed Service Provider o MSP) como un socio externo que puede ayudar en el diseño e implementación de la red y en el mantenimiento rutinario, controles de seguridad y cambios de configuración, además de poder apoyar en la administración en forma y el soporte en sitio.
- Gestión de la Protección y Amenazas de Seguridad en Red: Cada vez más los procesos empresariales se mueven en línea, por lo que la seguridad de la red es vital para lograr la resiliencia, junto con la gestión de riesgos. En una red empresarial se genera un flujo regular de registros que son analizados por el equipo de gestión de seguridad de la red para encontrar huellas digitales de amenazas. Dependiendo del negocio y el tamaño de la organización, es posible tener equipos o personal asignado para cada tipo de gestión de la red. Aunque también se recomienda apoyarse en servicios gestionados por expertos en la industria en que se desenvuelve la organización, con un conocimiento claro de los riesgos comunes, mejores prácticas de seguridad y con expertos en la materia de seguridad que constantemente evoluciona y se vuelve más sofisticada.
- Gestión Ágil de Direcciones IP y Aprovisionamiento Eficiente: Los protocolos de red son la columna vertebral de la comunicación digital con reglas y procedimientos sobre cómo se transmiten los datos entre dispositivos dentro de una red, independientemente del hardware o software involucrado. Un aprovisionamiento debe contemplar la infraestructura de TI en la empresa y el flujo y tránsito de datos en distintos niveles desde la red, incluyendo servidores, aplicaciones y usuarios para brindar conectividad y seguridad (gestionando también dispositivos e identidades de los usuarios). Otra tarea importante en la administración de la red es la transparencia sobre el uso, anomalías y tendencias de uso para diferentes funciones o unidades de negocio e incluso usuarios individuales. Esto resulta de particular valor para grandes empresas en que deben transparentar el uso de servicios compartidos que alquila recursos de red a diferentes sucursales y subsidiarias para mantener un margen de beneficio interno.
Resumen y conclusión
En la digitalización del negocio, los Protocolos de Administración de Red tiene por objetivo emprender acciones y estandarizar procesos para lograr una red segura, confiable y de alto rendimiento para los usuarios finales (empleados, socios, proveedores y clientes finales). Las empresas distribuidas en distintas geografías dependen de los Protocolos de Administración de Red para mantener conectadas las diferentes áreas de negocio, funciones y equipos empresariales, permitiendo el flujo de datos dentro y fuera de la empresa, ya sea en servidores locales, nubes privadas o nubes públicas.
A medida que la tecnología continúa evolucionando, también lo hacen los protocolos de red. El estratega de TI y los equipos asignados a la administración de redes deben prepararse para el futuro de los protocolos de red y la integración de tecnologías emergentes, para el aprovechamiento de los avances en velocidad, confiabilidad y seguridad. Por ejemplo, 5G es una tecnología que se espera tenga un impacto significativo en las redes, impulsada por la necesidad de mayor conectividad y menor latencia. También la vida cotidiana de las personas implica conectar objetos (vehículos, electrodomésticos, sensores, etc.), revolucionando las redes para atender al Internet de las Cosas. En Seguridad, se están desarrollando protocolos de red más robustos, como el Transport Layer Security (TLS), que cifra los datos transmitidos para evitar el acceso o la manipulación por parte de terceros.
Todo esto nos dice que el desarrollo de protocolos de red no se desacelerará en el corto plazo a medida que avancemos hacia un mundo cada vez más conectado.
Pandora FMS trabaja con los tres protocolos principales para la administración de la red para ofrecer una solución de monitorización amplia y flexible. Consulte con el equipo comercial de Pandora FMS para obtener una prueba gratuita del software de monitorización más flexible del mercado: https://pandorafms.com/es/demo-gratuita/
Para más información, conéctese con sus colegas para hallar respuestas y también para hacer llegar sus preguntas en nuestros grupos privados o públicos en: pandorafms.com/community
No dude en enviar sus consultas. El equipo de Pandora FMS estará encantado de atenderle!

por Olivia Díaz | Last updated Feb 23, 2024 | Pandora FMS
Digital-First (primero digital) ha sido la tendencia de las organizaciones en el mundo y América Latina, en que se opta primero por una estrategia digital para la entrega de productos y servicios, especialmente cuando se busca un mayor impacto de la marca de forma más inmediata a un determinado segmento del mercado junto con una difusión más amplia sobre la oferta, de manera más personalizada y, sobre todo, si se busca acercarse más al cliente final. Según Marketing4Commerce, Digital Report, el número de usuarios de internet en el mundo alcanza los 5,160 millones (64,4% de la población mundial, al 2023) con un tiempo de navegación en internet mayor a 6 horas, y personas con dispositivos móviles alcanzan los 5,440 millones (68% de la población mundial, al 2023).
También, esto lo vemos reflejado en un reporte de Adobe (Tendencias Digitales de 2023) en que más de 70% de las organizaciones, tanto líderes como seguidoras, consideran que las expectativas de sus clientes se ajustan constantemente para alinearse a las experiencias omnicanal mejoradas, esto es porque los clientes finales están constantemente evaluando sus experiencias en comparación con su última mejor experiencia. Ciertamente, las experiencias más memorables serán creadas por las organizaciones que sepan aprovechar los datos y los combinen con el conocimiento humano para anticiparse a las necesidades del cliente, con mayor empatía y en forma más individualizada.
En este panorama la Inteligencia Artificial (IA) se convierte en una aliada para implementar estrategias de experiencia del cliente en forma personalizada e innovadora, aprovechando herramientas de reconocimiento de voz, comprensión del lenguaje natural, los datos sobre patrones de conducta y las preferencias del consumidor. En los últimos años las interacciones con asistentes virtuales se han vuelto el común, impulsando el desarrollo de modelos de lenguaje para determinadas tareas o resultados esperados. A esto se le conoce como Ingeniería de Preguntas, el cual es el proceso de construir alertas o inputs para guiar a una determinada conducta del sistema de IA y obtener respuestas deseadas y precisas a partir de los modelos de IA. De manera que la IA asume un papel de colaborador digital que no solo sirve de punto de contacto con el consumidor, sino que también impulsa el conocimiento y la productividad para los colaboradores de la organización.
¿Qué es la Ingeniería de Preguntas?
De acuerdo con Techopedia, la Ingeniería de Preguntas (Prompt Engineering) refiere a una técnica utilizada en inteligencia artificial (IA) para optimizar y ajustar modelos de lenguaje para tareas particulares y resultados deseados. También se la conoce como diseño de avisos o alertas (Prompts), que construye cuidadosamente indicaciones o entradas para modelos de IA con el fin de mejorar su desempeño de tareas específicas. Los prompts, adecuadamente diseñados, se utilizan para guiar y modificar el comportamiento deseado del sistema de IA y obtener respuestas precisas y deseadas de los modelos de IA.
La Ingeniería de Preguntas usa las capacidades de los modelos de lenguaje y optimiza sus resultados a través de indicaciones correctamente diseñadas. Esto permite no depender solo de la capacitación previa o el ajuste, además de ayudar a los usuarios a guiar los modelos para lograr objetivos específicos, fomentando respuestas precisas y proporcionando instrucciones directas, excepciones o ejemplos en las indicaciones.
De acuerdo con una encuesta realizada por la empresa COPC Inc. Durante el año 2022, “Mejorar la experiencia del cliente” alcanzó el 87% como el objetivo más mencionado en cuanto a la implementación de soluciones basadas en IA. En este aspecto, 83% de los encuestados afirmaron que utilizan soluciones basadas en IA mayormente para aplicaciones de contacto con sus clientes, y es que la IA tiene un sinfín de usos que impactan directamente en la Experiencia del Cliente. Según un estudio realizado por CX optimization 2023, los usos más implementados son la creación de contenidos, perfilamiento del cliente y reducción de las llamadas internas.
Para procesar estos prompts, tenemos a los Modelos de Lenguaje Grandes (Large Language Models, LLM), que son modelos lingüísticos avanzados basados en algoritmos de Deep Learning (aprendizaje profundo) para procesar y analizar grandes cantidades de datos de texto. LLM trabaja a partir de redes neuronales artificiales (sistemas que se inspiran en la función del cerebro humano), que se entrenan para aprender patrones y relaciones en un texto y generar respuestas a las preguntas de los usuarios. Esto permite que LLM sea capaz de analizar grandes volúmenes de datos de texto y, a partir de ello, usar dicha información para entender palabras, frases y oraciones y sus contextos, habilitando la comunicación humana-IA.
Lado Técnico de la Ingeniería de Preguntas
Como habíamos mencionado anteriormente, los LLM se entrenan a partir de grandes cantidades de datos de texto para enseñar al modelo a reconocer relaciones y patrones en un texto. Todos estos datos son procesados para ajustar parámetros del modelo y, de ese modo, mejorar la precisión y comprensión del lenguaje. También se usan técnicas de preprocesamiento de textos (eliminación de palabras irrelevantes, estandarización de palabras para detectar la variabilidad de un texto), ajustes de hiperparámetros y optimización para lograr la mayor precisión en el modelo. Para implementar la Ingeniería de Preguntas, existen diversas técnicas, tales como:
- Zero-Shot Prompting genera una respuesta sin dar a los modelos lingüísticos ejemplos ni contexto previo. Se usa para respuestas rápidas a preguntas o temas generales.
- Ejemplo: “¿Qué es un prompt?”
- Respuesta: “Un Prompt es…”
- One-Shot Prompting se extrae una respuesta desde un ejemplo o contexto proporcionado por el usuario.
- Ejemplo: “Si presupuesto en portugués es orçamento, ¿cómo puedo traducir Proveedor?”
- Respuesta: “Fornecedor”.
- Recuperación de información se formula a la IA generativa una pregunta concreta para obtener respuestas detalladas. La clave de esto es la fuente de datos de donde se alimentan los LLMs. Por ejemplo, ChatGPT solo tiene acceso a datos posteriores a septiembre de 2021.
- Ejemplo: “¿Cuáles son las ventajas de LLM?”
- Respuesta: “1. Diversificación de contenidos. 2. Personalización…”.
- Escritura creativa a través de esta técnica es posible desarrollar textos con imaginación, historias y expresiones textuales que se adaptan a las preferencias de la audiencia.
- Ejemplo: “Haz un poema a la luna”
- Respuesta: “La luna se puede tomar a cucharadas…o como una cápsula cada dos horas. Es buena como hipnótico y sedante y también alivia”.
- Expansión del contexto enriquecimiento de la información a la Inteligencia Artificial para mejorar la comprensión usando los métodos de las 5W y 1H, que refiere a 5 preguntas (que en inglés empiezan con W): Quién, Qué, Dónde, Cuándo, Por qué); y a 1 H, que es el Cómo (How) sobre un tema.
- Ejemplo: “Es bueno comer Betabel?”
- Respuesta: “Quiénes: la mayoría de las personas pueden comer Betabel; Qué: “El Betabel o Remolacha refiere a un tubérculo comestible de rojo intenso…”
- Resumen de contenidos con enfoque específico consiste en dirigir la atención de la IA a aspectos concretos de la instrucción, con un énfasis particular. Se puede destacar qué elementos deben priorizarse en el modelo, para que el resumen refleje la esencia del enfoque.
- Ejemplo: “guía completa sobre técnicas de optimización de sitios web, pero sólo quiero las estrategias de optimización para móviles.”
- Respuesta: “Los aspectos clave son: Caché móvil- activar esta opción permite…; Lista de User Agents Móviles- si la función de Caché móvil está activada…”
- Rellenar plantillas para crear contenidos versátiles y estructurados. Se usa una plantilla con marcadores de posición para personalizar prompts en diferentes instrucciones, manteniendo una coherencia. Los content managers o desarrolladores web usan esta estrategia para crear fragmentos de contenido personalizados, que han sido generados por IA en sus sitios web. Un ejemplo es usar una plantilla estándar para cotizar, haciendo que IA complete datos de cliente, productos, precios, etc. Otro ejemplo es la automatización de correos personalizados desde una plantilla con una estructura general – desde el saludo, texto principal, despedida (‘Hola {Nombre}, Gracias por solicitar nuestro {Servicio}…{Cierre}».
- Personalización de Prompt o Prompt Reframing permite cambiar la redacción de las preguntas manteniendo la intención original de la consulta. Se puede diseñar el modelo lingüístico para dar varias respuestas que respondan a la consulta original de diferentes maneras. Esto puede hacerse con sinónimos o reformulación de preguntas.
- Ejemplo: “Prompt original: ¿cuáles son las formas de reducir la latencia en la red? Prompt reformulado: ¿puede enumerar técnicas para optimizar la velocidad en la red?”.
- Combinación de Prompts consiste en fusionar diferentes prompt o preguntas en una misma instrucción para obtener una respuesta completa.
- Ejemplo: “¿Puedes explicar las diferencias entre el hosting compartido y el hosting VPS y recomendar cuál es mejor para un pequeño sitio web de comercio electrónico?”.
- Respuesta: “Hosting compartido y hosting VPS son dos tipos de servicios de alojamiento…Hosting Compartido: …”
- Cadena de Pensamiento o Chain-Of-Thought Prompting usa interacciones de IA en tiempo real para guiar hacia respuestas más precisas y completas. No se basa en una sola pregunta, sino en una secuencia de preguntas o ejemplos asociados con la finalidad de profundizar sobre la consulta original. Para ello, hay que dividir una consulta o un tema complejo en secciones más pequeñas. Luego, estas partes se presentan como una secuencia de consultas que se desarrollan unas sobre otras, para conducir a IA hacia una respuesta deseada.
- Ejemplo: “¿Cuál es el tema principal?… ¿Con qué objetivo?… ¿Quién es la audiencia?…”
- Prompting iterativo consiste en hacer consultas de seguimiento a partir de respuestas anteriores para profundizar un tema, obtener información adicional o aclarar alguna ambigüedad sobre el resultado inicial. En esta técnica, se requiere expertos en procesamiento del lenguaje natural (Natural Language Processing) para diseñar prompts iterativos y elaborar respuestas parecidas a las realizadas por un ser humano.
- Ejemplo: “¿Cuáles son las mejores películas de 2022?”
- Respuesta: “’Drive My Car’ de Ryûsuke Hamaguchi; ‘El callejón de las almas perdidas’ de Guillermo del Toro; ‘The Banshees of Inisherin’ de Martin McDonagh; ‘Holy Spider’ de Ali Abbasi…”
- Storytelling interactivo y juegos de rol aprovecha la capacidad de IA para adaptar respuestas en función de los prompts e interacciones anteriores, desarrollando una narración fluida.
- Ejemplo: “Prompt: Quiero empezar un ejercicio de narración colaborativa contigo. Escribiremos una historia de fantasía sobre una tierra en la que existe la magia,… El personaje será….”
- Respuesta: “En las sombras de un bosque existía…”
- Inyección implícita de información la particularidad de esta técnica es que se otorga un contexto sutilmente para que IA entienda las necesidades sin necesidad de expresarlo explícitamente.
- Ejemplo: “¿Puedes mencionar las mejores prácticas de Modernización de un datacenter?”
- Respuesta: “1- Eleve la temperatura de funcionamiento de su centro de datos; 2- Actualice los servidores y sistemas para una mejor consolidación y eficiencia”.
- Traducción de idiomas con matices contextuales generación de contenidos multilingües, más allá de traducir palabras de un idioma a otro, considerando el contexto cultural o situación para una traducción más precisa y natural.
- Ejemplo: “Traduce la frase «She took the ball and ran with it» del inglés al francés, teniendo en cuenta que se trata de una metáfora empresarial para referirse a tomar las riendas de un proyecto.”
- Respuesta: “Elle a pris le ballon et a foncé avec”, considerando la idea de tomar la iniciativa de un proyecto.”
Adicional a éstos, podemos mencionar a la Ingeniería de prompt automática, donde la ingeniería automática de prompts (Automatic Prompt Engineering, APE) es un avance en inteligencia artificial que aprovecha los LLM para ayudar a la IA a generar y seleccionar automáticamente instrucciones por sí misma. Los pasos principales son:
- Asigna al chatbot una tarea específica y muestra algunos ejemplos.
- Al chatbot se le ocurren diferentes maneras de hacer el trabajo, por razonamiento directo o teniendo en cuenta tareas similares que conoce.
- A continuación, se prueban en la práctica estos distintos métodos.
- El chatbot valora la eficacia de cada método.
- La IA elegirá entonces un método mejor y lo aplicará.
Con Machine Learning, las herramientas de IA Generativa pueden agilizar las tareas, desde el análisis de datos en un contexto hasta la atención automatizada al cliente, sin necesitar constantes prompts generados por los humanos.
Cabe mencionar que en Prompt Engineering es importante considerar aspectos técnicos básicos como Temperatura y lo que llamamos Muestreo Top-K, para mejorar la calidad y diversidad del contenido generado por IA, al influir en el proceso de selección de tokens (palabras o subpalabras) del modelo:
- Temperatura un valor de temperatura más alto (p. ej., 1,0 o superior) dará como resultado un texto más diverso y creativo, mientras que un valor más bajo (p. ej., 0,5 o menos) producirá resultados más centrados y deterministas. Para ello, se recomienda fomentar la creatividad con base en valores de temperatura más altos al generar escritura creativa, sesiones de lluvia de ideas o explorar ideas innovadoras. También se recomienda mejorar la coherencia, optando por valores de temperatura más bajos con contenido bien estructurado, coherente y enfocado, como documentación técnica o artículos formales.
- El muestreo Top-k es otra técnica recomendada en la generación de texto de IA para controlar el proceso de selección de tokens del modelo, desde un conjunto restringido de k tokens más probables. Un valor k más pequeño (por ejemplo, 20 o 40) dará como resultado un texto más enfocado y determinista, mientras que un valor k más grande (por ejemplo, 100 o 200) producirá resultados más diversos y creativos. Las aplicaciones del muestreo top-k incluyen impulsar la diversidad de contenido, usando valores k más grandes al generar contenido que requiera una amplia gama de ideas, perspectivas o vocabularios. También consiste en garantizar resultados enfocados, eligiendo valores k más pequeños, generando contenido que requiere un alto grado de concentración, precisión o coherencia.
Para implementar las técnicas de Temperatura y Muestreo Top-k, se recomienda la Experimentación (probando varias combinaciones de temperatura y valores top-k para identificar la configuración óptima para tareas o contenidos) y el Ajuste Secuencial, durante el proceso de generación de texto para controlar el comportamiento del modelo de IA en diferentes etapas. Por ejemplo, comience con una temperatura alta y un valor k grande para generar ideas creativas, luego cambie a valores más bajos para un posterior refinamiento y enfoque.
Por último, se recomienda la aplicación de los gradientes descendentes que consisten en un algoritmo de optimización para minimizar una función objetivo y calculan la tasa de cambio o gradiente de la función de pérdida. En Machine Learning esta función objetivo suele ser la función de pérdida para evaluar el rendimiento del modelo. Los parámetros se actualizan iterativamente utilizando los gradientes descendentes hasta que se alcanza un mínimo local.
¿Por qué la Ingeniería de Preguntas es Importante?
La rapidez con la que funciona ChatGPT de OpenAI desde 2022 es abrumadora, hoy está siendo usada por millones de personas, como una forma de inteligencia artificial conversacional, partiendo de algoritmos avanzados de aprendizaje profundo (Deep Learning) para comprender el lenguaje humano.
Actualmente, las organizaciones utilizan diversas técnicas de inteligencia artificial, tales como el procesamiento del lenguaje natural (Natural Language Processing), la ingeniería de preguntas, las redes neuronales artificiales (Artificial Neural Network, NN), el aprendizaje automático (Machine Learning) y el proceso de decisión de Markov (Markov Decision Processing, MDP) para automatizar varias tareas.
La importancia de la Ingeniería de Preguntas radica en que mejora la experiencia del cliente y las interacciones entre personas e IA, además de que contribuye a construir mejores sistemas de IA conversacionales. Estos sistemas de IA conversacionales dominan y dominarán el mercado en los próximos años al utilizar LLM en forma coherente, relevante y preciso. Solo para tener un punto de referencia, tenemos que ChatGPT alcanzó los 100 millones de usuarios activos en cuestión de semanas después de su lanzamiento.
Para los desarrolladores, la Ingeniería de Preguntas ayuda a comprender cómo los modelos basados en IA llegan a las respuestas esperadas y también obtienen información precisa del funcionamiento de los modelos AI en el back-end. Desde luego, se necesitará el desarrollo de prompts que abarquen diversos temas y escenarios. Otros beneficios que podemos mencionar son: que la Ingeniería de Preguntas y el contexto de la síntesis texto-imagen, permiten personalizar las características de la imagen (el estilo, la perspectiva, la relación de aspecto, el punto de vista y la resolución de la imagen).También, desempeña un papel importante en la identificación y mitigación de los ataques de inyección de prompt, protegiendo así los modelos de IA de posibles actividades maliciosas.
Evolución de la Ingeniería de Preguntas
Natural Language Processing (NLP), es parte de IA que ayuda a percibir, como dice su nombre, el “lenguaje natural” usado por los humanos, facilitando la interacción entre personas y computadoras, gracias a que puede comprender palabras, frases y oraciones. También comprende el procesamiento sintáctico (significado de las palabras y vocabulario) y semántico (comprensión dentro de una frase o combinación de frases). Las primeras luces de NLP se vieron en los años 50, cuando se comenzaron a adoptar métodos basados en reglas, que consistían más que nada en la traducción automática. Su aplicación se dio en el análisis de palabras/oraciones, respuesta a preguntas y traducción automática. Hasta la década de los 80, aparece la gramática computacional como campo activo de investigación. Se tuvo más disponibilidad de herramientas y recursos gramaticales, lo que impulsó su demanda. Hacia los años 90, el uso de la web generó un gran volumen de conocimiento, lo que impulsó a los métodos de aprendizaje estadístico que requerían trabajar con NLP. AL 2012, entra en la arena Deep Learning como solución para el aprendizaje estadístico, produciendo mejoras en los sistemas de NLP, profundizando los datos sin procesar y aprendiendo de sus atributos.
Al 2019, surge el Transformador Generativo Pre-entrenado (GPT) como un avance notable en el dominio del procesamiento del lenguaje natural, ya que con ello es posible entrenar previamente modelos de lenguaje a gran escala para enseñar a los sistemas IA cómo representar palabras y oraciones en un contexto. Esto permitió el desarrollo de máquinas que pueden comprender y comunicarse utilizando el lenguaje de una manera muy similar a la de los seres humanos. Su aplicación más popular es ChatGPT, el cual obtiene información de textos publicados desde el año 2021 en Internet, incluyendo noticias, enciclopedias, libros, páginas web, entre otros, pero carece de la capacidad para discriminar qué información es cierta y cuál no lo es. Precisamente por ello, la Ingeniería de Preguntas surge como un método para optimizar el procesamiento del lenguaje natural en IA y mejorar la precisión y calidad de sus respuestas.
El Arte y la Ciencia de Crear Preguntas
Un prompt es en sí un texto que se incluye en el modelo de lenguaje (Language Model, LM), y la Ingeniería de Preguntas es el arte de diseñar ese texto para obtener el resultado deseado, con calidad y precisión. Esto implica adaptar la entrada de datos para que las herramientas impulsadas por IA puedan comprender la intención del usuario y obtener las respuestas claras y concisas. Lo cual nos indica que el proceso debe ser eficaz para garantizar que las herramientas impulsadas por la IA no generen respuestas inapropiadas y sin sentido, especialmente cuando las soluciones GPT se basan más que nada en la frecuencia y asociación de palabras, pudiendo arrojar resultados incompletos o erróneos.
Para crear Preguntas en herramientas de IA Generativa, se recomienda seguir esta guía esencial:
- Comprender el resultado deseado
Una Ingeniería de Preguntas exitosa parte de saber qué preguntas hacer y cómo hacerlo de manera efectiva. Por lo que el usuario debe tener claro lo que quiere en primer lugar: objetivos de la interacción y un esquema claro de los resultados previstos (qué obtener, para qué audiencia y cualquier acción asociada que el sistema deba realizar).
- Recordar que la forma importa
Los sistemas de IA funcionan con base en solicitudes simples y directas, mediante oraciones informales y un lenguaje sencillo. Pero las solicitudes complejas se beneficiarán de consultas detalladas y bien estructuradas que se adhieran a una forma o formato coherente con el diseño interno del sistema. Eso es esencial en la Ingeniería de Preguntas, ya que la forma y el formato pueden diferir para cada modelo, y algunas herramientas puede existir una estructura preferida que implique el uso de palabras clave en ubicaciones predecibles.
- Hacer solicitudes claras y específicas
Considere que el sistema solo puede actuar en función de lo que puede interpretar a partir de un mensaje determinado. Por lo que hay que formular solicitudes claras, explícitas y procesables y comprender el resultado deseado. A partir de ello, luego se debe trabajar para describir la tarea por realizarse o articular la pregunta que debe responderse.
- Estar atento a la longitud
Los prompts pueden estar sujetos a un número mínimo y máximo de caracteres. Aun cuando hay interfaces de IA que no imponen un límite estricto, las indicaciones extremadamente largas pueden resultar difíciles de manejar para los sistemas de IA.
- Elegir las palabras cuidadosamente
Como cualquier sistema informático, las herramientas de IA pueden ser precisas en el uso de comandos y el lenguaje, sin saber cómo responder a comandos o lenguaje no reconocidos. Se recomienda evitar la ambigüedad, metáforas, modismos y jerga específica para no producir resultados inesperados e indeseables.
- Plantear preguntas o solicitudes abiertas
El propósito de IA Generativa es crear. Las preguntas simples de Sí o No son limitantes y con posibles resultados breves y poco interesantes. Las preguntas abiertas permiten más flexibilidad.
- Incluir contexto
Una herramienta de IA generativa puede cumplir con una amplia gama de objetivos y expectativas, desde resúmenes breves y generales hasta exploraciones detalladas. Para aprovechar esta versatilidad, los prompts bien diseñados incluyen un contexto que ayuda al sistema de IA a adaptar su salida a la audiencia prevista.
- Establecer objetivos o límites de duración de la producción
Aunque la IA generativa pretende ser creativa, a menudo es aconsejable incluir barreras en factores como la duración de la salida. Los elementos de contexto en las indicaciones pueden incluir, por ejemplo, solicitar una respuesta simplificada y concisa versus una respuesta larga y detallada. También considere que los modelos de procesamiento de lenguaje natural, como GPT-3, están entrenados para predecir palabras basándose en patrones del lenguaje, no para contarlas.
- Evitar términos contradictorios
Derivado también de prompts largas y se puede incluir términos ambiguos o contradictorios. Se recomienda que los ingenieros de Prompt revisen la formación de Prompt y garantizar que todos los términos sean coherentes. Otra recomendación es usar un lenguaje positivo y evitar el lenguaje negativo. La lógica es que los modelos de IA están entrenados para realizar tareas específicas, no para no hacerlas.
- Utilizar la puntuación para aclarar indicaciones complejas
Al igual que los humanos, los sistemas IA dependen de la puntuación para ayudar a analizar un texto. Los prompts de IA también pueden hacer uso de las comas, las comillas y los saltos de renglón para ayudar al sistema a analizar y operar en una consulta compleja.
En cuanto a imágenes, se recomienda considerar su descripción, el ambiente y ánimo en su contexto, colores, luz, realismo.
Cómo Funciona la Ingeniería de Preguntas
La Ingeniería de Preguntas es propiamente una disciplina para impulsar y optimizar el uso de modelos de lenguaje en IA, mediante la creación y prueba de entradas de datos, con diferentes oraciones para ir evaluando las respuestas obtenidas, a base de ensayo y error hasta lograr el entrenamiento del sistema basado en IA, siguiendo estas tareas fundamentales:
- Especificar la tarea: definición de un objetivo en el modelo de lenguaje, lo cual puede implicar tareas relacionadas con NLP como complementación, traducción, resumen de texto.
- Identificar entradas y salidas: definición de las entradas que se requieren en el modelo de lenguaje y las salidas o resultados deseados.
- Crear prompts informativos: creación de prompts que comunican claramente el comportamiento esperado en el modelo, debiendo ser claros, breves y acorde al propósito por el cual fue creado.
- Interactuar y evaluar: se somete a pruebas usando modelos de lenguaje y evaluando los resultados que se arrojan, buscando fallas e identificando sesgos para hacer ajustes que mejoren su desempeño.
- Calibrar y refinar: consiste en tomar en cuenta los hallazgos obtenidos, haciendo ajustes hasta obtener el comportamiento requerido en el modelo, alineado con los requerimientos e intenciones con el cual fue creado el prompt.
En todo este proceso, el Ingeniero de Preguntas debe tener en mente que al diseñar preguntas es fundamental ser claros y precisos. Si el mensaje diseñado es ambiguo, el modelo tendrá dificultades para responder con calidad. Al diseñar prompts se debe prestar atención a las fuentes utilizadas durante el entrenamiento previo, considerando audiencias sin sesgo por géneros y culturas, para promover el respeto y la inclusión. Lo que se recomienda es enfocarse en respuestas encaminadas a ayudar, aprender y brindar respuestas neutrales y basadas en hechos.
También, se recomienda la aplicación de Juego de roles en que se crea un escenario donde el modelo asume un rol e interactúa con otra entidad. Por ejemplo, si se quiere crear una reseña de productos, se puede asumir el rol de un cliente que ha probado un producto y que escribe su experiencia satisfactoria.
El Rol de un Ingeniero de Preguntas
Un Ingeniero de Preguntas es el responsable de diseñar, desarrollar, probar, depurar, mantener y actualizar aplicaciones de IA, en estrecha colaboración con otros desarrolladores de software para garantizar que el software responda y funcione de manera eficiente. En su función se requiere creatividad y atención al detalle para elegir palabras, frases, símbolos y formatos correctos que guíen al modelo IA en la generación de textos relevantes y de alta calidad. Este rol emergente ha cobrado mayor relevancia en la necesidad de que IA contribuya a mejorar y agilizar los servicios ante el cliente y en forma interna. Ahora, si nos preguntamos quiénes puede ser Ingenieros de Preguntas, no solo para agilizar sus tareas sino para desarrollarse profesionalmente, podemos decir que pueden ser los investigadores e ingenieros de IA, los científicos y analistas de datos, los creadores de contenido, ejecutivos de atención al cliente, personal docente, profesionales de negocios, investigadores. Se espera que la demanda de Ingenieros de Preguntas crezca en la medida que las organizaciones requieran de personas que sepan manejar las herramientas impulsadas por IA.
El Futuro de la Ingeniería de Preguntas
Se prevé que las tendencias hacia un futuro de la Ingeniería de Preguntas estará vinculada a la integración con la realidad aumentada (RA) y la realidad virtual (RV), en el sentido que la adecuada aplicación de prompts puede mejorar las experiencias inmersivas de RA/VR, optimizando interacciones de IA en entornos 3D. En los avances de la Ingeniería de Preguntas es posible que los usuarios conversen con personajes de IA, soliciten información y emitan órdenes mediante el lenguaje natural en entornos simulados y en tiempo real. Esto parte de que, con la Ingeniería de Preguntas, se puede dotar a IA de un contexto o situación, una conversación y el intercambio del ser humano con aplicaciones de RA/VR, ya sea de uso espacial, educacional, de investigación o exploración.
Otra de las previsiones del uso de la Ingeniería de Preguntas es la posibilidad de lograr una traducción simultánea en lenguas habladas y escritas, aprovechando los contextos en varios idiomas para que la IA traduzca bidireccionalmente en tiempo real y en la forma más fidedigna posible. El impacto de esto es la comunicación en contextos empresariales, multiculturales, diplomáticos y personales, tomando en cuenta los dialectos regionales, los matices culturales y los patrones del habla.
En cuanto a la creatividad interdisciplinar, la Ingeniería de Preguntas puede impulsar a IA para generar arte, historias, obras y música, combinándose con la creatividad humana. Desde luego, esto puede tener implicaciones éticas, aunque también se democratiza el acceso de IA con fines artísticos.
Desde luego, a medida que la Ingeniería de Preguntas va madurando, se plantean cuestiones sobre equidad, respeto y alineación con los valores morales, desde la propia formulación de la consulta hasta el tipo de respuestas que pueden derivarse. Hay que tener en mente que en el futuro de IA y la Ingeniería de Preguntas, la tecnología siempre será un reflejo de las personas.
Desafíos y Oportunidades
Como hemos visto, la Ingeniería de Preguntas representa la oportunidad de desarrollar Preguntas bien diseñadas que mejoren la funcionalidad de la IA, en forma más eficiente y efectiva. La ventaja de esto es que se pueden agilizar tareas cotidianas, además de ampliar el conocimiento en diversos temas e impulsar la creatividad. Se fomenta también la inclusión cuando se implementa adecuadamente, con un impacto positivo en las experiencias de género.
La otra cara de la moneda son las preguntas mal diseñadas que pueden resultar en respuestas de IA con sesgos, prejuicios o datos erróneos. De ahí que las consideraciones éticas en la Ingeniería de Preguntas pueden mitigar estos riesgos, sin comprometer la equidad, el respeto y la inclusión. También, la falta de aplicación de mejores prácticas, incluso por profesionales en la materia, podrían no lograr el resultado deseado en el primer intento y resultar difícil de encontrar un punto adecuado para iniciar el proceso.
Asimismo, puede ser difícil controlar el nivel de creatividad y singularidad del resultado. A menudo, los profesionales de Ingeniería de Preguntas pueden proporcionar información adicional en el mensaje que puede confundir al modelo de IA y afectar la precisión de la respuesta.
Conclusiones
En la economía digital, las experiencias más memorables serán aquéllas en que se aprovechan los datos y se combinan con el conocimiento humano para así anticiparse a las necesidades del cliente, con empatía y personalización. En este entorno, la IA se convierte en el colaborador digital, no solo como punto de contacto con el cliente, sino que también como impulsor de productividad en la organización. Cierto es que GPT ha ganado tracción en una búsqueda de mayor acercamiento al cliente; sin embargo, se basa en frecuencia y asociación de palabras, careciendo de la capacidad para discriminar la información correcta de la incorrecta. Es en esta necesidad de mejorar la calidad de respuestas que la Ingeniería de Preguntas toma relevancia para desarrollar y optimizar los modelos de lenguaje natural de IA y obtener calidad y precisión en sus respuestas, basándose en una mayor comprensión de la intención del usuario. Sin duda alguna, la demanda del Ingeniero de Preguntas crecerá confirme las organizaciones requieran de profesionales que sepan comprender la naturaleza de las herramientas basadas en IA.
Claro es que, conforme la adopción de la Ingeniería de Preguntas madure se seguirán planteando cuestiones de equidad, respeto y alineación con los valores morales en la formulación de los prompts y los resultados, por lo que se requiere de técnicas adecuadas para lograr su implementación sin sesgos o prejuicios. Para emprender este viaje a la Ingeniería de Preguntas, se recomienda acompañarse por un socio de tecnología que transmita a su equipo las mejores técnicas y prácticas para su implementación.

por Olivia Díaz | Last updated Feb 23, 2024 | Control Remoto
Parecería que la línea de la ciencia ficción y la realidad está cada vez más borrosa. Esto ya no lo vemos solo en el cine y los juegos, sino en el comercio electrónico, la educación, el entretenimiento, la capacitación del personal, el diagnóstico remoto o proyectos arquitectónicos. Hoy la Realidad Virtual y la Realidad Aumentada están cambiando la forma en que usamos las pantallas al crear nuevas experiencias, más interactivas e inmersivas. Pero… ¿Cómo definimos la Realidad Virtual y la Realidad Aumentada?
La Realidad Virtual (Virtual Reality o VR) refiere a un entorno artificial creado con hardware y software, presentado al usuario de tal manera que parece y se siente como un entorno real. Para “ingresar” a una realidad virtual, el usuario se pone guantes, auriculares y gafas especiales, desde los cuales se recibe información del sistema informático. Además de proporcionar información sensorial al usuario (tres de los cinco sentidos: tacto, oído y visión), los dispositivos también monitorean las acciones del usuario.
Para la Realidad Aumentada (Augmented Reality o AR) se utiliza tecnología capaz de insertar elementos digitales en entornos del mundo real para ofrecer a consumidores y profesionales una experiencia híbrida de la realidad. Aun cuando la Realidad Aumentada es compatible con diversos dispositivos, es más popular en las aplicaciones de teléfonos inteligentes, con interacciones en tiempo real. De hecho, la mayoría de las herramientas de RA actuales están orientadas al consumidor, aunque las organizaciones comienzan a adoptar la RA en procesos, productos y servicios comerciales.
Si bien RA es distinta de la VR, ambas innovaciones representan un campo de tecnología denominado realidad extendida (XR), que engloba todos los entornos, reales y virtuales, representados por gráficos de ordenador o dispositivos móviles. El objetivo de XR es combinar realidades físicas y virtuales hasta conseguir que el usuario no sea capaz de distinguirlas, además de estar al alcance de cualquier persona para mejorar la vida de los usuarios.
La importancia de entender cada realidad (RA y RV) es el potencial de alterar el panorama digital en la vida y los negocios, transformando la forma en que nos comunicamos e interactuamos con la información y cambiando la forma en que pueden operar diversas industrias. Vemos esto con más detalle a continuación.
Realidad Aumentada (AR)
Esta realidad incorpora contenido virtual en el mundo físico para mejorar la percepción y la interacción del usuario con un entorno real. AR se experimenta con teléfonos inteligentes, tabletas o gafas AR, que proyectan objetos virtuales, texto o imágenes para que los usuarios puedan interactuar simultáneamente con elementos virtuales y físicos.
Por ejemplo, una cámara del dispositivo registra el entorno del usuario y los giroscopios y acelerómetros monitorean la orientación y ubicación de la cámara. El software de RA analiza la transmisión de la cámara, que identifica objetos y características del entorno. A partir de ahí, el usuario puede interactuar con objetos virtuales mediante pantallas táctiles, gestos y comandos de voz. Por ejemplo: desde una Tablet, se puede consultar sugerencias para quien visita una ciudad. En pantalla se presentan lugares para comprar, comer, visitar un museo, etc., basándose en las preferencias del usuario.
En el piso de producción de una empresa de manufactura, a través de lentes y software de AR, el ingeniero de mantenimiento puede obtener información sobre el estado de salud de un equipo, de manera que puede tomar decisiones en tiempo real y en forma más proactiva.
Otro ejemplo podemos verlo en el diseño de espacios y arquitectura. Desde una lente se puede obtener una imagen de cómo se vería el proyecto concluido para plantear el proyecto ejecutivo ante los inversores o detectar mejoras en el diseño y/o impacto en el entorno.
Funcionamiento y ejemplo de Realidad Virtual (VR)
Dentro de lo que es la Realidad Extendida, la realidad virtual es la forma más popular. Los usuarios usan auriculares o gafas de realidad virtual (wearables o dispositivos que se pueden llevar puestos) que tienen sensores para rastrear movimientos y permitirles explorar entornos virtuales generados por computadora, así como también para interactuar con objetos y participar en diversas actividades que se muestran en pantallas o lentes.
En VR, los usuarios ven imágenes tridimensionales (3D) que crean la sensación de profundidad e inmersión, mientras que el audio espacial mejora la experiencia a través de auriculares, altavoces o bocinas. También hay que comprender que la experiencia inmersiva es un formato cuyo objetivo es “sumergir” completamente a la persona en un entorno o contexto específico real o virtual.
Una de las aplicaciones más difundidas de VR es en los juegos, en que los usuarios interactúan directamente con el juego a través de dispositivos como lentes, cinturones, guantes y otros complementos que mejoran la experiencia del jugador.
En las industrias, VR puede apoyar en el diseño y capacitación con elementos que podrían ser de riesgo para el operador en una etapa de inducción. También se reducen riesgos en el análisis de diseño de productos o construcción y arquitectura.
En el campo de la salud, VR ha contribuido en mejoras en el diagnóstico de enfermedades tanto físicas como mentales, capacitación de personal médico, aplicación de la telemedicina, educación del paciente sobre su padecimiento, la gamificación (que traslada la mecánica de los juegos al ámbito educativo-profesional) en terapias de recuperación o rehabilitación. Algo muy importante en VR es que el contenido inmersivo es tan importante como el hardware desde el cual el usuario tiene interacciones. Sin hardware, no existe un “entorno simulado” al que se pueda dar vida.
Para llegar a lo que hoy entendemos con VR, en 1961, se construyó lo que se considera el primer casco de realidad virtual (por los científicos Corneau y Bryan), basado en un sistema de sensores magnéticos, incorporando los elementos de la realidad virtual: aislamiento, libertad de perspectiva y una experiencia sensorial inmersiva. Un año después, Morton Heilig presentó el Sensorama, que reproducía contenido audiovisual. El usuario encajaba la cabeza en un aparato especialmente diseñado para vivir una experiencia tridimensional donde incluso se reproducían olores. Fue un dispositivo mecánico, anterior a la electrónica digital. En 1965, Ivan Shuterland, sentó las bases de un sistema multisensorial basado en un ordenador. En 1968, Shutherland creó el primer casco de VR o head-mounted display (HMD) para su uso en simulaciones inmersivas. Los gráficos que comprendían el entorno virtual en el que se encontraba el usuario consistían en simples habitaciones de modelos renderizadas a partir del algoritmo wireframe (una representación visual de lo que los usuarios verán y con lo que interactuarán). A este dispositivo se le denominaba The Sword of Damocles (el casco era tan grande que necesitaba ser suspendido del techo).
Con el tiempo, se fueron realizando avances, hasta que en los 80 y 90, las empresas de juegos Sega y Nintendo desarrollaron sistemas de juegos de realidad virtual. En 2009, surgieron las gafas Oculus Rift en un proyecto de Palmer Luckey, para desarrollar dispositivos en la industria de los videojuegos. Hasta la década de 2010 las empresas Oculus y HTC Vive introdujeron cascos de realidad virtual de alta calidad, pudiendo aprovechar potentes gráficos y tecnología de seguimiento de movimiento. Recientemente, Apple, con Vision Pro, y Meta, con Oculus Go auriculares, han generado una gran expectación sobre el uso de VR.
En cuanto a los orígenes de AR, en 1974, Myron Kruger, investigador informático y artista, construyó un laboratorio en la Universidad de Connecticut llamado ‘Videoplace’ que estaba enteramente dedicado a la realidad artificial. Dentro de estas paredes, se utilizó tecnología de proyección y cámara para emitir siluetas en pantalla que rodeaban a los usuarios para una experiencia interactiva. Luego, AR fue saliendo de los laboratorios para su uso en diversas industrias y aplicaciones comerciales. En 1990, Tom Caudell, investigador de Boeing, acuña el término “realidad aumentada”. En 1992, Louis Rosenburg, investigador del Armstrong’s Research Lab de USAF, creó “Virtual Fixtures”, que fue uno de los primeros sistemas de realidad aumentada completamente funcionales. El sistema permitió al personal militar controlar virtualmente y guiar la maquinaria para realizar tareas como entrenar a sus pilotos de la Fuerza Aérea de EE. UU. en prácticas de vuelo más seguras.
En 1994, Julie Martin, escritora y productora, llevó la realidad aumentada a la industria del entretenimiento con la producción teatral titulada Dancing in Cyberspace. El espectáculo contó con acróbatas bailando junto a objetos virtuales proyectados en el escenario físico.
En 1998, Sportsvision transmitió el primer juego de la NFL en vivo con el sistema gráfico virtual 1st & Ten, también conocido como el marcador de yardas amarillo. La tecnología mostraba una línea amarilla superpuesta en la parte superior de la transmisión para que se pudiese ver rápidamente hacia dónde avanzó el equipo para obtener un primer intento. En 1999, la NASA creó un sistema híbrido de visión sintética para su nave espacial X-38. El sistema aprovechó la tecnología AR para ayudar a proporcionar una mejor navegación durante los vuelos de prueba.
Desde esos años hasta la actualidad, AR ha sido ampliamente adoptada en diversos ámbitos como entretenimiento, industrial, personal y diseño: la revista Esquire utilizó la realidad aumentada (2009) en los medios impresos por primera vez en un intento de hacer que las páginas cobraran vida. Cuando los lectores escanearon la portada, la revista equipada con realidad aumentada mostraba a Robert Downey Jr. hablando con los lectores. Volkswagen presentó en 2013 la aplicación MARTA (Mobile Augmented Reality Technical Assistance), que principalmente brindaba a los técnicos instrucciones de reparación paso a paso dentro del manual de servicio. Google presentó Google Glass, que es un par de gafas de realidad aumentada para vivir experiencias inmersivas. Los usuarios con tecnología AR se comunicaban con Internet mediante comandos de procesamiento de lenguaje natural, pudiendo acceder a una variedad de aplicaciones como Google Maps, Google+, Gmail y otros. En 2016, Microsoft presenta HoloLens, que son auriculares que corren en Windows 10 y es en esencia un ordenador vestible que permite a los usuarios escanear su entorno y crear sus propias experiencias en AR. En 2017, IKEA lanzó su aplicación de realidad aumentada llamada IKEA Place que cambió la industria minorista para siempre. La aplicación permite a los clientes obtener una vista previa virtual de las opciones de decoración de su hogar antes de realizar una compra.
Similitudes y Diferencias entre AR y VR
Como hemos visto, AR y VR son bastante similares y ofrecen objetos virtuales en la vida real. Sus similitudes pueden resumirse en:
- Pueden mostrar objetos ampliados y de tamaño natural y utilizan los mismos dispositivos.
- Se necesita contenido 3D.
- Se pueden usar en sus ordenadores portátiles, PC, teléfonos inteligentes, etc.
- Existe el seguimiento de movimiento de manos, ojos, dedos y más.
- Se ofrece inmersión.
Sin embargo, hay diferencias que podemos resumir como sigue:
|
Realidad Aumentada
|
Realidad Virtual
|
|
Utiliza un escenario del mundo real para colocar un elemento u objeto virtual que se puede ver a través de una lente. AR aumenta la escena del mundo real
|
Todo es completamente virtual, incluso el entorno. VR es un entorno virtual completamente inmersivo
|
|
Los usuarios pueden controlar sus mentes y su presencia en el mundo real. El usuario puede sentir su propia presencia junto con objetos virtuales.
|
Los sistemas de VR guían a los usuarios en el entorno virtual. Los sentidos visuales están controlados por el sistema. Solo pueden sentirse los objetos, sonidos, etc., de la imagen en su vista
|
|
El usuario puede acceder a AR en su teléfono inteligente, ordenador portátil o tableta.
|
Para acceder a la realidad virtual, se necesitan auriculares.
|
|
AR mejora el mundo virtual y real y simplifica su trabajo. En AR, el mundo virtual es 25% y el mundo real es 75%
|
VR mejora la realidad ficticia. En VR, el mundo virtual es 75% y el mundo real es 25%
|
|
AR requiere mayor ancho de banda, alrededor de 100 Mbps.
|
La realidad virtual puede funcionar a baja velocidad. Se requiere alrededor de 50 Mbps de conexión.
|
|
Audiencia: para quien requiere agregar virtualidad al mundo real y mejorar tanto el mundo virtual como el real. AR detecta ubicaciones y marcadores de usuarios, así como llamadas al sistema en contenido predefinido. Es parcialmente inmersivo y abierto.
|
Audiencia: para quien necesita reemplazar toda la realidad y mejorar la realidad virtual para muchos propósitos, como juegos, marketing, etc. VR es una secuencia inmersiva de animaciones, URL, vídeos, audio. VR es completamente inmersivo y cerrado
|
En cuanto a las audiencias para las cuales se enfoca cada una, AR es para quien requiere agregar virtualidad al mundo real y mejorar tanto el mundo virtual como el real. AR detecta ubicaciones y marcadores de usuarios, así como llamadas al sistema en contenido predefinido. Es parcialmente inmersivo y abierto. Mientras que la VR es para quien necesita reemplazar toda la realidad y mejorar la realidad virtual para muchos propósitos, como juegos, marketing, etc. considerando que VR es una secuencia inmersiva de animaciones, URL, vídeos, audio. VR es completamente inmersivo y cerrado.
Ejemplos de Aplicaciones de AR y VR
Algunos ejemplos de cómo las organizaciones han adoptado AR son:
- Desarrollo de aplicaciones de traducción. Estas aplicaciones interpretan el texto, que es escaneado, de un idioma a otro.
- En la industria de los juegos, para desarrollar en tiempo real gráficos en 3D.
- Análisis y reconocimiento de un objeto o texto. Ejemplo: con captación de imagen usando Google Lens, la aplicación empezará analizar la imagen y reconocerá de qué se trata. Una vez lo haya hecho, te ofrecerá acciones a realizar que están relacionadas con el tipo de objeto o texto.
- En publicidad e impresión, se utiliza AR para mostrar contenido digital en la parte superior de las revistas.
- En diseño, como habíamos mencionado en el ejemplo de IKEA Place, mediante AR se obtiene una vista previa virtual de las opciones de decoración antes de realizar una compra. Otro ejemplo es YouCam Makeup, una aplicación gratuita que permite diseñar y crear estilos de maquillaje, peinados, retoques de rostro y cuerpo con filtros, tintes, pestañas, entre otros.
VR ha ganado impulso en diversas industrias, como:
- Las Fuerzas Armadas usan tecnología de realidad virtual para entrenar a sus soldados mostrando simulaciones de vuelo y de campo de batalla.
- Los estudiantes de medicina pueden aprender mejor con el escaneo 3D de cada órgano o de todo el cuerpo con la ayuda de la tecnología VR.
- La realidad virtual también se usa para tratar el estrés postraumático, fobias o ansiedad haciendo que los pacientes comprendan la causa real de su enfermedad y en otros escenarios de atención médica.
- Los profesionales utilizan la realidad virtual para medir el rendimiento de un deportista y analizar técnicas con el dispositivo de entrenamiento digital.
- Dispositivos basados en realidad virtual (Oculus Rift, HTC Vive, google cartoon, etc.) ayudan a los usuarios a imaginar un entorno que no existe exactamente, como una experiencia inmersiva en el mundo de los dinosaurios.
- Desde la fabricación y el embalaje hasta el diseño de interiores, las empresas pueden utilizar la realidad virtual para ofrecer a los consumidores una demostración del producto y comprender mejor lo que implica fabricarlo. Un ejemplo es Lowe’s Holoroom, mediante el cual los clientes pueden seleccionar artículos de decoración del hogar, electrodomésticos, gabinetes y diseños de habitaciones para ver el resultado final.
- La gamificación se puede implementar para involucrar tanto a los clientes como a los empleados, impulsando la inspiración, la colaboración e interacciones. Por ejemplo, en la banca personal se puede ofrecer a los clientes leales algunos beneficios o recompensas.
- En la experiencia cercana de un producto en particular, VR permite resaltar sus características más exclusivas y al mismo tiempo brindar la oportunidad de experimentar su uso. El fabricante de vehículos Volvo utilizó tecnología de realidad virtual implementada para ayudar a los clientes que no tenían fácil acceso a sus concesionarios para probar sus automóviles. Esta experiencia se proporcionó mediante el uso de los auriculares Google Cardboard VR.
Uso de AR en Dispositivos Móviles
En un inicio, parecía que AR se destinaría sólo a aplicaciones militares o juegos, pero hoy vemos que juegan un rol importante en la innovación en el mercado móvil, permitiendo a los usuarios de teléfonos y tablets inteligentes interactuar virtualmente con su entorno gracias a un mayor ancho de banda y mejor conectividad. En palabras de Mark Donovan, analista de ComScore, “…La idea de que un dispositivo móvil sepa dónde estoy y pueda acceder, manipular y superponer esa información en imágenes reales que están justo frente a mí realmente hace fluir mis jugos de ciencia ficción… Esto recién está comenzando y probablemente será una de las tendencias móviles más interesantes en los próximos años”.
Un factor importante en el mercado móvil es el GPS y las tecnologías basadas en la ubicación, que permiten a los usuarios rastrear y encontrar amigos mientras viajan o “registrarse” en ubicaciones particulares. Esa información se almacena y comparte con otros a través de la nube de Internet y puede usarse para que los especialistas en marketing pueden usarla para dar a conocer promociones o descuentos especiales, o una ciudad que promueve sus sitios de interés podría incrustar en la pantalla hechos y sobre el vecindario y las personas que vivían allí. Otros visitantes podrían dejar comentarios virtuales sobre el recorrido. En la educación, los estudiantes de biología, por ejemplo, podrían utilizar una aplicación de realidad aumentada y un teléfono inteligente para obtener información adicional sobre lo que ven mientras diseccionan una rana.
La forma en que los teléfonos inteligentes están impulsando el uso de AR, Qualcomm mostró recientemente la tecnología de realidad aumentada en sus dispositivos. Los procesadores Snapdragon de Qualcomm y un nuevo kit de desarrollo de software para teléfonos inteligentes Android han sido diseñados para proporcionar la base necesaria en la construcción y uso de tecnología de realidad aumentada en teléfonos móviles. Con Mattel, fabricante de juguetes, colaboró en la actualización virtual de un juego clásico llamado Rock ‘Em Sock ‘Em Robots. Utilizando la tecnología de Qualcomm y la cámara integrada del teléfono inteligente, los jugadores podían ver robots virtuales superpuestos en las pantallas de sus teléfonos inteligentes. Los robots aparecieron en el ring, que era un trozo de papel impreso con la imagen estática del ring y sus cuerdas. Los jugadores usaban los botones de sus teléfonos para lanzar golpes y sus robots se movían alrededor del ring mientras los jugadores rodeaban físicamente la mesa donde estaba colocada la imagen del ring. La compañía también ve el potencial en marketing, como ejemplo menciona la inserción de cupones animados encima de imágenes reales de sus productos en las tiendas, para que, cuando los consumidores pasen junto a una caja de cereales, por ejemplo, en el supermercado y miren la pantalla de su teléfono, puedan obtener un descuento instantáneo.
Ahora bien, ¿qué se necesita para la AR en dispositivos móviles? Se necesita un dispositivo de captura de la imagen real, un software que esté simultáneamente transcribiendo esta información y los elementos virtuales que van a transformar esa realidad. También existen diferentes tipologías de realidad aumentada: la que se transcribe a través de una geolocalización y la que se basa en marcadores:
- Proyección de la RA: se proyecta luz artificial sobre superficies del mundo real. Las aplicaciones de realidad aumentada, además, pueden detectar la interacción táctil de esta luz proyectada. De esta manera, la interacción del usuario se detecta por una proyección alterada sobre la proyección esperada.
- Superposición de la RA: antes de la superposición, la aplicación debe reconocer qué elemento tiene que reemplazar. Una vez conseguido, se superpone parcial o totalmente un objeto.
- Marcadores de RA: mediante una cámara o un marcador visual (un QR, por ejemplo), se distingue un marcador de cualquier otro objeto del mundo real. De este modo, la información se superpone al marcador.
- Geolocalización de RA: se basa en la geolocalización que emite el teléfono inteligente a través del GPS para conocer su posición y ubicación.
- Dispositivos para la RA: en RA es necesario contar con sensores y cámaras. El proyector, generalmente muy pequeño, permite proyectar la realidad en cualquier espacio sin necesidad de usar un teléfono móvil o una tableta para interactuar. Las gafas o los espejos también utilizan la realidad aumentada.
También tenemos 2 tipos de sensores:
- Sensores usados para Trazado (tracking): se encargan de conocer la posición del mundo real, de los usuarios y cualquier dispositivo de la solución. De esta forma se puede conseguir esa sincronización o registro entre mundo real y virtual que comentamos al dar la definición de realidad aumentada. A su vez, estos sensores los clasifica en:
- Cámara (visión por ordenador): quizá una de las tecnologías más importantes. Están también los ‘fiducial markers’, es decir, marcas en el entorno que permiten al sistema de visión y a la solución en su conjunto, no sólo observar lo que existe y su movimiento, sino también situarlo espacialmente.
- Posicionamiento (GPS): una tecnología no muy específica de la realidad aumentada pero que también sirve en ocasiones para el posicionamiento espacial.
- Giróscopos, acelerómetros, brújulas y otros: que permiten apreciar la orientación (giróscopos), dirección (brújulas) y aceleración (acelerómetros). Muchos de estos sensores vienen ya incorporados, por ejemplo, en móviles y tablets.
- Sensores para recoger información del ambiente: humedad, temperatura y otra información atmosférica. Otro tipo de informaciones posibles son el pH, tensión eléctrica, radiofrecuencia, etc.
- Sensores para recoger entradas del usuario: son dispositivos bastante comunes como botones, pantallas táctiles, teclados, etc.
Influencias cinematográficas en la percepción pública sobre VR y AR
Sin duda alguna, el cine ha sido uno de los factores que han influido en la percepción sobre la Realidad Virtual y la Realidad Aumentada. Como ejemplo, tenemos estas películas reconocidas donde estas tecnologías tuvieron un rol protagónico:
- Iron Man: Esta película es un gran ejemplo de cómo las fuerzas militares pueden utilizar la tecnología en el campo utilizando información alimentada por un ordenador central.
- Viven (They Live): es la historia de un vagabundo que descubre un par de gafas que le permiten ver la realidad de que los extraterrestres se han apoderado de la Tierra. Todo el concepto de ponerse gafas para ver lo que otros no pueden es la gran idea detrás de la AR.
- Minority Report: película futurista de ciencia ficción ambientada en 2054, cargada con tecnología AR de principio a fin. Desde la interfaz del ordenador que aparece en el aire hasta la interacción con un tablero computerizado en 3D y los anuncios que ofrecen lo que el usuario gustaría tener.
- Avatar: el personaje principal, Jake Sulley, se halla en un enorme dispositivo AR que permite a su anfitrión experimentar un nivel completamente diferente de percepción sensorial.
- Robocop: el oficial de Detroit Alex Murphy se convirtió en Robocop. Su casco está conectado con la tecnología de realidad aumentada más avanzada que le permite seguir cumpliendo su papel como oficial de policía, aunque a un nivel más impresionante.
- Wall-e: película futurista animada en 3D. Esta película de alguna manera hizo una declaración sutil de que la tecnología AR no es solo para uso exclusivo de las fuerzas del orden.
- Top Gun: los HUD que se encuentran en las cabinas de los F-14 Tomcats utilizados en la película son la verdadera razón por la que se les llama HUD. Estas cosas permitieron a los pilotos mantener la cabeza en alto en el fragor de la acción y no mirar sus paneles de instrumentos.
- Tron/Tron: Legacy: Estas dos películas profundizan en lo que podría suceder si te metieran inesperadamente en un videojuego. Aunque para muchos jugadores apasionados pueda parecer un sueño hecho realidad, las películas demuestran rápidamente que no está exento de inconvenientes.
- Virtuosity: esta película plantea lo que podría suceder si un personaje de realidad virtual fuera colocado en nuestra realidad. Existe una simulación de realidad virtual construida combinando los personajes de múltiples asesinos en serie que se abre paso en la realidad.
- Matrix: examina un mundo dominado por máquinas creadas por humanos, combinando secuencias de acción con efectos especiales innovadores. A diferencia de Skynet en la trilogía Terminator, cuyo objetivo era aniquilar a la humanidad, la inteligencia artificial en Matrix ha descubierto un propósito más útil para nuestra especie: la energía. Las máquinas hacen esto absorbiendo energía de los cuerpos mientras mantienen a las personas entretenidas en un reino de realidad virtual conocido como Matrix.
- Gamer: en la película, los usuarios controlan a convictos condenados a muerte en la vida real en el juego de Internet Slayers. Gerard Butler interpreta a uno de estos convictos y, para lograr su liberación, debe sobrevivir al juego con la ayuda de la persona que lo controla. Es una experiencia intensa y visceral que explora la frontera entre la violencia virtual y la genuina.
- Ender’s game: retrata una sociedad donde los niños son educados para ser soldados militares mediante simulaciones de realidad virtual. Es un concepto deprimente contrarrestado con imágenes vívidas y extremadamente hermosas, particularmente en los paisajes recreados.
- Ready Player One: narra cómo la realidad virtual ha cambiado las convenciones culturales gracias a una nueva tecnología llamada Oasis. Aunque comenzó como una plataforma de videojuegos, Oasis se ha expandido hasta convertirse en una forma de vida. La gente trabaja en el Oasis, los niños van a la escuela allí y las empresas intentan monetizar cada centímetro cuadrado del Oasis. En el juego, el ganador recibe las enormes riquezas de Halliday, así como la propiedad del Oasis.
Además de representar el uso de AR y VR, las películas también plantean aspectos de ética y gobierno como en toda tecnología emergente.
Desafíos Tecnológicos y Empresariales
AR y VR son tecnologías que estarán cada vez más presentes en la vida cotidiana de las personas y en el quehacer de las empresas. Desde luego, existen desafíos que las organizaciones deben considerar al momento de adoptarlas:
- Expectativas excesivas: a menudo se especula que es posible ejecutar en ambientes virtuales absolutamente todas las acciones que se pueden realizar en la realidad. Es importante efectuar todos los procedimientos necesarios para que exista coherencia entre el mundo virtual y el real.
- Desarrollo específico: considerando que debe realizarse el desarrollo de habilidades en campos específicos y según las necesidades de cada organización, con resultados definidos desde su diseño en el modelo del negocio y donde se genere un impacto positivo para la organización.
- Recursos limitados: comprensión de las limitaciones actuales en el desarrollo de mejores apps y objetos de aprendizaje con AR y VR, desde el equipamiento, el software y hardware necesarios, y el talento humano que pueda desarrollar y soportar las aplicaciones.
- Brecha tecnológica: reducción de la brecha educativo-digital entre instituciones, regiones y sectores sociales con acceso a la tecnología de AR y de VR y aquellas que aún no tienen las mismas oportunidades ni capacidades tecnológicas.
- Curva de Aprendizaje: desde el primer modelo de negocio donde se planea integrar AR y VR y la cultura organizacional que permita el desarrollo consistente y continuo de estas tecnologías.
- Aspectos transdisciplinarios: AR y VR implican aspectos transdisciplinarios desde diversas áreas del conocimiento y áreas del negocio: tecnologías de información, mercadotecnia, ventas, operaciones, recursos humanos, etc.
- Cambio acelerado: la tecnología es muy ágil y el cambio de los dispositivos electrónicos que le dan vida a este tipo de herramientas se actualiza a una velocidad acelerada, que detonan desafíos en inversiones en tecnologías que la soporten y en el talento humano que conozca estas tecnologías y que puedan implementarlas.
Otro aspecto importante en la realidad de muchos países es que los requisitos de ancho de banda y baja latencia para estas tecnologías que consumen recursos multimedia están a un nivel insuficiente, además de que las redes actuales a menudo no pueden soportar transmisiones AR y VR en alta calidad, realizar la transmisión de datos de alta velocidad, conexión estable que elimine las fluctuaciones y ofrezca una experiencia sin inconvenientes.
Futuro de la Realidad Aumentada y Virtual
Aun cuando AR y VR siguen siendo tecnologías emergentes, en un futuro se prevé tecnología más rápida, liviana y asequible. Por un lado, los avances en la tecnología de los teléfonos inteligentes (con mejores cámaras y procesadores) significarán que se podrá disfrutar de experiencias AR y VR más innovadora. También el avance en las redes inalámbricas 5G permitirán disfrutar de estas tecnologías desde cualquier lugar del mundo.
Aunque esta alta tecnología se asocia con la ciencia ficción y la industria del juego, la Realidad Virtual tiene el potencial de revolucionar varias industrias, especialmente cuando buscan formas innovadoras de aumentar su productividad, mejorar procesos y, a medida que la lejanía gana terreno, las posibilidades de la realidad virtual ayudan a lograr objetivos.
Para VR, se prevé el desarrollo de procesadores más poderosos como Oculus Quest de Meta y los auriculares 8KVR/AR de Apple. En la medida que los dispositivos sean más robustos en funcionalidad y ligeros en su uso, la adopción de esta tecnología jugará un rol importante en la creación de experiencias más inmersivas e intuitivas en todos los campos.
También Podemos mencionar algunas predicciones y mejoras en ciernes:
- LiDAR traerá creaciones AR más realistas a nuestros teléfonos. iPhone 12 y iPad Pro ahora están equipados con tecnología LiDAR LiDAR (Light Detection and Ranging) se utiliza esencialmente para crear un mapa 3D del entorno, lo que puede mejorar seriamente las capacidades AR de un dispositivo. Además, proporciona una sensación de profundidad a las creaciones de RA, en lugar de un gráfico plano.
- Los cascos de VR serán más pequeños, livianos e incorporarán más funciones. La detección de manos y el seguimiento ocular son dos ejemplos destacados de la tecnología incorporada en los cascos de realidad virtual. Debido a que la detección de manos permite a los usuarios de realidad virtual controlar los movimientos sin controladores torpes, los usuarios pueden ser más expresivos en la realidad virtual y conectarse con su juego o experiencia de realidad virtual en un nivel más profundo. Y la inclusión de la tecnología de seguimiento ocular permite que el sistema enfoque la mejor resolución y calidad de imagen solo en las partes de la imagen que el usuario está mirando (exactamente como lo hace el ojo humano). Se reduce el retraso (delay) y el riesgo de náuseas.
- Existirán nuevos accesorios XR para profundizar aún más la experiencia. La startup Ekto VR ha creado botas robóticas que brindan la sensación de caminar, para adaptarse al movimiento en los auriculares, aunque en realidad esté parado. Los discos giratorios en la parte inferior de las botas se mueven para coincidir con la dirección de los movimientos del usuario. En el futuro, accesorios como este podrán considerarse una parte normal de la experiencia de realidad virtual.
- Incluso tendremos trajes hápticos (del tacto) de cuerpo completo. Existen ya los guantes hápticos que simulan la sensación del tacto mediante vibraciones. Se plantea el traje de cuerpo entero como el TESLASUIT, que hoy no son asequibles para la mayoría de los usuarios de realidad virtual. Con el tiempo podrían reducir su costo que a su vez aumentarán su adopción.
Según las empresas encuestadas por PWC en 2022, los alumnos de realidad virtual absorben conocimientos cuatro veces más rápido que los alumnos en el aula y tienen un 275%más de confianza cuando se trata de aplicar en el mundo real las habilidades que aprendieron durante la capacitación.
En el campo laboral, el trabajo remoto es más popular que nunca, pero todavía hay aspectos de interacciones cara a cara que son difíciles de replicar. Como resultado, las herramientas de trabajo colaborativo de realidad mixta aprovecharán cada vez más la realidad virtual y la realidad aumentada para capturar y expresar los aspectos más sutiles de la interacción que no se traducen en las videollamadas.
En el comercio, que la realidad virtual y la realidad aumentada se convertirán con mayor frecuencia en parte del proceso de marketing y ventas. Las marcas invertirán en la creación de entornos virtuales donde puedan interactuar con los compradores para ayudarlos a resolver sus problemas, animándoles a dar el salto de ser clientes a ser fieles seguidores.
En la salud, desde el uso de AR para mejorar la terapia del cáncer de hígado hasta la creación de simulaciones de cirugías en realidad virtual, los sistemas de atención médica están utilizando estas tecnologías en una variedad de aplicaciones. El desarrollo continúa, debido en gran parte a la creciente demanda impulsada por más conectividad, costos en dispositivos que irán reduciéndose y la necesidad de reducir costos y riesgos en intervenciones.
Según Forbes, se estima que las inversiones mundiales en realidad aumentada crecerá de $62,75 mil millones de dólares en 2023 a $1,109,71 mil millones de dólares para 2030, a una tasa compuesta anual del 50,7%. Para la realidad virtual, Forbes estimó que las inversiones mundiales en realidad virtual (VR) alcanzaron los 59,96 mil millones de dólares en 2022 y se espera que crezcan a una tasa de crecimiento anual compuesta (CAGR) del 27,5% de 2023 a 2030. Sin duda alguna, el crecimiento a doble dígito deja claro que las organizaciones deben plantearse cómo abordar estas tecnologías emergentes para lograr resultados del negocio.
Conclusión
AR y VR son tecnologías que deben revisarse en la estrategia de Transformación Digital de las organizaciones, por las ventajas que representan, desde la visualización para los clientes sobre características destacadas de productos, la factibilidad de un proyecto o diseño; guías prácticas sobre uso de productos, demostraciones, publicidad o promociones; la formación y desarrollo de habilidades del personal sobre nuevos equipos o protocolos de seguridad mediante VR motivando el aprendizaje interactivo; la realización de reuniones o eventos virtuales que simulen la verdadera presencia de cliente y colegas; visitas virtuales a instalaciones, comercios, instituciones educativas, museos, etc.; hasta la mejor atención al cliente, con un mejor acercamiento ahorrando tiempo y recursos.
Desde luego, el uso de la realidad aumentada y la realidad virtual depende de las capacidades internas, del presupuesto y de los objetivos de la organización. Aunque ya existen en el mercado muchas aplicaciones que utilizan la realidad aumentada, la tecnología aún no se ha generalizado; sin embargo, a medida que los dispositivos, procesadores y software agreguen más potencia y sofisticación, el nivel de información que se puede agregar aumentará. AR y VR pueden ayudar a mejorar la capacidad de toma de decisiones, la comunicación y la comprensión al experimentar un escenario que es artificial pero que parece y se siente natural. Como hemos visto a lo largo de este artículo, la AR y VR tienen muchas aplicaciones en las industrias del entretenimiento, militar, de ingeniería, médica, industrial, entre otras. Una recomendación, para obtener mejores resultados es combinar ambas tecnologías haciendo un análisis de cada caso de uso sobre la adaptabilidad, la productividad, el tiempo de comercialización, el retorno de inversión y los resultados esperados. También se recomienda acercarse a un socio de tecnología de información que tenga la experiencia en su industria y comprenda sus desafíos.

por Olivia Díaz | Last updated Feb 23, 2024 | Pandora FMS
Para comprender qué es un Análisis de Causa Raíz (Root Cause Analysis o RCA), debemos partir de que una causa raíz es un factor que causó una no conformidad y debe eliminarse mediante la mejora de procesos. La causa raíz es la cuestión central y la causa de más alto nivel que pone en marcha toda la reacción de causa y efecto que, en última instancia, conduce al problema.
Situaciones que requieren análisis de raíz
Entendiendo esto, el análisis de causa raíz (Real Cause Analysis o RCA) describe una amplia gama de enfoques, herramientas y técnicas utilizadas para descubrir las causas de los problemas. Los enfoques de RCA pueden estar orientados a identificar las verdaderas causas fundamentales, algunos son técnicas generales para la resolución de problemas y otros ofrecen apoyo para la actividad central del análisis de las causas fundamentales. Algunos ejemplos de situaciones comunes donde el análisis de causa raíz puede ayudar a resolver problemáticas:
- Manufactura: un fabricante de piezas de computadora identificó que sus productos fallaban rápidamente por un fallo en el diseño en uno de los microchips. Después de llevar a cabo un RCA, se desarrolló un nuevo chip eliminando el fallo.
- Seguridad: después de que un paciente sufriera una desafortunada caída mientras estaba dentro de las instalaciones de un hospital, mediante RCA se halló que no llevaba calcetines antideslizantes. Esto llevó a definir cambios en las políticas, incluyendo calcetines antideslizantes para garantizar que todos los pacientes tengan esta nueva medida de seguridad adicional.
- Desarrollo de software: a raíz de las quejas de los clientes sobre un software que fallaba inesperadamente durante su uso, se llevó a cabo un RCA, dejando claro que sí existían errores en el diseño que causaban los fallos. La empresa aplicó nuevos procesos de prueba antes del lanzamiento de cualquier producto, mejorando la satisfacción de los clientes.
- Construcción: el RCA realizado por el retraso en la finalización de un proyecto reveló que los componentes críticos se habían entregado tarde, lo cual derivó en la definición de procesos de adquisiciones más estrictos para garantizar la entrega oportuna.
- Comercio: en una tienda minorista se observó que sus estantes estaban frecuentemente vacíos. Al realizar un RCA se descubrió que el proceso de pedidos de la tienda era inadecuado, provocando retrasos en los pedidos. Se tomó la decisión de que la tienda implementara un nuevo proceso de pedidos para evitar retrasos y mantener los estantes completamente abastecidos.
- Alimentos: un restaurante experimentaba frecuentes problemas de seguridad alimentaria. Mediante RCA se descubrió que los empleados no estaban capacitados en los procedimientos de seguridad alimentaria. El restaurante implementó la capacitación y la supervisión adicionales para garantizar el cumplimiento de las normas de seguridad alimentaria y prevenir problemas futuros.
Los enfoques más comunes para el análisis de causa raíz incluyen los cinco porqués, los diagramas de espina de pescado, el análisis de árbol de fallos (FTA), el mapeo de causa raíz y el análisis de Pareto. Más adelante veremos cada uno de estos enfoques:
¿Qué es el Análisis de Raíz?
De acuerdo con Techopedia, el análisis de causa raíz (RCA) es un método de resolución de problemas que se utiliza para identificar la causa exacta de un problema o evento. La causa raíz es la causa real de un problema específico o un conjunto de problemas. Al eliminar la causa se evita que se produzca el efecto indeseable final. Esta definición deja claro que RCA es un método reactivo, a diferencia de preventivo, ya que se aplicará sólo después de que ha ocurrido un problema para buscar su causa y evitar que vuelva a ocurrir.
La importancia de RCA para abordar las causas subyacentes radica en que es un análisis basado en procesos y procedimiento, que ayudan a guiar al analista de problemáticas o tomador de decisiones para descubrir y comprender las causas reales de los problemas y, por lo tanto, llegar a una solución práctica que prevenga la recurrencia de dicho problema.
Objetivos y Beneficios del Análisis de Raíz
RCA tiene por objetivo identificar la fuente original de un problema para evitar que vuelva a presentarse. Al abordar la causa principal, también es posible implementar acciones y medidas preventivas apropiadas. Aun cuando el acercamiento de RCA se basa en una reacción (se analiza la causa a partir de un problema que ya se presentó), existen beneficios importantes:
- Descubrimiento de causas y reacción más inmediata: RCA le permite intervenir rápidamente para solucionar un problema y evitar que cause daños generalizados. El proceso de toma de decisiones también debería mejorarse y ser más oportuno.
- Comprensión para soluciones efectivas: RCA detalla por qué ocurrió un problema y comprender los pasos involucrados en el problema. Cuantos más detalles se obtienen sobre la problemática, más fácil será comprender y comunicar por qué ocurrió el problema y trabajar en equipo para desarrollar soluciones.
- Aplicación del aprendizaje para prevenir problemas futuros: al realizar un RCA y tomar las medidas necesarias para evitar que vuelvan a ocurrir los problemas, es posible también desarrollar una mentalidad enfocada a hallar problemas en forma más proactiva.
Principios Esenciales del Análisis de Raíz
Para implementar un RCA, deben considerarse sus principios esenciales para asegurar la calidad del análisis y, lo más importante, generar confianza y aceptación del analista por parte de los interesados (proveedores, clientes, socios de negocios, pacientes, etc.) para emprender acciones específicas para eliminar y prevenir problemas. Los principios básicos de RCA son los siguientes:
- Enfoque en corregir causas, no solo síntomas, el foco es corregir y remediar las causas de raíz en lugar de sólo los síntomas.
- Importancia de tratar síntomas a corto plazo evita ignorar la importancia de tratar los síntomas de un problema para lograr un alivio a corto plazo.
- Reconocimiento de la posibilidad de múltiples causas para un mismo problema, tener en cuenta que podría haber múltiples causas raíz.
- Enfocarse en el “cómo” y “por qué”, no en el “quién”, se debe concentrar en cómo y por qué sucedió una problemática, no empeñarse en buscar a un responsable.
- Metodicidad y búsqueda de evidencia concreta para llevar a cabo un RCA se debe ser metódico y encontrar evidencias concretas de causa y efecto para respaldar las afirmaciones de causa raíz.
También se recomienda proporcionar suficiente información para definir un curso de acción correctivo y buscar cómo esta información también contribuya a la prevención de una problemática a futuro.
Por último, se recomienda siempre un enfoque integral y contextualizado, considerando que en una problemática pueden estar involucrados sistemas interdependientes.
Cómo Realizar un Análisis de Raíz Eficaz: Técnicas y Métodos
Para llevar a cabo un RCA, existen cuatro pasos esenciales:
- Identificar el problema/evento: es crucial identificar el problema o evento en cuestión e involucrar a todas las partes interesadas relevantes para comprender claramente el alcance y su impacto.
- Recopilar datos: incluye revisar la documentación, entrevistar a los involucrados en la situación, observar los procesos y analizar la información disponible para poder desarrollar una visión integral del problema o evento.
- Identificar la causa(s) raíz: aquí se utilizan varias herramientas, como la metodología de los cinco porqués, los diagramas de espina de pescado, análisis de cambio y el análisis de Pareto, para analizar los datos recopilados antes de idear las soluciones que aborden cada factor identificado. Esto podría incluir cambios/actualizaciones de procesos, capacitación del personal o la introducción de nuevas tecnologías.
- Desarrollar e implementar soluciones: monitorear la efectividad de las estrategias elegidas a lo largo del tiempo, pudiendo ajustarlas cuando sea necesario en el caso de que problemas similares vuelvan a surgir más adelante.
-
Los 5 ¿por qué?
Es la primera y más popular técnica de RCA. Este método consiste en preguntar “por qué” cinco veces hasta que se revela la causa subyacente de un problema. Se logra encontrar respuestas detalladas a las preguntas que surgen. Las respuestas se vuelven cada vez más claras y concisas. El último “por qué” debe conducir al proceso que haya fallado. Ejemplo: si una empresa de fabricación tiene muchos defectos en sus productos, entonces, mediante un análisis de cinco porqués, se podría determinar que no se ha asignado ningún presupuesto porque la dirección no lo hizo.
-
Consiste en analizar los cambios que conducen a un evento por un período de tiempo más largo y se obtiene un contexto histórico. Se recomienda este método cuando se trabaja con varias causas potenciales. Para ello, se debe:
- Hacer una lista de todas las causas potenciales que condujeron a un evento y por cada vez que se produjo un cambio.
- Se clasifica cada cambio o evento según su influencia o impacto (interno o externo, provocado o no provocado).
- Se revisa cada evento y se decide si era un factor no relacionado, correlacionado, contribuyente o causa raíz probable. Aquí se puede usar otras técnicas como los 5 porqués.
- Se observa cómo se puede replicar o remediar la causa raíz.
-
Diagrama de Espina de Pescado (Ishikawa)
Estos pueden identificar las causas principales dividiéndolas en categorías o subcausas. Por ejemplo, en los casos en los que la satisfacción del cliente en los restaurantes es baja debido a la calidad del servicio, se tiene en cuenta la calidad de la comida, el ambiente, la ubicación, etc. Estas subramas se utilizan posteriormente para analizar el principal motivo de insatisfacción del cliente. Ejemplo:
Como puede verse, el diagrama fomenta la lluvia de ideas siguiendo caminos ramificados, que se asemeja al esqueleto de un pez, hasta ver las posibles causas y tener visualmente claro cómo la solución alteraría el escenario. Para construir el Diagrama Ishikawa, en la cabeza se sitúa el problema fundamental. Después de plantear el problema fundamental, se trazan las espinas del pez. La columna vertebral será el vínculo entre las categorías de causas y el problema fundamental. La categorías comunes para este diagrama son:
- Personas involucradas en el proceso.
- Método o cómo se diseñó el trabajo.
- Máquinas y equipo utilizado en el proceso.
- Materiales y materias primas utilizadas.
- Medio ambiente o factores causales.
En las espinas, adheridas a la columna, se incluyen las categorías o grupos de causa. También se pueden unir más espinas (subcausas) a las espinas del nivel superior, y así sucesivamente. Esto hace que se visualice la relación causa-efecto.
-
Una técnica que puede ayudar a seleccionar la mejor solución para un problema cuando hay muchas soluciones potenciales, sobre todo cuando los recursos disponibles son limitados. El análisis de Pareto se deriva de la regla 80/20, que establece que el 80% de los resultados de un evento son producto del 20% de las contribuciones. Esta técnica permite a los usuarios separar una serie de factores de entrada que probablemente impongan el mayor impacto en el efecto o resultado. Entonces, si el resultado es positivo, los individuos o empresas deciden continuar con los factores. Por el contrario, los usuarios eliminan esos factores de su plan de acción si el efecto parece ser negativo.
Consejos para un Análisis de Raíz Efectivo
Para implementar un RCA, el primer paso consiste en determinar un único problema para ser discutido y evaluado. A partir de ahí, se deben seguir estos pasos para un RCA efectivo:
- Establecer el planteamiento del problema formulando preguntas clave, tales como ¿qué está mal?, ¿cuáles son los síntomas?
- Entender el problema: apoyándose en diagramas de flujo, de araña o una matriz de desempeño, trabajando en equipo y aceptando diversas perspectivas.
- Dibujar un mapa mental de la causa del problema para organizar pensamientos o análisis.
- Recopilar datos sobre el problema apoyándose en listas de verificación, muestreo, etc.
- Analizar los datos usando histogramas, diagramas de Pareto, gráficos de dispersión o diagramas de afinidad.
- Identificar la causa raíz mediante un diagrama de causa y efecto (como el diagramas de espina de pescado), los cinco porqués o análisis de sucesos.
- Definir plazos y eliminar la causa raíz.
- Implementar una solución.
Se recomienda la planificación de análisis de raíz futuros, teniendo presente los procesos, tomando notas constantemente e identificando si una técnica o un método determinados funciona mejor para las necesidades de la organización y los entornos específicos del negocio.
También se recomienda hacer un análisis de raíz en los casos de éxito. RCA es una herramienta valiosa para hallar también la causa de un resultado exitoso, la superación de objetivos trazados inicialmente o la entrega anticipada de un producto y más adelante poder replicar la fórmula del éxito. De manera que RCA también ayuda a priorizar y proteger factores clave en forma proactiva.
Como último paso, se recomienda supervisar la solución, para detectar si la solución ha funcionado o si deben realizarse ajustes.
Conclusiones
Sin duda alguna, RCA es una herramienta valiosa para identificar la fuente original de un problema que puede ser crítico para la organización y reaccionar con rapidez y eficacia, además de evitar también que vuelva a surgir la misma problemática. Más allá de un acercamiento reactivo, RCA puede ayudar a las organizaciones a implementar acciones y medidas preventivas, e incluso puede también mapear el éxito (análisis de raíz en casos de éxito) para poder replicar en un futuro los mismos factores clave que hayan conducido a la satisfacción del cliente, el logro de niveles de calidad adecuados o la entrega a tiempo de un producto.
Algo también muy importante es que RCA permite mejorar la comunicación dentro de la organización, detallando el por qué surgió un problema y qué pasos seguir para resolverlo en forma objetiva. Cuantos más detalles se tengan del contexto, existe la posibilidad de involucrar a las personas adecuadas con cursos de acción claros, con decisiones sustentadas y bien informadas.
Desde luego, existen diversas herramientas de análisis causa raíz para evaluar los datos, cada una evalúa la información con una perspectiva diferente. También, para entender un problema, hay que aceptar diversos puntos de vista y trabajar en equipo para alcanzar los beneficios de RCA.

por Ahinóam Rodríguez | Last updated Feb 23, 2024 | Control Remoto
En este artículo, abordaremos a fondo el RMM Software (Software de Monitoreo y Gestión Remota) y su papel esencial para los Proveedores de Servicios Gestionados (MSP). Explicaremos las funciones centrales del RMM, desde el monitoreo remoto hasta la gestión eficiente de dispositivos clientes, destacando sus beneficios clave como la reducción de costos laborales y la mejora de la productividad. Analizaremos la integración estratégica de RMM y PSA (Automatización de Servicios Profesionales) para potenciar los flujos de trabajo de los MSP y ofreceremos una visión del futuro, respaldada por estadísticas prometedoras. Concluimos resaltando la importancia continua del RMM en el panorama tecnológico y alentando a los MSP a considerar su implementación para optimizar la eficiencia y el éxito en la entrega de servicios gestionados.
¿Qué es el software RMM?
En el pasado todas las empresas, independientemente de su tamaño, utilizaban infraestructuras TI locales. Cuando se presentaba un problema contactaban con su proveedor de servicios y un equipo técnico acudía a las oficinas para solucionarlo. Sin embargo, el panorama cambió por completo con el desarrollo de la tecnología Cloud. La posibilidad de acceder a los datos y recursos informáticos desde cualquier lugar fue reduciendo poco a poco la dependencia de las infraestructuras TI centralizadas. El salto definitivo se produjo con la llegada del teletrabajo y del trabajo híbrido. Las organizaciones que apuestan por un marco laboral flexible tienen sus sistemas distribuidos en ubicaciones muy diversas, a menudo fuera de la red corporativa tradicional.
Por otro lado, cada departamento dentro de la empresa cuenta con necesidades tecnológicas específicas que se van adaptando con rapidez a los cambios del mercado. Gestionar todas estas aplicaciones de forma manual resultaría muy complejo, costoso y podría dar lugar a errores humanos que ponen en riesgo la seguridad.
Está claro que para abordar estos desafíos tenían que surgir herramientas novedosas como el software RMM (Remote Monitoring and Management) que permite a las empresas mantener un control efectivo de todos sus activos TI, incluso en entornos distribuidos.
¿Cómo contribuye el software RMM a la transformación digital de las empresas?
Como acabamos de mencionar, el software RMM se ha convertido en una pieza clave para asegurar la transición hacia entornos de infraestructura descentralizada y dinámica, sin descuidar los aspectos esenciales.
Gracias a esta tecnología los profesionales TI pueden supervisar y gestionar de forma remota toda la infraestructura de una empresa, monitorear en tiempo real el rendimiento de los dispositivos IoT conectados a la red, identificar posibles amenazas o actividades anómalas y aplicar medidas correctivas.
Si bien las herramientas de gestión remota surgieron en la década de los 90, en sus inicios tenían funcionalidades limitadas y eran difíciles de implementar.
Los primeros RMM ofrecían una supervisión básica y se instalaban en cada equipo de manera individual. Luego el sistema central analizaba los datos y creaba informes o alertas sobre eventos críticos.
En cambio, el software RMM actual adopta un enfoque más integral y permite una gestión unificada y completa de la infraestructura tecnológica de la empresa ya que extrae la información de todo el entorno TI en lugar de hacerlo de cada dispositivo de manera aislada. Además, es compatible con instalaciones locales y en la nube.
Finalmente, otra contribución clave de las herramientas RMM para la digitalización consiste en pasar de un modelo de mantenimiento reactivo a un modelo de mantenimiento preventivo. Las soluciones de acceso remoto permiten a los equipos técnicos monitorear de forma proactiva los procesos de software, sistemas operativos y subprocesos de red, y abordar los posibles problemas antes de que se conviertan en situaciones críticas.
Una herramienta clave para los MSP
Un Proveedor de Servicios Administrados (MSP) es una empresa que brinda servicios de gestión y soporte tecnológico a otras empresas, desde la administración de servidores, a la configuración de redes o la gestión de activos en la nube.
A medida que las organizaciones crecen almacenan más datos y las amenazas cibernéticas también van en aumento. Muchas PYMES deciden contratar los servicios de un proveedor MSP para que se haga cargo de sus infraestructuras, sobre todo si no cuentan con un departamento TI interno que optimice la seguridad y el rendimiento de sus sistemas.
Los MSP utilizan diferentes tecnologías para distribuir sus servicios y una de las más importantes es el software RMM, que les permite supervisar proactivamente las redes y equipos de sus clientes y resolver cualquier incidencia de manera remota sin necesidad de acudir presencialmente a las oficinas.
Según datos del portal Transparency Market Research, el mercado de este tipo de software no ha parado de crecer en los últimos años y se prevé que este crecimiento siga siendo constante por lo menos hasta el año 2030 impulsado por la demanda de los MSP.
¿Cómo funcionan las herramientas RMM para la supervisión remota?
Las herramientas RMM funcionan gracias a un agente que se instala en las estaciones de trabajo, servidores y dispositivos de la compañía. Una vez instalado, se ejecuta en segundo plano y va recopilando información sobre el rendimiento y la seguridad de los sistemas.
El agente RMM monitorea continuamente la actividad de la red (uso de la CPU, memoria, espacio en disco, etc.) y si detecta cualquier anomalía genera automáticamente un ticket con información detallada sobre el problema y lo envía al proveedor MSP. Los tickets se organizan en un panel según su prioridad y se pueden cambiar de estado una vez que han sido resueltos o escalarlos a un nivel superior en los casos más complejos.
Además, las herramientas RMM crean informes periódicos sobre el estado general de los sistemas. Estos informes pueden ser analizados por los equipos técnicos para reforzar la estabilidad de la red.
¿Cómo ayuda el software RMM a mejorar la eficiencia operativa de los MSP?
El software RMM tiene una serie de utilidades prácticas que pueden aprovechar los MSP para elevar la calidad de sus servicios:
- Supervisión y gestión remota
Monitorea el rendimiento de los equipos en tiempo real y permite solucionar problemas de manera remota sin tener que ir al lugar donde se produjo la incidencia. Esto supone un ahorro de tiempo y de los costes asociados al desplazamiento.
Otra ventaja de implementar herramientas RMM es la posibilidad de contratar a los mejores profesionales sin importar su ubicación y abarcar diferentes zonas horarias ofreciendo un soporte 24/7.
- Visibilidad completa de la infraestructura TI
Gracias al software RMM los equipos técnicos pueden realizar un seguimiento de todos los activos TI de sus clientes desde un único panel de control. Por ejemplo, pueden hacer un inventario de todos los dispositivos y servicios en la nube que están activos, o comprobar en una sola vista de panel los tickets que están abiertos y los que están pendientes de resolver.
- Automatización de tareas repetitivas
Las herramientas RMM crean flujos de trabajo automatizados para tareas rutinarias como: instalar/ desinstalar software, transferir archivos, ejecutar scripts, gestionar parches y actualizaciones o realizar copias de seguridad. Esto reduce la carga de trabajo de los equipos TI y minimiza el riesgo de errores humanos.
- Mayor seguridad
El agente RMM envía alertas en tiempo real si se produce un evento crítico. De esta forma, los administradores de la red pueden identificar con mucha rapidez las amenazas de seguridad o problemas que afectan al rendimiento de los equipos.
La monitorización proactiva es fundamental para que los proveedores MSP puedan garantizar un entorno TI estable y seguro para sus clientes. Además, reduce los costos asociados a la reparación de equipos y recuperación de datos.
- Reducir los tiempos de inactividad
La instalación de nuevos programas, actualizaciones y medidas correctivas, se ejecuta en segundo plano sin interferir en la actividad de los usuarios. Esto facilita el cumplimiento de los acuerdos de nivel de servicio (SLA), al solucionar los problemas con la mayor brevedad sin que existan interrupciones prolongadas del servicio.
¿Qué aspectos deben considerar los MSP al elegir un software RMM?
Es importante optar por una solución estable, segura y fácilmente escalable que satisfaga las necesidades de los clientes. Además, lo ideal es que el software RMM elegido se integre fácilmente con otras herramientas para ofrecer una gestión más eficiente y completa.
¡Veamos algunos requisitos básicos!
- Implementación sencilla
Las herramientas RMM deben ser intuitivas para reducir el tiempo y los costes de su puesta en marcha.
- Flexibilidad
A medida que las empresas crecen, también lo hace su infraestructura TI. En el caso de los MSP, un volumen mayor de clientes significa aumentar la capacidad de monitoreo. Por eso es importante elegir una herramienta que sea flexible y escalable. De esta manera, será posible agregar nuevos dispositivos y usuarios sin limitaciones técnicas.
- Estabilidad
Verifica que el software RMM sea estable. Algunas soluciones brindan acceso remoto mediante software de terceros y esto puede afectar al rendimiento de la conexión ya que cada herramienta tiene sus propias características y velocidad de transferencia de datos. Por lo tanto, es mejor seleccionar una plataforma que ofrezca un acceso remoto integrado para optimizar la capacidad de respuesta y evitar interrupciones.
- Compatibilidad con diferentes dispositivos
La herramienta debe estar preparada para monitorear la actividad de una amplia variedad de dispositivos y sistemas informáticos compatibles con protocolos SNMP. Esto incluye, pero no se limita a, servidores, routers, switches, impresoras, cámaras IP, etc.
- Integración sin fisuras con las herramientas PSA
La integración de RMM y PSA mejora el flujo de trabajo de los MSP.
Las herramientas PSA automatizan y gestionan tareas relacionadas con la prestación de servicios profesionales como la facturación, la gestión de tickets, registro de tiempo, etc.
Por ejemplo, los problemas detectados durante la supervisión remota pueden generar tickets de forma automática en el sistema PSA para que los técnicos revisen el historial de incidencias del dispositivo y lleven un seguimiento.
Los tiempos dedicados a aplicar medidas correctivas también pueden ser registrados automáticamente por los PSA, lo que permite una facturación más precisa.
- Seguridad
Asegúrate de que el software RMM que piensas adquirir tenga las licencias adecuadas y cumpla con los estándares de seguridad. Debería proporcionar funciones como cifrado de datos, autenticación multifactor, acceso al sistema a través de VPN o bloqueo de cuentas inactivas.
- Soporte
Por último, antes de decidirte por una solución RMM comprueba que el proveedor ofrezca un buen soporte posterior a la implementación. Revisa las referencias y opiniones de otros clientes para conocer la calidad del servicio y tener la certeza de que estás haciendo una buena inversión.
Conclusión
Las PYMES están cada vez más digitalizadas y dependen de una gran variedad de programas informáticos para realizar sus operaciones diarias. A medida que las empresas migran sus infraestructuras a la nube, los proveedores MSP necesitan soluciones de acceso remoto para llevar una gestión integral de los activos de sus clientes.
Existen diferentes herramientas RMM que permiten supervisar el rendimiento de los sistemas en tiempo real y realizar acciones de soporte y mantenimiento. Una de las más completas es Pandora FMS Command Center, una versión específica de la plataforma Pandora FMS para la monitorización MSP y que ha sido diseñada para trabajar en entornos TI con un volumen alto de dispositivos. Es una solución segura y escalable que ayuda a los proveedores de servicios gestionados a reducir la carga de trabajo y expandir su cartera de clientes.
Además, cuenta con un plan de formación específico para que los equipos TI consigan aprovechar al máximo todas las funciones avanzadas del software.
Muchas empresas que trabajan con Pandora FMS Command Center ya han logrado reducir sus costes operativos entre el 40% y el 70% gracias a la automatización de tareas y a la reducción de incidencias.
Es hora de aumentar la productividad de tu negocio y ofrecerles a tus clientes un servicio excepcional. Contacta con nuestro equipo comercial para pedir un presupuesto o resolver tus dudas sobre nuestra herramienta.

por Pandora FMS team | Dec 28, 2023 | Pandora FMS
En este emocionante recorrido, celebramos los éxitos de nuestro equipo a lo largo de un año increíblemente productivo. Desde resolver 2677 tickets de desarrollo y 2011 tickets de soporte hasta dedicar 5680 horas a proyectos y operaciones, cada métrica representa nuestra dedicación y éxito compartido con nuestros valiosos clientes, quienes son el motor de nuestro crecimiento.
Reforzamos nuestro compromiso con la seguridad al convertirnos en CNA oficial en colaboración con INCIBE (Instituto Nacional de Ciberseguridad de España). Este logro de prestigio coloca a Pandora FMS, Pandora ITSM y Pandora RC como el CNA número 200 a nivel mundial y el tercer CNA en España. El reconocimiento como CNA (Common Vulnerabilities and Exposures Numbering Authority) significa que Pandora FMS ahora forma parte de un selecto grupo de organizaciones que coordinan y gestionan la asignación de CVE (Common Vulnerabilities and Exposures), identificando problemas de seguridad de manera única y colaborando en su resolución.
Durante este año, vivimos una apasionante unificación de marca. Lo que inició como Artica en Pandora FMS ha evolucionado hacia un solo nombre: Pandora FMS. Esta transición refleja nuestra consolidación como una única entidad, reforzando nuestro compromiso con la excelencia y simplificando nuestra identidad.
A nivel global, nos destacamos en eventos clave, desde el Blackhat de Riad hasta Madrid Tech Show. Además, nos expandimos a nuevos mercados, conquistando China, Camerún, Costa de Marfil, Nicaragua y Arabia Saudita.
Hemos evolucionado eHorus a Pandora RC y transformado Integria en Pandora ITSM, fortaleciendo nuestra presencia en el mercado. Inauguramos una nueva plataforma de cursos online y desarrollamos un sistema de documentación multi versión en cuatro idiomas.
Destacamos con orgullo el hito tecnológico del año: la creación del sistema MADE (Motor de Detección de Anomalías de Monitorización), resultado de nuestra colaboración con la Universidad Carlos III de Madrid. Presentado en el Congreso & Expo ASLAN 2023 en Madrid, MADE utiliza Inteligencia Artificial para monitorizar extensas cantidades de datos, adaptándose de manera automática a cada entorno de gestión. Esta innovación marca un cambio radical en la monitorización al eliminar la necesidad de configuración manual de reglas, permitiendo que la adaptación a la dinámica de los datos sea totalmente autónoma.
Este año no solo fue técnico, sino también personal. Desde el menor número de horas presenciales en la oficina en 17 años hasta pequeñas anécdotas personales, cada detalle cuenta.
¡Celebremos juntos el extraordinario esfuerzo y dedicación de todo el equipo en esta nueva etapa como Pandora FMS! ¡Felicidades por un año excepcional, lleno de éxitos en cada paso que hemos dado!
por Sancho Lerena | Last updated Feb 23, 2024 | Pandora FMS
SSH significa “Secure Shell” (o “Shell Seguro” en español). Es un protocolo de red utilizado para acceder y gestionar de forma segura dispositivos y servidores a través de una red no segura. Proporciona una forma certera de autenticación, así como una comunicación cifrada entre dos sistemas, lo que lo hace especialmente útil en entornos donde la seguridad es una preocupación.
SSH se utiliza comúnmente para acceder a servidores remotos a través de una interfaz de línea de comandos, pero también puede ser utilizado para transferir archivos de forma segura (a través de SFTP o SCP). Utiliza técnicas de cifrado para proteger la información transmitida, lo que hace que sea difícil para terceros interceptar o manipular los datos durante la transmisión.
Una de las principales ventajas de SSH es su capacidad para autenticar tanto al cliente como al servidor, lo que ayuda a prevenir ataques de tipo “man in the middle” y otras amenazas de seguridad. SSH reemplaza métodos más antiguos y menos seguros de acceso remoto, como Telnet, que transmite información de manera no cifrada, lo que hace que sea susceptible a la interceptación y el robo de datos.
SSH es un protocolo independiente del sistema operativo, aunque fue concebido para entornos Unix, está presente en sistemas operativos como OSX (Mac) y en las últimas versiones de servidores Microsoft Windows. SSH es, de facto, el estándar de conexión a servidores por línea de comandos.
Utiliza el puerto 22/TCP, pero se puede configurar para escuchar y conectarse por puertos diferentes. De hecho, se considera una buena práctica de seguridad cambiar el puerto por defecto de escucha para evitar ser identificado por herramientas de escaneo remoto.
Un breve repaso a la historia de SSH y OpenSSH
La trayectoria de OpenSSH se remonta al año 1999 y se encuentra estrechamente vinculada con el software original denominado “SSH” (Secure Shell), creado por Tatu Ylönen en 1995. SSH es un protocolo de red que permite la conexión segura y el control remoto de un sistema a través de una interfaz de línea de comandos.
En sus primeros días, SSH era software propietario y aunque estaba disponible de forma gratuita para uso no comercial, requería licencias para su uso en entornos comerciales. Esto llevó a la creación de varias implementaciones de SSH de código abierto para llenar la brecha en términos de accesibilidad y licencias de software.
En este contexto, el proyecto OpenSSH fue iniciado por Markus Friedl, Niels Provos, Theo de Raadt, y Dug Song en diciembre de 1999. La creación de OpenSSH se llevó a cabo en respuesta a una serie de eventos que incluyeron la liberación del código fuente del protocolo SSH por parte de Tatu Ylönen y la preocupación sobre la propiedad y las licencias del software propietario existente.
El objetivo inicial del proyecto OpenSSH era crear un protocolo gratuito y de código abierto que fuera compatible con las versiones existentes, especialmente con SSH-1 y SSH-2. OpenSSH también buscaba evitar las restricciones de licencia asociadas con las implementaciones propietarias de SSH.
A medida que el proyecto avanzaba, se convirtió en la implementación de facto de SSH en sistemas basados en Unix y Linux. La creciente popularidad de OpenSSH se debió a su código abierto, su capacidad para proporcionar una comunicación segura y sus características como el cifrado fuerte, la autenticación basada en clave y la capacidad de transferencia de archivos segura (SFTP).
OpenSSH también se benefició de la colaboración con la comunidad de software libre y de código abierto. A lo largo de los años, ha experimentado mejoras continuas, actualizaciones de seguridad y extensiones funcionales, lo que lo convierte en una herramienta esencial en la administración de sistemas remotos y la seguridad de la red.
En resumen, OpenSSH surgió como una respuesta a la necesidad de una implementación de SSH de código abierto y gratuita. A lo largo de los años, ha evolucionado para convertirse en la implementación de SSH más utilizada en sistemas Unix y Linux y sigue siendo fundamental en la seguridad de la comunicación y administración de sistemas en entornos distribuidos.
Ejecución de comandos remota con SSH
SSH no solo provee una forma de acceder de manera interactiva a la shell de una máquina remota, también se puede utilizar para ejecutar comandos remotos en un sistema, con la sintaxis siguiente:
ssh usuario@host:/ruta/del/comando
SSH se utiliza frecuentemente en scripts para la automatización de todo tipo de acciones y procesos, para ello necesita la autenticación automática por medio de certificados, ya que, por defecto, requerirá la introducción de una contraseña de manera manual e interactiva por el usuario a través del teclado.
La seguridad en SSH
SSH es acrónimo de Secure Shell, así que la seguridad es parte del diseño fundacional de SSH.
SSH tiene además la capacidad de crear túneles TCP que permiten utilizar un host para crear una especie de VPN dedicada entre dos IP que puede ser bidireccional. Es lo que se conoce como “Túnel TCP” y que mal usado, puede ser un problema de seguridad.
SSH permite la autenticación automática a través de certificados, lo que permite que un usuario se pueda conectar a un sistema mediante SSH sin conocer el password. Para ello hay que copiar la clave pública de un certificado digital en el servidor, de manera que identificamos a ese usuario a través de su certificado. Esta es una opción avanzada que permite la automatización de ejecución de comandos vía SSH, pero que presenta riesgos inherentes a cualquier automatización.
¿Qué diferencias hay entre Telnet y SSH?
SSH y Telnet son dos protocolos de red utilizados para acceder a sistemas remotos, pero hay diferencias significativas en términos de seguridad y funcionalidad.
SSH es el estándar actual para acceso remoto en todo tipo de entornos. Telnet, por otro lado, es más antiguo y menos seguro, y su uso se desaconseja a no ser que sea imposible usar SSH.
Seguridad
SSH: Proporciona un entorno seguro para la comunicación entre dos sistemas. Todos los datos, incluidos nombres de usuario y contraseñas, se cifran antes de ser transmitidos, lo que hace que sea mucho más difícil para un atacante interceptar y entender la información transmitida.
Telnet: Transmite datos, incluyendo credenciales de inicio de sesión, de forma no cifrada. Esto significa que si alguien tiene acceso a la red entre el cliente y el servidor, puede capturar y leer fácilmente la información.
Cifrado
SSH: Utiliza cifrado para proteger los datos durante la transmisión. Los algoritmos de cifrado en SSH pueden configurarse para cumplir con los estándares de seguridad más recientes.
Telnet: No proporciona cifrado, lo que significa que toda la información, incluidas las contraseñas, se transmiten de manera no segura.
Autenticación
SSH: Admite diversos métodos de autenticación, incluyendo la utilización de contraseñas, clave pública, y autenticación basada en tokens.
Telnet: Dependiendo de la configuración, generalmente utiliza solo nombres de usuario y contraseñas para la autenticación.
Puertos
SSH por defecto. SSH utiliza el puerto 22, a diferencia de Telnet que usa el puerto 23. No obstante, estos puertos se pueden cambiar en cualquier momento.
Mejores clientes de SSH
A continuación se enumeran algunos de los clientes de SSH más conocidos del mercado.
OpenSSH
OpenSSH (Linux, macOS, Windows con WSL) y otros sistemas operativos como BSD o dispositivos de comunicaciones que soportan una versión de OpenSSH.
OpenSSH es una implementación gratuita y de código abierto del protocolo SSH. Viene preinstalado en la mayoría de las distribuciones de Linux y es ampliamente utilizado en entornos Unix.
Es altamente confiable, seguro y es la elección predeterminada en muchos sistemas operativos basados en Unix, además de ser 100 % gratuito.
Putty
PuTTY es un cliente SSH gratuito y de código abierto para Windows y por ello, muy popular. Aunque inicialmente se diseñó para Windows, también existe una versión no oficial llamada “PuTTY for Mac” que funciona en macOS, también existen versiones alternativas para Linux.
Es liviano, fácil de usar y se puede ejecutar como una aplicación portátil sin necesidad de instalación. Sin embargo, adolece de una interfaz potente, no permite grabación de secuencias, y en general, carece de funcionalidades más avanzadas que podemos encontrar en otros clientes “visuales” de SSH. Tampoco dispone de una interfaz específica para transferencia de archivos.
De todas las opciones, PuTTY es la más básica, pero al menos es una interfaz visual, a diferencia del cliente estándar de SSH del sistema operativo que es gratis, pero donde todas las “funcionalidades” están basadas en líneas de comando.
Descargas y actualizaciones
Se puede descargar desde su web, aunque existen diversos sitios en paralelo que ofrecen versiones alternativas para Mac e incluso Linux.
Precio y licencias
Es gratuito y bajo licencia OpenSource por lo que puede modificar su código y compilarlo por su cuenta.
BitVise
Bitvise SSH Client es una opción sólida para usuarios de Windows que buscan un cliente SSH fácil de usar y seguro. Su combinación de una interfaz intuitiva, funciones avanzadas de transferencia de archivos y seguridad robusta lo convierte en una herramienta apreciada para la administración de sistemas remotos y la transferencia de archivos segura.
Servidor SSH
BitVise ofrece tanto un cliente SSH como un servidor SSH. Generalmente, los sistemas Windows no utilizan SSH por lo que puede ser una muy buena opción para implementarlo, pese a que las últimas versiones de Microsoft Windows Server lo implementan ya. Es una opción excelente para implementar SSH en versiones antiguas de Windows, ya que, soporta una amplia selección de versiones, prácticamente desde Windows XP:
- Windows Server 2022
- Windows 11
- Windows Server 2019
- Windows Server 2016
- Windows 10
- Windows Server 2012 R2
- Windows Server 2012
- Windows 8.1
- Windows Server 2008 R2
- Windows Server 2008
- Windows Vista SP1 or SP2
- Windows Server 2003 R2
- Windows Server 2003
- Windows XP SP3
Túneles SSH y reenvío de puertos
Permite la configuración de túneles SSH y reenvío de puertos, lo que es útil para redirigir tráfico de red de manera segura a través de conexiones SSH.
Gestión de sesiones avanzada
Bitvise SSH Client ofrece opciones avanzadas para la gestión de sesiones, incluyendo la capacidad de guardar configuraciones de sesión para un acceso rápido y fácil a servidores frecuentemente utilizados.
Registro de sesiones y auditoría
Proporciona un registro detallado de las sesiones, lo que puede ser útil para fines de auditoría y seguimiento de actividades.
Compatibilidad con proxy:
Bitvise SSH Client es compatible con varios tipos de proxy, lo que permite a los usuarios sortear restricciones de red y conectarse a través de servidores proxy.
Descargas y actualizaciones.
Se puede descargar una versión de evaluación de 30 días desde su web https://www.bitvise.com.
Licencias y precio
Solo para Windows, su precio ronda los 120 USD por año.
SecureCRT
Está disponible para todas las plataformas: Windows, macOS y Linux. Se puede descargar una demo funcional desde su página web en https://www.vandyke.com.
SecureCRT es un cliente comercial que ofrece soporte para múltiples protocolos, incluido SSH. Proporciona una interfaz gráfica avanzada, funciones de script y automatización, y es ampliamente utilizado en entornos empresariales.
Emulación de terminal
Ofrece emulación de terminal para una amplia variedad de tipos, incluyendo VT100, VT102, VT220, ANSI, entre otros. Esto asegura una compatibilidad efectiva con diversos sistemas y dispositivos remotos.
Transferencia de archivos segura
SecureCRT incluye soporte para protocolos de transferencia de archivos seguros, como SCP (Secure Copy Protocol) y SFTP (Secure File Transfer Protocol). Esto permite a los usuarios transferir archivos de manera segura entre sistemas locales y remotos. Para la gestión de transferencias de archivos utiliza un producto adicional llamado SecureFX (con coste de licencia adicional).
Automatización y secuencias de comandos
Facilita la automatización de tareas mediante la ejecución de secuencias de comandos. Admite varios lenguajes de secuencias de comandos, como VBScript, JScript y Python, proporcionando flexibilidad en la automatización de procesos.
Gestión de sesiones eficiente
SecureCRT ofrece una interfaz de gestión de sesiones eficiente que permite a los usuarios organizar y acceder fácilmente a conexiones previas. También posibilita la importación y exportación de sesiones para una fácil transferencia de configuraciones entre sistemas. Permite la configuración avanzada de sesiones, incluyendo opciones de autenticación, configuración de teclas de función, reenvío de puertos, entre otros. Esto ofrece a los usuarios un control preciso sobre sus sesiones remotas.
Integración de claves SSH
SecureCRT es compatible con la autenticación basada en clave, lo que significa que los usuarios pueden gestionar y utilizar claves SSH para una autenticación segura sin depender de contraseñas.
Soporte para protocolos adicionales:
Además de SSH, SecureCRT también es compatible con otros protocolos como Telnet, rlogin y Serial. Esto lo convierte en una herramienta versátil para diversos entornos de red.
Precio y licencias
Una versión completa para un usuario, incluyendo las funcionalidades de transferencia segura (SecureFX) viene a salir por unos 120$ al año.
ZOC
ZOC Terminal es un cliente SSH y emulador de terminal que ofrece características avanzadas para usuarios que necesitan una herramienta potente y versátil para trabajar con conexiones remotas SSH. También es compatible con otros protocolos como Telnet y Rlogin, lo que amplía su utilidad en diversos entornos no solo como cliente SSH sino como cliente Telnet.
ZOC es compatible con Windows y macOS y publica versiones actualizadas de manera regular. Puede descargarse una versión de demo desde su web en https://www.emtec.com.
Funciones de emulación de terminal
ZOC es compatible con múltiples emulaciones de terminal, como xterm, VT220, TN3270, y más. Esto permite a los usuarios conectarse a una variedad de sistemas remotos y mainframes.
Transferencia de archivos
Incluye funcionalidades de transferencia de archivos seguras (e inseguras), como FTP, SFTP (SSH File Transfer Protocol) y SCP (Secure Copy Protocol), permitiendo a los usuarios transferir archivos de manera segura entre el sistema local y remoto. La funcionalidad está incluida en el mismo producto.
Automatización y secuencias de comandos:
ZOC facilita la automatización de tareas mediante la ejecución de secuencias de comandos. Admite varios lenguajes de secuencias de comandos, como VBScript, JScript, y Python, lo que proporciona flexibilidad para la automatización de procesos. También permite grabar una combinación de teclas y reproducirla para, por ejemplo, automatizar sesiones de login que requieran el uso de sudo o su.
Gestión de sesiones
La capacidad de gestionar y organizar sesiones es crucial para aquellos que trabajan con múltiples conexiones. ZOC ofrece una interfaz de gestión de sesiones intuitiva que permite organizar y acceder fácilmente a conexiones previas. Se puede tener un catálogo de sistemas donde conectarse fácilmente.
Precio y licencias
La licencia básica ronda los 80 USD, pero su versión gratuita permite trabajar cómodamente, si exceptuamos el algo molesto popup del inicio.
Pandora RC: Alternativa al uso de SSH
Pandora RC (antes llamado eHorus) es un sistema de gestión de equipos para Microsoft Windows®, Linux® y Mac OS® que permite acceder a ordenadores registrados allí donde estén, desde un navegador, sin que tenga conectividad directa a sus dispositivos desde el exterior.
Seguridad
Para mayor seguridad, cada agente, al configurarlo, puede tener una contraseña individual que no se almacena en los servidores centrales de Pandora RC, sino que cada vez que el usuario quiera acceder a dicha máquina, tendrá que introducir de forma interactiva.
Acceso remoto sin conexión directa
Uno de los problemas más habituales de SSH es que necesitamos poder acceder a la IP del servidor. Con Pandora RC, es el servidor quien se conecta a un servicio en la nube y así está disponible desde cualquier lugar, sin necesidad de una VPN o reglas complejas en los firewalls.
Integración con Pandora FMS
Se integra nativamente con el software de monitorización Pandora FMS, de manera que es posible no solo monitorizar los servidores, sino acceder a ellos directamente desde la misma interfaz, sin necesidad de instalar clientes ssh, recordar contraseñas o generar duplicidades.
Precio y licencia
Gratuito hasta 5 dispositivos. Existen licencias de uso para ilimitadas máquinas a partir de 19€/mes. Más información en la web: https://pandorafms.com/en/remote-control/prices/
Shell remota y escritorio remoto todo en uno
Pandora RC dispone de un sistema de control remoto a través de acceso al Escritorio de manera visual. En ambos casos se utiliza una interfaz web para operar con el servidor remoto, sea Windows, MacOS o Linux. También provee un mecanismo de transferencia de archivos y gestión de procesos/servicios. Todo integrado en una aplicación WEB:
Ejemplo de Shell remota en un sistema Mac:
Ejemplo de un escritorio remoto en un sistema Mac:
Ejemplo de una compartición de archivos en un sistema Linux:
por Daniel Calbimonte | Last updated Feb 23, 2024 | Pandora FMS
El principio de menor privilegio, también conocido como POLP (Principle of Least Privilege), es una regla de seguridad informática que establece que cada usuario o grupo de usuarios debe tener solo los permisos necesarios para realizar sus tareas.
En otras palabras, cuanto menos poder tenga un usuario, menor será el riesgo de que cause daños a la empresa.
¿Por qué es importante?
El POLP es importante porque ayuda a proteger los sistemas y datos de la empresa de los ataques cibernéticos.
Cuando un usuario tiene demasiados permisos, tiene más posibilidades de cometer errores o ser víctima de un ataque. Por ejemplo, un usuario con acceso a los servidores podría instalar malware o robar información confidencial.
¿Cómo se aplica?
El POLP se puede aplicar a cualquier sistema informático, ya sea local o en la nube.
Menor privilegio en la práctica
¿Qué pasa si un usuario necesita hacer algo que normalmente no puede hacer?
El principio de menor privilegio establece que cada usuario debe tener solo los permisos necesarios para realizar sus tareas. Esto ayuda a proteger los sistemas y datos de la empresa de los ataques cibernéticos.
Sin embargo, hay casos en los que un usuario puede necesitar eludir las restricciones de seguridad para realizar alguna actividad no planificada. Por ejemplo, un usuario puede necesitar crear registros de un nuevo cliente.
En estos casos, el administrador del sistema puede otorgarle al usuario acceso temporal a un rol con mayores privilegios.
¿Cómo se hace esto de manera segura?
Lo ideal sería que el administrador del sistema crease un trabajo que automáticamente agregue al usuario al rol y que después de un tiempo definido lo elimine del rol.
Por ejemplo, el administrador podría darle al usuario privilegios durante dos horas y luego, automáticamente, quitarle los privilegios después de ese tiempo.
Esto ayuda a garantizar que el usuario solo tenga acceso a los permisos necesarios durante el tiempo que los necesite.
¿Qué pasa con los grupos de usuarios?
En general, es más seguro otorgar permisos a grupos de usuarios que a usuarios individuales.
Esto se debe a que es más difícil que un atacante comprometa a un grupo completo de usuarios que a un solo usuario.
Por ejemplo, si Juan es contador, en lugar de otorgarle privilegios de crear plantillas a Juan, el administrador podría otorgarle esos privilegios al grupo de contadores.
¿Y los procesos o servicios?
El principio de menor privilegio también se aplica a los procesos y servicios.
Si un proceso o servicio funciona con una cuenta, esa cuenta debe tener la menor cantidad de privilegios posible.
Esto ayuda a reducir el daño que un atacante podría causar si compromete la cuenta.
Importancia Continua en un Mundo Cambiante
Un gran número de empresas, tras la pandemia del COVID aumentó considerablemente la cantidad de empleados que trabajan desde casa. Antes solo nos teníamos que preocupar de los ordenadores dentro de la empresa. Ahora, la seguridad de cada ordenador portátil o teléfono móvil que acceda a nuestra red puede ser una brecha de seguridad.
Para evitar desastres, debemos crear estándares de seguridad y capacitar al personal para evitar que entren a sitios prohibidos con los ordenadores de la empresa o las computadoras que acceden a nuestra empresa. Es por eso que se debe evitar dar privilegios de administrador y aplicar el PoLP en los usuarios en la medida que sea posible. Por eso se aplica la confianza 0, dando la menor cantidad de privilegios en lo posible. Si el usuario no se autentifica, no se le dan privilegios.
El personal de TI debe verificar la seguridad de las computadoras portátiles que lleva el usuario y ver la forma de evitar que lleguen ataques a los servidores empresariales o de la nube provenientes de nuestro personal que trabaja de manera remota.
Complejidades en la Implementación
Sin embargo, aplicar el mínimo privilegio de seguridad es hoy en día bastante complejo. Los usuarios con una cuenta acceden a infinidad de aplicaciones diferentes.
Posiblemente también tengan que acceder a aplicaciones web que residen en servidores Linux por lo cual hay que crear roles y privilegios en diversas aplicaciones. Es muy común que varias funcionalidades básicas no funcionen con los mínimos privilegios de ciberseguridad por lo que existe la tentación de conceder privilegios extra.
Dar privilegios mínimos a una sola aplicación ya es complicado. Otorgar PoLP a varios sistemas que interactúan entre sí, llega a ser mucho más complejo aún. Es necesario realizar controles de calidad de seguridad. Los ingenieros de TI deben hacer pruebas de seguridad y parchear los huecos de seguridad.
Cuentas Privilegiadas: Definición y Tipos
Las cuentas privilegiadas o super cuentas son esas cuentas que tienen acceso a todo.
Estas cuentas tienen privilegios de administrador. Las cuentas son usadas generalmente por gerentes o por las personas de mayor rango jerárquico del equipo de TI.
Se debe tener mucho cuidado con dichas cuentas. Si un hacker o un Malware logra acceder a estas contraseñas, es posible destruir todo el sistema operativo o toda la base de datos.
La cantidad de usuarios con acceso a estas cuentas debe ser mínima. Normalmente solo el gerente de IT tendrá cuentas de super usuario con todos los privilegios y la alta gerencia tendrá amplios privilegios, pero en ningún caso privilegios totales.
En los sistemas operativos Linux y Mac por ejemplo el superusuario se denomina root. En el sistema Windows se le llama Administrador.
Por ejemplo, nuestra cuenta de Windows por defecto no corre con todos los privilegios. Si deseamos ejecutar un archivo con cuentas de administrador, debemos presionar el botón derecho sobre el archivo ejecutable y seleccionar la opción Ejecutar como Administrador.
Este privilegio de ejecutar como administrador solo se usa en casos especiales de instalación y no se debe usar en todo momento.
Para evitar que un hacker o una persona malintencionada acceda a estos usuarios se recomienda cumplir estas medidas de seguridad:
- Utiliza una contraseña compleja larga que mezcle mayúsculas, minúsculas, números y caracteres especiales.
- También trata de cambiar la contraseña de estos usuarios con regularidad. Por ejemplo, cambiar la contraseña cada mes o cada dos meses.
- No está de más utilizar un buen anti-virus para detectar y prevenir algún ataque y también poner un cortafuegos (firewall en inglés) para evitar ataques de desconocidos.
- Evita siempre abrir correos y archivos adjuntos de desconocidos o entrar a páginas web de dudosa confiabilidad. Estos ataques pueden vulnerar las cuentas. En lo posible, nunca navegar con supercuentas de usuario ni usar estas cuentas a menos de que sea necesario.
Cuentas Privilegiadas en la Nube
Hoy en día, gran cantidad de información se maneja en la nube. Cubriremos el manejo de cuentas en las principales plataformas como ser AWS, Azure de Microsoft y Google Cloud.
En AWS se utiliza el tipo de autenticación IAM (Identity and Access Management) que permite crear y administrar usuarios. También soporta la autenticación multifactor (MFA) que exige 2 formas para validar al usuario y así ingresar aumentando así la seguridad.
En AWS existe un usuario root que es un super usuario con todos los privilegios. Con este usuario debemos crear otros usuarios y protegerlo usándolo lo menos posible.
Google Cloud también proporciona un sistema IAM y también el KMS (Servicio de manejo de claves) que permite administrar y manejar las claves.
Dependiendo de la aplicación en la nube existen super usuarios administradores de las bases de datos, sistemas análisis, sitios web, IA y otros recursos.
Si por ejemplo, yo soy un usuario que solo necesito ver reportes de tablas de una base de datos, no necesito tener acceso a actualizar o insertar datos nuevos. Todos estos privilegios deben ser cuidadosamente planificados por el departamento de TI de seguridad.
Vectores Comunes de Amenazas Privilegiadas
Si no se aplica el PoLP, si un hacker entra al sistema podría acceder a información muy sensible a la empresa al poder conseguir la contraseña de un usuario. En muchos casos estos hackers roban la información y piden dinero de rescate.
En otras situaciones, usuarios dentro de la empresa malintencionados podrían vender información valiosa de la empresa. Si aplicamos el PoLP, estos riesgos se pueden reducir considerablemente.
Desafíos para Aplicar el Menor Privilegio
No es nada fácil aplicar el PoLP en las empresas. Especialmente si les hemos dado privilegios de administrador inicialmente y ahora que hemos aprendido los riesgos queremos quitarle los privilegios. Debemos hacerle entender al usuario que es por el bien de la empresa para proteger nuestra información y que un gran poder conlleva una gran responsabilidad. Que si sucede algún ataque a la empresa, los mismos empleados quedan mal junto con la empresa. Explicarle que la seguridad depende de todos.
Muchas veces damos privilegios excesivos por pereza de dar solo el mínimo privilegio de ciberseguridad. Es apremiante investigar, optimizar y reducir los privilegios para aumentar la seguridad.
Otro problema común es que al tener privilegios restringidos, se reduce la productividad del usuario que termina siendo dependiente de su superior por falta de privilegios. Esto puede causar frustración en los usuarios e ineficiencia en la empresa. Debemos ver cómo lograr un equilibrio en cuanto a eficiencia sin afectar la seguridad.
Beneficios para la Seguridad y la Productividad
Al aplicar el principio de otorgar acceso restringido, reducimos la superficie de ataque. También se reducen las posibilidades de recibir un ataque de Malware y se pierde menos tiempo tratando de recuperar los datos después de un ataque.
Por ejemplo Equifax, una empresa de crédito fue víctima de un Ransomware en 2017. Este ataque afectó a 143 millones de clientes. Equifax tuvo que pagar 700 millones de dólares en multas y reparaciones. También tuvo que pagar indemnizaciones a los usuarios.
Los principales beneficios para la empresa son:
- Reduce el riesgo de ataques cibernéticos.
- Protege los datos confidenciales.
- Reduce el impacto de los ataques.
Principio de Menor Privilegio y Buenas Prácticas
Para poder cumplir con los estándares es recomendable hacer una auditoría y verificar los privilegios de los usuarios y seguridad en general. Se puede hacer una verificación interna o una auditoría externa.
Puedes realizar pruebas de seguridad para ver si tu empresa cumple esos estándares. A continuación muestro alguno de los estándares más conocidos:
- CIS es un Centro para la seguridad de la información. Contiene recomendaciones y buenas prácticas para proteger sistemas y datos a nivel mundial.
- NIST Cybersecurity Framework proporciona un marco de seguridad del Instituto Nacional de Estándares y Tecnología.
- SOC 2 proporciona un informe de evaluación de los controles de seguridad de una empresa u organización.
Menor Privilegio y Confianza Cero
Separar los privilegios es dar a los usuarios o cuentas solamente los privilegios que necesitan para reducir el riesgo. Las políticas de seguridad Just-In-Time (JIT) reducen los riesgos al eliminar excesivos privilegios, automatizar los procesos de seguridad y administrar a los usuarios privilegiados.
JIT significa dar privilegios solamente cuando se los necesita. Es decir, que sean temporales. Por ejemplo si un usuario necesita acceder a una base de datos solamente por 2 horas, podemos crear un script que le asigne privilegios durante este tiempo y luego se le remuevan dichos privilegios.
Para implementar el JIT se debe:
- Crear un plan con las políticas de seguridad.
- Implementar el plan aplicando el PoLP y el JIT con controles que pueden incluir el acceso multifactor y un control de acceso con roles.
- Es importante capacitar a los empleados sobre seguridad y explicar estos conceptos para que entiendan no solo cómo aplicarlos sino el porqué aplicarlos.
- Y finalmente es importante aplicar auditorías. De este tema ya se habló en el punto 10.
Conviene también hacer un monitoreo de permisos para ver quienes tienen privilegios de más y también vemos a qué recursos se acceden para ver si se necesitan realizar ajustes en los mismos.
Soluciones para la Implementación del Menor Privilegio
Como mencionamos anteriormente, para incrementar la seguridad, hay que segmentar la red para reducir daños si nuestra seguridad se vulnera. Segmentar la red es dividir la red en pequeñas subredes.
También se debe monitorear los privilegios otorgados a los usuarios.
Finalmente se debe integrar las políticas de seguridad con las tecnologías para crear un plan administrativo de acuerdo al software que se tenga.
Cómo Implementar el Menor Privilegio de Manera Efectiva
Para implementar el principio de otorgar accesos, se debe implementar el sistema propuesto en servidores de prueba. Se debe pedir al personal que por un tiempo haga pruebas de trabajos reales en el sistema.
Una vez que se corrijan los errores o se solucionen las quejas de los usuarios, corresponde llevar el sistema a producción con los mínimos privilegios. Se recomienda un período de pruebas de por lo menos un mes donde los usuarios prueben el sistema y tengan a la mano el sistema antiguo.
En la mayoría de las ocasiones conviven el sistema antiguo y el nuevo por meses hasta que se aprueba el sistema con nuevo con la seguridad de menor privilegio implementada.
Conclusión
El principio de menor privilegio: una medida simple pero efectiva para la seguridad informática.
En un mundo cada vez más digital, la seguridad informática es fundamental para las empresas de todos los tamaños. Los ataques cibernéticos son cada vez más frecuentes y sofisticados, y pueden causar daños importantes a las empresas.
Una de las medidas más importantes que pueden tomar las empresas para proteger sus sistemas y datos de los ataques cibernéticos es aplicar el principio de menor privilegio. Este principio establece que cada usuario o grupo de usuarios debe tener solo los permisos necesarios para realizar sus tareas.
Aplicar el principio de menor privilegio es una medida simple pero efectiva. Al otorgar a los usuarios solo los permisos necesarios, las empresas reducen el riesgo de que un atacante comprometa los sistemas y datos sensibles.
Consejos para aplicar el principio de menor privilegio:
- Identifica los permisos necesarios para cada tarea.
- Otorga permisos a grupos de usuarios en lugar de a usuarios individuales.
- Reduce los privilegios de las cuentas de procesos y servicios.
- Revisa los permisos de los usuarios de forma regular.

por Laura del Río Gómez | Last updated Feb 23, 2024 | ITSM
El soporte de Tecnología de la Información (IT), también conocido como soporte técnico, es esencial para el funcionamiento exitoso y eficiente de las organizaciones en la era digital. Ayuda a garantizar la estabilidad, productividad y seguridad de los sistemas y las personas que dependen de ellos.
Su importancia radica en varios aspectos clave como el mantenimiento de la infraestructura tecnológica (esto incluye servidores, redes, sistemas operativos, software, hardware y otros componentes esenciales); asistencia para resolver problemas y garantizar la continuidad del negocio, implementar y mantener medidas de seguridad (como firewalls, antivirus y sistemas de detección de intrusiones); actualización periódica y mantenimiento del software, implementación y gestión de sistemas de almacenamiento de datos, copias de seguridad y recuperación de datos en caso de fallos; optimización de recursos (como la gestión de la capacidad de los servidores), mantenerse al día con las últimas tendencias tecnológicas y evaluar cómo estas pueden beneficiar a la organización y proporcionar datos y análisis que ayuden a la toma de decisiones.
Los 5 niveles de soporte IT: descripción, funciones y habilidades
Nivel 0 de soporte IT: Autoservicio
- Portal de autoservicio.
- Base de conocimientos.
- Autoservicio guiado.
- Comunidad online.
- Herramientas de diagnóstico.
- Formación y capacitación.
- Automatización.
Nivel 1 de soporte IT: Primer contacto de persona a persona (soporte básico)
El nivel 1 de soporte IT, también conocido como “primer contacto de persona a persona” o “soporte básico”, se enfoca en resolver los problemas técnicos más simples y comunes que no requieren un conocimiento técnico avanzado. A continuación, se describen las características y responsabilidades típicas del tier support 1:
- Helpdesk.
- Registro y seguimiento de incidentes.
- Resolución de problemas comunes.
- Documentación y actualización de la base de conocimientos.
- Coordinación con otros equipos.
Nivel 2 de soporte IT: Soporte técnico
El nivel 2 de soporte IT, también conocido como “soporte técnico” o “soporte avanzado”, se encarga de problemas más complejos y técnicos que van más allá de la capacidad del nivel 1. Algunas de las principales características y responsabilidades del tier support 2 son:
- Análisis de causas raíz.
- Desarrollo y mantenimiento de documentación técnica.
- Interacción con proveedores y fabricantes.
- Capacitación y mentoría al personal de nivel 1.
- Monitoreo y mantenimiento proactivo.
- Participación en proyectos de TI.
Nivel 3 de soporte IT: Soporte experto
El nivel 3 de soporte IT, también conocido como “soporte experto” o “soporte de nivel superior”, se encarga de abordar los problemas más complejos y desafiantes que requieren un profundo conocimiento técnico y experiencia. Las características y responsabilidades más destacadas del tier support 3 son:
- Investigación y desarrollo.
- Diseño e implementación de soluciones avanzadas.
- Participación en proyectos estratégicos.
- Desarrollo de políticas y procedimientos.
- Gestión de crisis.
Nivel 4 de soporte IT: Soporte de terceros
El nivel 4 de soporte IT, también conocido como “soporte de terceros” o “soporte externo”, se reserva para problemas extremadamente complejos o situaciones en las que se requiere experiencia especializada que va más allá de lo que puede ofrecer una organización internamente. A continuación, se describen las características y responsabilidades típicas del tier support 4:
- Soporte de proveedores de tecnología.
- Desarrollo de soluciones personalizadas.
- Integración de tecnología.
- Participación en auditorías y revisiones de seguridad.
- Coordinación y gestión de contratos de servicio.
- Gestión de relaciones con proveedores.
- Análisis de tendencias y recomendaciones estratégicas.
Cómo establecer una estructura de ayuda por niveles
La implementación de una estructura de ayuda por niveles implica una planificación y ejecución cuidadosa para garantizar una asistencia técnica eficiente. Entre los principales pasos para establecer una estructura de ayuda por niveles está la elección de la plataforma de Gestión de Servicios de TI (ITSM) adecuada, que sea escalable y personalizable.
Una vez elegida la herramienta ITSM, se deberá configurar en ella una plataforma de autoservicio o un portal web dedicado y definir claramente los niveles de soporte IT de la organización. Además, la plataforma ITSM debe incluir automatización de procesos, como el enrutamiento de tickets, la priorización de incidentes o la generación de informes; proporcionar documentación actualizada a cada nivel de soporte; herramientas para medir el rendimiento de la estructura TI y de gestión de la demanda para planificar las cargas de trabajo.
Por último, para crear una estructura eficaz es esencial establecer canales de comunicación efectivos y realizar evaluaciones periódicas para ajustar la estructura y los procesos a las necesidades cambiantes de la organización.
Conclusión
La implementación de una estructura de ayuda por niveles en un entorno de IT trae consigo múltiples beneficios para la organización.
Beneficios de la implementación de niveles de soporte IT
Los niveles de soporte permiten una distribución eficiente de las solicitudes de soporte, asegurando que los problemas se dirijan al nivel adecuado para su resolución. Esta eficiencia operativa redunda en una mejora de la satisfacción del usuario y en un ahorro de costes al garantizar que los recursos técnicos se utilicen de manera más competente.
Por otra parte, la rápida gestión de los incidentes críticos que proporciona la estructura de ayuda por niveles, escalando los problemas según su naturaleza a los diferentes niveles de soporte, permite garantizar la continuidad del negocio. Por último, el compartimiento de la documentación y el conocimiento permite el desarrollo de capacidades entre el personal de la empresa.
Adaptación de la estructura a las necesidades de la organización
Es importante destacar que no existe una estructura de ayuda por IT levels única y universalmente aplicable. Cada organización tiene necesidades y requisitos específicos, por lo que es esencial adaptar la estructura a sus circunstancias particulares teniendo en cuenta el tamaño y complejidad de la organización, la naturaleza de las operaciones que realiza según la industria a la que pertenezca, las necesidades de los usuarios, tanto internos como externos, de la compañía; los recursos económicos y humanos con los que cuenta la organización y los cambios tecnológicos que se producen y que requieren una infraestructura flexible y capaz de adaptarse a las evoluciones tecnológicas y de negocio.
Preguntas Frecuentes
Resumen de preguntas comunes sobre soporte IT y carreras en este campo
¿Para qué sirve el soporte IT?
El soporte IT supone una herramienta muy útil, tanto para empresas como para individuos, para recibir asistencia en cualquiera de las tareas a desarrollar en sus respectivos ámbitos TI. Les garantiza que podrán cumplir con sus objetivos o continuar ofreciendo servicios a sus clientes aún si sufrieran fallos de hardware y software o en sus redes.
¿Qué niveles de soporte IT existen?
- Nivel 0: Autoservicio
- Nivel 1: Soporte básico
- Nivel 2: Soporte técnico
- Nivel 3: Soporte experto
- nivel 4: Soporte de terceros
¿Cómo empezar mi carrera en soporte IT?
Por supuesto para conseguir un empleo en este ámbito se requieren conocimientos técnicos de sistemas y procesos. Para empezar podrías completar cursos relacionados o hacerte con alguna de las certificaciones necesarias.
¿Qué es el soporte IT remoto?
El soporte IT remoto permite que los técnicos de asistencia puedan prestar sus servicios a los clientes de forma más rápida y eficaz a través del control remoto, email o chat. Aún a distancia son capaces de diagnosticar cualquier problema y facilitar los pasos a seguir para solucionarlo.
¿Qué habilidades son necesarias para trabajar en soporte IT?
Por supuesto, el trato con el cliente siempre exigirá habilidades de comunicación profesionales y efectivas. Además, la capacidad de resolver problemas eficazmente y mantenerse al día con todas las novedades IT es fundamental para cualquier profesional IT.

por Ahinóam Rodríguez | Last updated Feb 23, 2024 | Control Remoto
Seguro que alguna vez has recibido un correo electrónico avisando de una factura pendiente de pago, un envío de paquetería que no esperabas o una advertencia del banco sobre actividad sospechosa en tu cuenta. Estos mensajes suelen adoptar un tono alarmante y nos proporcionan un enlace hacia una web que debemos visitar para confirmar nuestros datos personales o completar información de pago. ¡Cuidado! Se trata de un intento de “phishing”, uno de los métodos de estafa más populares en Internet.
¿Qué es el Phishing?
El phishing es una forma de ciberataque que utiliza la tecnología y la ingeniería social para vulnerar la seguridad de los usuarios.
El término viene de la palabra inglesa “fishing” (pescar) ya que los ciberdelincuentes emplean tácticas de anzuelo esperando que el usuario “pique” o caiga en la trampa. Por lo general, pretenden hacerse con información financiera, contraseñas de servicios de pago (como PayPal) o credenciales de inicio de sesión.
En realidad, el phishing no es ninguna novedad. Los primeros casos de este tipo de fraude se remontan a mediados de los 90’, cuando un grupo de estafadores se hacía pasar por empleados de la compañía AOL para robar datos confidenciales de los clientes. Ya en la década del 2000 los ataques comenzaron a especializarse, focalizándose principalmente en el sector bancario.
Con el paso de los años, las estafas se han vuelto más sofisticadas y, a pesar de los avances en cibersegurida, fenómenos como el auge del teletrabajo o el uso fraudulento de la IA han contribuido a la aparición de nuevas formas de hacer phishing.
El phishing como fuente de preocupación
Cualquier persona puede ser víctima del phishing. A pesar de que los sistemas de ciberseguridad son cada día más potentes, los estafadores también han perfeccionado sus habilidades y se organizan en equipos pequeños, especializándose en tácticas de ingeniería social.
A menudo las empresas se convierten en el objetivo preferido de estos ciberdelincuentes que intentan robar sus datos confidenciales o engañar a los cargos intermedios para que realicen transferencias no autorizadas. Un ejemplo de phishing bastante frecuente es el fraude mediante facturas de proveedores en el que los estafadores suplantan la identidad de socios comerciales de confianza para solicitar el pago de una factura pendiente.
Aún más inquietantes son casos como el que vimos a comienzos de 2020 en la revista Forbes en el que una empresa japonesa fue víctima de una elaborada estafa en la que se usó la IA generativa para clonar la voz de un directivo y autorizar una transferencia de 35 millones de dólares.
La clonación de audio, los deepfakes audiovisuales y, en general, el uso de la última tecnología con fines delictivos supone una gran amenaza y, a la vez, un desafío para las empresas de ciberseguridad.
Riesgos asociados a los ataques de phishing
Las pérdidas financieras tienen un impacto inmediato, pero existen otras consecuencias a largo plazo que pueden experimentar las empresas víctimas del phishing:
- Daño reputacional: las filtraciones de datos pueden erosionar la confianza de los clientes, causando un daño permanente en la reputación de la empresa.
- Interrupción del servicio: un ciberataque puede paralizar los sistemas informáticos de la empresa, especialmente si involucra ransomware. Todo comienza al descargar un archivo malicioso incluido en los mensajes de phishing. Una vez en el sistema, encripta archivos críticos y bloquea el acceso a información vital para la empresa.
- Multas y sanciones: la violación de las normativas de protección de datos (como la GDPR) puede dar lugar a sanciones por parte de las autoridades.
Es importante estar preparados para enfrentarse a estas amenazas utilizando soluciones de ciberseguridad robustas y programas internos de concienciación del empleado como principales armas para prevenir los ataques de phishing.
Estadísticas y datos relevantes
El fraude de correo electrónico representa ya el 27% de las pérdidas económicas por violaciones de la ciberseguridad y es el causante del 90% de las filtraciones de datos, según el informe Cybersecurity Threat Trends 2021 (CISCO). Esto ocurre principalmente porque las campañas de phishing se han vuelto masivas y los estafadores utilizan cientos de correos para llegar a más personas.
Elementos clave en un ataque de phishing
Por suerte, los mensajes de phishing suelen ser bastante chapuceros y los destinatarios se dan cuenta enseguida de que están ante una estafa, pero algunas veces están tan personalizados que arrojan dudas de si son legítimos o no.
Para ganarse la confianza de sus víctimas, los estafadores suplantan la identidad de instituciones, bancos o empresas que ofrecen sus servicios a través de Internet.
La mayoría de estos correos fraudulentos constan de:
- Un remitente desconocido, con extensiones genéricas de correo electrónico (Gmail, Hotmail, etc.) o nombres que se parecen a los de las compañías oficiales, pero con palabras extrañas que no logramos identificar.
- Un saludo genérico (“Estimado cliente”, “Querido amigo”) ya que por lo general los ciberdelincuentes desconocen la identidad del destinatario.
- Una solicitud urgente de nuestra información personal (DNI, número de tarjeta de crédito) con el pretexto de resolver un problema.
- Un enlace externo que dirige hacia una web fraudulenta con el mismo logotipo, diseño y colores de la marca a la que pretenden suplantar. En esta página de destino se nos solicitará que actualicemos nuestros datos para continuar. En este momento se produce el robo de la información.
- También existe la posibilidad de que el correo lleve un archivo adjunto infectado con software malicioso (malware, ransomware). Si lo descargamos, comprometerá la seguridad del sistema.
Es importante ser precavidos y aprender a reconocer estas señales de phishing para minimizar riesgos.
Tipos de phishing
Actualmente existen más de 10.000 formas de phishing (según informa Wikipedia). Estas son algunas de las modalidades más conocidas.
Phishing tradicional
Es la forma más común de fraude por correo electrónico. Se basa en la emisión aleatoria de correos suplantando la identidad de una empresa o institución de confianza. Los mensajes incluyen enlaces hacia webs fraudulentas o archivos infectados.
Spear phishing
Mientras que el phishing tradicional es una estafa aleatoria, el spear phishing se dirige a una persona en concreto, normalmente un cargo influyente dentro de la empresa. Para ganarse su confianza, los ciberdelincuentes realizan una investigación exhaustiva en Internet, recopilando datos personales de redes sociales como LinkedIn donde consultan información como la edad, la ubicación o cargo dentro de la empresa.
Whaling
En la caza de ballenas el objetivo son personas importantes dentro de la empresa o cargos ejecutivos (CEO, CFO, etc.). Los estafadores investigan a sus presas durante semanas y envían correos muy personalizados, relacionados con problemas comerciales críticos.
Smishing
Los mensajes fraudulentos se envían a través de mensajes de texto (SMS) o WhatsApp. Por ejemplo, recibimos un aviso de nuestro banco informando de una compra no autorizada con nuestra tarjeta con un enlace para cambiar el PIN y los datos de acceso. Si lo hacemos, habremos caído en la trampa.
Vishing
Viene de la unión de “voice” y “phishing”. En este caso, la estafa se realiza mediante llamada telefónica. Un ejemplo típico es el fraude de servicio técnico en el que los estafadores llaman para informar de un fallo en los equipos que en realidad no existe y nos convencen para instalar un troyano que robará nuestros datos.
Angler Phishing
Es una táctica nueva que consiste en crear perfiles falsos en redes sociales con el nombre de instituciones y empresas de prestigio. El objetivo es robar datos confidenciales de otros usuarios.
¿Cómo detectar un ataque de Phishing?
Reconocer un mensaje de phishing no siempre es fácil, pero hay algunos indicativos que pueden hacernos sospechar que la solicitud es inusual.
- Tono alarmista: suelen transmitir urgencia e instar al usuario a que actúe de inmediato. Los ciberdelincuentes utilizan emociones como el miedo o la curiosidad y hacen uso de tácticas de intimidación para que actuemos de manera irracional.
- Errores gramaticales: muchos mensajes de phishing contienen errores ortográficos y gramaticales, ya que fueron escritos por hablantes no nativos. De todas formas, a día de hoy muchos estafadores utilizan herramientas como Chat GPT para corregir sus textos, por lo que debemos desconfiar incluso de los mensajes sin faltas de ortografía.
- Enlaces sospechosos o archivos adjuntos no solicitados: ¿El remitente pide que hagas clic en un enlace? ¿Incluye supuestas facturas o multas impagadas que no logras identificar? Lo más probable es que se trate de un ciberataque.
¿Cómo evitar un ataque de Phishing?
- No abras mensajes de remitentes desconocidos.
- No facilites tu información personal a través de un enlace incluido en un correo electrónico.
- No descargues archivos adjuntos que te parezcan sospechosos.
- Pasa con el cursor por encima del enlace y comprueba si la url comienza por https. Esto indica que el sitio cuenta con un certificado seguro.
Si a pesar de estas precauciones has caído en la trampa y proporcionado tus datos, cambia cuanto antes las contraseñas de las cuentas afectadas y notifica la estafa a la Policía local. También puedes ponerte en contacto con la Oficina de Seguridad del Internauta de INCIBE (Instituto Nacional de Seguridad) para que investiguen el fraude.
Protegiendo a tu organización del phishing
IBM asegura en su informe Cost of a Data Breach Report 2021 que una empresa puede tardar de media 213 días en advertir que ha sido víctima de un ataque de phishing. Durante este tiempo los ciberdelincuentes accederán a todo tipo de información confidencial: contraseñas de bases de datos, secretos comerciales, credenciales de acceso a la red empresarial… Por eso es importante estar preparados y trabajar proactivamente para detener la amenaza del phishing.
Algunas medidas preventivas:
Concienciación del empleado
Haz que la ciberseguridad forme parte de la cultura organizacional de tu empresa y crea campañas para prevenir a tus empleados de los riesgos de las estafas en Internet. Una buena medida es implementar un software de simulación de phishing para entrenarlos y enseñarles a diferenciar un correo auténtico de uno fraudulento.
Implementación de soluciones de seguridad en el correo electrónico
La primera línea de defensa contra un ataque de phishing es el filtro anti-spam integrado en el correo electrónico. Asegúrate de que esté actualizado a las últimas versiones y parches de seguridad. También puedes configurar políticas de autenticación de correo electrónico como DMARC (Domain-based Message Authentication, Reporting, and Conformance) para reducir el riesgo de suplantación de identidad.
Monitoreo y protección de endpoints
Los endpoints son los dispositivos finales (ordenadores, tablets, smartphones) conectados a la red. Las soluciones EDR han sido diseñadas para monitorear y detectar la presencia de malware en estos endpoints.
A diferencia de los antivirus que trabajan con patrones previamente identificados, las soluciones EDR son más avanzadas ya que dan respuestas automatizadas y en tiempo real para contener el ataque. Utilizan tecnologías como la IA y el aprendizaje automático capaces de detectar comportamientos anómalos, como la ejecución de scripts maliciosos.
La protección de los endpoints es una medida básica de ciberseguridad, pero debe combinarse con otras soluciones como el monitoreo del tráfico de red o soluciones de acceso remoto seguro como Pandora RC.
¿Cómo ayuda Pandora RC a mejorar la seguridad en el acceso remoto?
Cada vez más empresas están adoptando políticas de teletrabajo o trabajo híbrido. Es una realidad que plantea nuevos retos en cuanto a ciberseguridad. Los trabajadores en remoto desempeñan su actividad en entornos menos seguros que los que están bajo la supervisión de los equipos TI.
Herramientas como Pandora RC ayudan a monitorear sus sistemas ofreciendo soporte remoto y una asistencia rápida si se sospecha de un ataque de phishing.
Otras formas en las que Pandora RC puede contribuir a la prevención de ciberataques:
- Genera contraseñas 100% locales evitando las vulnerabilidades de los sistemas centralizados.
- Las conexiones remotas deben ser previamente aprobadas.
- Utiliza políticas de acceso de doble autenticación. Esto reduce el riesgo de acceso no autorizado ya que los usuarios tienen que validar su identidad en dos pasos.
- Es una solución flexible y escalable. Además, está disponible como solución SaaS o On-Premise para empresas que desean tener un mayor control sobre sus infraestructuras.
Otros consejos para evitar ataques de phishing en el entorno empresarial
A medida que las técnicas de phishing se vuelven más sofisticadas, la necesidad de protegerse va en aumento. Por eso, no es mala idea tener presentes algunos consejos de manual:
- Trata de mantenerte al día sobre las nuevas estafas, sigue las noticias que se publican en los medios de comunicación y lee blogs de tecnología como el blog de Pandora FMS.
- Usa contraseñas seguras en tus cuentas que incluyan una combinación de números, letras y caracteres especiales. Nunca elijas datos personales como fecha de nacimiento, ciudades o nombres de mascotas para tus contraseñas; los phishers podrían adivinar esta información revisando tus redes sociales.
- Utiliza un sistema de autenticación multi-factor (MFA) para añadir una capa adicional de seguridad a tus conexiones. De esta forma, si un hacker obtiene tus credenciales de inicio de sesión todavía necesitaría conocer el código enviado a tu móvil para acceder a tus cuentas.
- La instalación de un cortafuegos es fundamental para bloquear el acceso no autorizado a la información confidencial. Asegúrate de que está bien configurado y solamente permite las transacciones seguras.
- Mantén actualizado el navegador y el sistema operativo ya que los ciberdelincuentes suelen aprovecharse de las vulnerabilidades de los sistemas desactualizados.
- Evita acceder a información confidencial a través de redes Wi-Fi públicas. Muchas de estas redes carecen de protocolos de encriptación y los datos transmitidos podrían ser interceptados. Desactiva en tu móvil la opción de conectarse automáticamente a redes Wi-Fi abiertas.
- Realiza copias de seguridad automáticas de los datos de la empresa para poder recuperar la información en caso de ataque. Te recomendamos que sean backups inmutables (no se pueden eliminar ni modificar). Esto garantiza que las copias están protegidas y podrán ser restauradas incluso si se produce un ataque de ransomware.
Conclusión
Como comentamos al principio, el phishing existe desde los inicios de Internet y, probablemente, evolucionará y conozcamos nuevas modalidades de esta forma de ciberataque. Aunque debemos estar vigilantes frente a estas amenazas, frenar el desarrollo tecnológico no es la solución. La clave está en adoptar medidas de ciberseguridad y educar a los usuarios para minimizar los riesgos y crear un entorno laboral seguro.
por Daniel Calbimonte | Last updated Feb 23, 2024 | Comunidad, Nube y Virtualizacion
El Cloud Computing en inglés o computación en la nube es un servicio ofrecido por varios proveedores de software pagando un alquiler ya sea por hora, mes o uso de dicho servicio. Pueden ser máquinas virtuales, bases de datos, servicios web u otras tecnologías cloud. Estos servicios están en servidores remotos provistos por empresas tales como Google, Microsoft y Amazon entre otros que por un alquiler o en algunos casos gratuitamente, proporcionan dichos servicios. Resulta muy conveniente tener estos servicios ya que desde un teléfono móvil o una máquina no muy sofisticada, se puede tener a acceso a importantes servicios de todo tipo con solo tener acceso a internet.
Servicios proporcionados en la nube
Los servicios más comunes proporcionados en la nube son los siguientes:
- Almacenamiento de información en la nube. Donde el servicio permite almacenar varios archivos, imágenes u otros datos en la nube. Es una especie de super disco duro conectado mediante internet.
- Bases de datos en la nube. Se puede tener acceso a servidores o a bases de datos tales como SQL Server, PostgreSQL, MySQL, Oracle, etc. Nótese que ya no es necesario acceder a todo el servidor con el sistema operativo (cosa que también se puede). Se puede acceder también a bases de datos NoSQL que son bases de datos que no usan una base de datos relacional. En vez de utilizar tablas, utiliza documentos o claves-valor para guardar la información.
- Data Lake. El servicio de Data Lake es como el nombre indica, un lago de datos. Se pueden tener datos estructurados, no estructurados como también semiestructurados. Estos servicios se utilizan para manejar lo que es el Big Data. Es decir, mucha información. Hoy en día, los datos ya no se pueden manejar en bases de datos tradicionales exclusivamente sin son muy grandes las cantidades de información. Es por eso que se recurre a otros medios de almacenamiento como los Data Lakes.
- Análisis de datos. También se proporcionan herramientas para analizar los datos. Se tienen herramientas para reportes, analítica usando Machine Learning y otras tecnologías.
- Software en la nube. Existe la posibilidad de programar en diversos lenguajes utilizando los servicios en la nube. Hay plataformas para subir el código y sitios web.
- Servicios de integración de datos. Servicios como AWS Glue, Google Cloud Data Fusion y Azure Data Factory entre otros son servicios que nos permiten integrar datos. Es decir, copiar datos de una base de datos a otra o a un archivo de texto, mover datos de un Data Lake a una base de datos, etc.
- Servicios de red. Los servicios de red o networking ayudan a conectar aplicaciones locales con aplicaciones en la nube. Estos servicios brindan conectividad, seguridad y escalabilidad. Entre algunos servicios se ofrecen puertas de enlace o Gateways entre la red local y la nube. También existe el servicio de Virtual Network Gateway. Esta conecta la red virtual y la nube. Otro servicio común es el Load Balancer que distribuye el tráfico entre servidores. También existen otros servicios más de Networking como poder ser los enlaces de aplicaciones, manejadores de tráfico, etc.
- Otros servicios. Existe una infinidad de servicios en la nube como Machine Learning, IA, IoT…
Funcionamiento de computación en la nube
El ahorro es importante. En vez de gastar dinero en un buen servidor o una buena infraestructura, directamente se pueden alquilar estos servicios de computación en la nube. Si bien los costos de alquiler de servicios en la nube de los principales proveedores como Azure, AWS y Google pueden parecer altos para empresas pequeñas y medianas, existe un ahorro en personal.
Se requiere un menor equipo de profesionales de sistemas para mantener las aplicaciones en la nube. No se debe perder tiempo en el Hardware ni en muchos aspectos de seguridad. Si bien, los proveedores de servicios en la nube no son responsables de la seguridad en un 100 %, gran parte de la responsabilidad recae en ellos. Ellos se encargan de las replicaciones, de cambiar el hardware. Mediante un simple pago podemos hacer que nuestro servidor de base de datos soporte mayor cantidad de gente conectada simultáneamente. Eso, en un entorno local implicaría la compra de nuevos servidores carísimos y migrar la información de un lado a otro.
Cambios de discos duros viejos, renovar servidores, problemas de hardware, todo eso se resuelve con la nube, donde ya no nos tenemos que preocupar de ese aspecto. Básicamente, es pagar el servicio y usarlo.
Servicios disponibles
Algunos servicios básicos son Microsoft 365 que ofrece MS Word en la nube, Excel, Word, PowerPoint, Outlook, OneNote, Publisher y Teams entre otras aplicaciones en la nube. Por ejemplo, los documentos en Excel, ya no se guardan en el disco duro sino en la nube. Es decir, en servidores de Microsoft Azure a los que nos conectamos desde nuestra máquina usando internet.
Por su lado Google ofrece Google Workspace que es similar a Microsoft 365. Por ejemplo, provee Google Sheets (una especie de Excel online), Google Docs (similar a MS Word), Gmail (similar a Outlook para correos), Google Slides (similar a MS PowerPoint).
Estas son algunas de las muchas aplicaciones en la nube. Sin embargo, la nube va mucho más allá.Puede ofrecer Servidores Windows, Linux. Bases de datos de toda índole ya sean las relacionales o las NoSQL, servicios de análisis, IoT, Devops, páginas web, plataforma de programación de aplicaciones, servicio de analítica de datos, Machine Learning, APIs, software en la nube y mucho más.
Ejemplos de Computación en la Nube
En la vida cotidiana usamos servicios en la nube desde hace tiempo. Por ejemplo, Hotmail fue el primer servicio que usaba tecnología cloud. El concepto de la nube no se utilizaba entonces, pero los correos se almacenaban en servidores remotos. Luego vinieron los servicios de correo de Yahoo, Gmail.
Con el tiempo llegó Microsoft 365 donde ya fue posible la utilización de Word, Excel, PowerPoint, etc. usando una tecnología cloud. Ya con AWS, Azure, Google Cloud y otros proveedores, tenemos un sinfín de servicios en la nube ya mencionados anteriormente.
Origen del término “Computación en la nube”
Mucha gente se pregunta, ¿Qué es la nube? El término de computación en la nube es en realidad una metáfora. Desde los 60s se utilizaba una nube para representar las redes. A partir del 2000, se populariza la palabra y en cierta forma indica que la red está en el cielo. Es decir, que no está a tu alcance físico sino en otro lugar al que podemos acceder mediante internet.
Historia de la computación en la nube
Ya desde los años 60 para representar las redes se usaba a una nube para representarlas cuando se conectaban a ordenadores. Sin embargo, no fue hasta los 90s cuando se comenzó a utilizar el término para describir el software como servicio (lo que en inglés sería el SaaS). Mediante el servicio, las máquinas se conectaban a internet sin tener que administrarlo desde sus ordenadores.
Sin embargo, el término se hizo popular a partir del año 2000 con el auge de las máquinas virtuales y la computación en la red. Computación en la nube engloba los múltiples servicios ofrecidos en la red.
Importancia de la Nube
Las grandes empresas están apostando en grande por la nube. Microsoft por ejemplo actualizó las certificaciones de su tecnología a la nube. Las tecnologías ubicadas en la empresa física ya fueron removidas del listado de certificaciones de Microsoft. Amazon por otro lado empezó en la nube y fue pionera. La tendencia es gastar menos en un equipo de TI y gastar más en el alquiler de servicios en la nube. Cada año, el uso de servicios en la nube crecerá más. Según Gartner, en el año 2025, el 51% del gasto de los servicios de TI. Serán invertidos en la nube.
Proveedores Principales de Nube
La siguiente tabla muestra a los principales proveedores de servicios en la nube y su % de mercado:
Como se puede observar en la tabla AWS sigue siendo el líder y Microsoft mantiene un segundo lugar. Google ocupa un tercer puesto.
Elementos Clave de la Computación en la Nube
Existen diversos tipos de servicios que son IaaS, PaaS y SaaS. A continuación, describimos cada uno:
- IaaS (Infraestructura como servicio) brinda acceso a servicios en la nube, como servidores, almacenamiento y redes. En este tipo de servicio el usuario es responsable de instalar, configurar y administrar el software y las aplicaciones que se utilizan.
- PaaS (Plataforma como servicio) brinda una plataforma completa para poder desarrollar, ejecutar y administrar aplicaciones. En Paas, el usuario es responsable de desarrollar la aplicación, sin embargo, el proveedor de la nube se encarga de la infraestructura y los servicios subyacentes.
- SaaS (Software como servicio) proporciona acceso a aplicaciones completas a través de Internet. El usuario no tiene que instalar ni administrar el software, ya que todo esto lo maneja el proveedor de la nube.
Computación en la Nube Multi-nube
Las empresas grandes por lo general optan por adquirir diferentes servicios de diferentes proveedores de servicios en la nube. Es muy habitual que una empresa cuente con servicios tanto en Microsoft, Google como en AWS. Esto se debe a diferentes factores como el precio, las habilidades técnicas del servicio de TI, algunas ofertas especiales de los proveedores, etc. Por fortuna, los principales proveedores no son muy diferentes entre sí en sus servicios.
Beneficios de la Computación en la nube
El principal beneficio es que los usuarios no van a perder tiempo en mantenimiento de hardware, comprar hardware, escalar y migrar servidores. Los equipos empresariales y de TI, se van a enfocar en los negocios y aplicaciones. No van a perder mucho tiempo en instalaciones y configuraciones de equipos.
Ventajas y desventajas de la Computación en la Nube
Como ventajas ya hablamos sobradamente de una reducción de trabajo en la instalación de software, seguridad, tiempo en instalación y compra de hardware. Sin embargo, no hablamos casi nada de las desventajas.
En muchos casos, son servicios muy costosos. Y es que hay servicios tan caros que se pagan por hora, que, si se olvida apagarlos, se incrementa el costo considerablemente.
Suponga por ejemplo que tiene un servicio en la nube que cuesta 100 dólares la hora. Por día se paga 800 dólares por 8 horas de uso. Sin embargo, imagínese que el empleado que lo utiliza, olvidó apagar la máquina en la nube, eso puede hacer que el servicio le cobre 2400 dólares al día en vez de 800. Otro problema es que hay que capacitar al personal porque si un hacker entra en la nube, puede acceder a toda la información empresarial, con lo que nuestra empresa y sus equipos resultarían totalmente vulnerables.
Adopción Generalizada de la Computación en la nube
Existe una clara tendencia al alza del uso de servicios en la nube. En el año 2020, según Gartner, un 20 % de la carga de trabajo lo manejaba la nube. En el año 2023, está cifra se duplicó. A pesar de que la competencia de proveedores en la nube aumentó, la demanda de los servicios en la nube y los beneficios de las empresas que ofrecen estos servicios van en constante aumento.
Desafíos y Futuro de la Computación en la Nube
Hay varios desafíos del cloud computing. IoT, o el internet de las cosas, maneja sensores. Uno puede detectar por ejemplo el estado de las máquinas, mantener inventario, revisar producción, rastrear productos. Cada vez va en mayor aumento el uso de APIs en la nube, servicios de inteligencia artificial. La nube proporciona bastantes servicios y estos van en constante aumento.
Conclusión
La computación en la nube ofrece un sinfín de servicios como:análisis de datos, servicios de inteligencia artificial, páginas web, servidor de aplicaciones, plataformas de desarrollo, DevOps y un sinfín de etcéteras. La tendencia es migrar gran parte de la infraestructura local a la nube.
por Pandora FMS team | Last updated Feb 23, 2024 | Comunidad, Integraciones
Para entornos en los que necesitemos estar al tanto de inmediato si existe algún problema, como entornos de producción, seguridad o recursos críticos de nuestra compañía, esta integración de Pandora FMS con Telegram es perfecta, ya que responde a esa inmediatez requerida, así como la posibilidad de ofrecer información precisa sobre la localización y causa del problema, gracias al potente sistema de alertas y macros de Pandora.
Del mismo modo, al ser un servicio de mensajería basado en las comunicaciones telefónicas a través de la red de datos, permite que nuestros técnicos, responsables y operadores de guardia, cuenten con la garantía de saber en el momento exacto en el que aparece un problema, sin necesidad de acceder a un ordenador o consultar manualmente el correo electrónico.
Gracias a los plugins de nuestra librería y al flexible sistema de alertas que ofrece Pandora FMS, vamos a enseñaros cómo configurar nuestra herramienta de monitorización para enviar mensajes instantáneos en el momento en que un problema es detectado.
En primer lugar, debemos partir del entorno necesario, cuyos requisitos son:
- Entorno de Pandora FMS corriendo sobre Linux, en este caso usaremos Rocky Linux 8, la distribución recomendada por el fabricante.
- El plugin de nuestra librería: Telegram bot CLI.
- Cuenta de Telegram disponible para ser utilizada como emisora de los mensajes de alerta.
Creación del bot
Lo primero de todo será crear el bot de Telegram que se encargará de mandarnos los mensajes. Desde la cuenta de Telegram que queramos utilizar, interactuaremos con el usuario BotFather mediante el comando “/start”:
Utilizaremos el comando “/newbot” para crear nuestro bot.
Nos pedirá el nombre que queremos que tenga nuestro bot. Especificamos el nombre que queremos que tenga nuestro bot. Es importante que el nombre termine con “bot”, por ejemplo Pandora_FMS_telegram_bot.
Al enviarle el nombre, si no está en uso, nos confirmará que se ha creado el bot, con un enlace a su chat y nos dará un Token que es importante que guardemos para configurar la alerta más adelante.
Configuración del grupo
Ahora meteremos el bot que acabamos de generar en un grupo que tengamos o uno nuevo que creemos, para recibir nuestras alertas.
El siguiente paso es agregar otro bot llamado GetIDs Bot al mismo grupo con el fin de obtener el identificador de grupo. Al añadirlo, nos dejará en un mensaje el ID de nuestro grupo, lo apuntaremos también para más adelante.
Con todo esto ya tendremos preparado nuestro Telegram para recibir las alertas.
Integración con Pandora FMS (versión 773 y anteriores)
Comenzaremos descargando nuestro plugin Telegram bot CLI.
Nos descargará un archivo ZIP llamado telegram-bot-cli.zip, que debemos descomprimir. Dentro encontraremos un archivo llamado “pandora-telegram-cli.py” el cual meteremos en nuestro servidor de Pandora FMS en la ruta “/usr/share/pandora_server/util/plugin”.
Ahora, desde la terminal de nuestro servidor, instalaremos las dependencias de Python3 (si no las tenemos ya) con el comando “dnf install python3”:
Una vez instalado, ejecutaremos el plugin para comprobar que se ejecuta, con el comando “python /usr/share/pandora_server/util/plugin/pandora-telegram-cli.py”:
Ahora pasaremos a la consola de nuestro servidor de Pandora FMS.
Accederemos a la sección “Management > Alerts > Commands” y le daremos al botón “Create”:
Y configuraremos nuestro comando de alerta de la siguiente manera:
En comando escribir:
python3
/usr/share/pandora_server/util/plugin/pandora-telegram-cli.py -t _field1_ -c _field2_ -m “_field3_”
El comando que utilizaremos es el de ejecución del plugin que hemos descargado, con los argumentos -t, -c y -m. Es importante que el argumento -m vaya entrecomillado “”.
- En el campo del argumento -t, Bot Token, meteremos el token de nuestro bot.
- En el campo del argumento -c, Chat ID, meteremos el ID de nuestro grupo que nos brindó el bot “GetIDs Bot”.
- Y en el campo -m, Alert Message, introduciremos el mensaje de alertado que queremos que nos mande nuestro bot al grupo. Podemos utilizar todas las macro de alerta que necesitemos, algunos ejemplos son:
- _module_: nombre del módulo que disparó la alerta.
- _agentalias_: alias del agente que disparó la alerta.
- _modulestatus_: estado del módulo cuando se disparó la alerta.
- _agentstatus_: estado del agente cuando se disparó la alerta.
- _data_: dato del módulo que disparó la alerta.
- _timestamp_: Hora y fecha en que se disparó la alerta.
Por ejemplo podríamos usar este mensaje (que pondremos en el campo 3): “The module _module_ of agent _agentalias_ has changed to _modulestatus_ status”
.
Una vez relleno todo esto, le daremos al botón “Create”.
Ahora accederemos a la sección “Management > Alerts > Actions” de nuestra consola de Pandora FMS y le daremos al botón de “Create” para crear nuestra acción.
Pondremos el nombre que queramos que tenga nuestra acción, seleccionamos el grupo, el comando de alerta que hemos creado anteriormente y elegiremos un Threshold. Se rellenarán todos los campos automáticamente y hacemos clic a “Create”:
Ahora accederemos al apartado “Management > Alerts > List of Alerts” y configuraremos la alerta para el Agente y Módulo que queramos.
En nuestro caso hemos seleccionado que cuando el Módulo “Host Alive” del agente “Router” pase ha estado crítico, ejecute nuestra acción creada previamente “Telegram Message”:
Si nuestro módulo pasara ha estado crítico, recibiremos este mensaje a nuestro grupo de Telegram:
Cuando nuestra alerta se recupere recibiremos un mensaje como este:
Integración con Pandora FMS (versión 774 y posteriores)
En la versión v7.0NG.774 se ha introducido por defecto en el alertado de Pandora FMS el plugin de Telegram de nuestra librería, con una configuración básica de serie.
Si accedemos al apartado de Management > Alerts > Comands, dispondremos de un comando llamado “Pandora Telegram”:
Al acceder a él, veremos que viene configurado ya el comando que ejecutará nuestra alerta. Rellenaremos el parámetro -t “TOKEN” del comando con el token que nos ha dado el BotFather y guardaremos el comando:
Tras esto, accederemos al apartado Management > Alerts > Actions y accederemos a la acción Pandora Telegram.
En La parte inferior, añadiremos el Chat ID de nuestro grupo que nos dio el bot “GetIDs Bot” en los apartados Triggering y Recovery, podemos modificar el mensaje a nuestro gusto utilizando las macro de alerta como hemos visto anteriormente y haremos clic en “Update”:
Una vez guardado, entraremos al menú de Lista de alertas desde Management > Alerts > List of Alerts y crearemos una nueva alerta.
Seleccionaremos el agente y módulo, la acción que hemos actualizado “Pandora Telegram”, la plantilla que queramos y creamos la alerta:
Una vez se dispare nuestra alerta, recibiremos nuestro mensaje por Telegram:
Envío de alertas con gráficas de datos
En nuestra integración del alertado de Pandora FMS y Telegram, podemos añadir al mensaje una gráfica con los últimos datos del módulo que disparó la alerta, esto se aplica tanto para la versión 773 y anteriores y para 774 y posteriores. Conseguiremos mandar gráficas en nuestras alertas añadiendo una llamada a la API de nuestro servidor de Pandora FMS al script que hemos utilizado anteriormente.
El primer paso que deberemos configurar en nuestro servidor, es el acceso a la API de Pandora FMS en el apartado “Setup > Setup > General Setup”, en el campo “API password” tendremos la contraseña de la API y en “IP list with API access” pondremos las IP que necesiten tener acceso o podremos brindar acceso a cualquier IP (*).
Ahora editaremos el comando que habíamos creado previamente para añadir los datos necesarios para mandar la gráfica. Necesitamos añadir los siguientes parámetros:
- –api_conf: aquí indicaremos los parámetros de configuración de la API de nuestro servidor, es importante rellenar los campos “ < >”:
“user=,pass=,api_pass=,api_url=http:///pandora_console/include/api.php”.
Ejemplo: “user=admin,pass=pandora,api_pass=1234,api_url=http://10.0.5.100/pandora_console/include/api.php”
- –module_graph: parámetros del módulo del que extraeremos la gráfica, en este caso tenemos dos:
- module_id: donde se introduce el ID del módulo que disparó la alerta. En este caso utilizaremos la macro de alerta _id_module_ para que se rellene siempre con el ID del módulo de la alerta.
- interval: intervalo de tiempo total mostrado en la gráfica, en segundos. Nosotros utilizaremos por defecto 3600 segundos, el equivalente a 60 minutos o 1 hora pero se puede configurar en el intervalo que convenga.
El comando completo resultante será el siguiente:
Comando:
Y la configuración de los campos:
Y guardamos los cambios.
Al dispararse la alerta recibiremos el mensaje con la gráfica de datos de nuestro módulo:
por Ahinóam Rodríguez | Last updated Feb 23, 2024 | ITSM
Todos somos conscientes de la importancia de atraer nuevos clientes para el crecimiento empresarial, pero enfocarse únicamente en este objetivo no es la mejor decisión. Entregar un servicio de atención al cliente de calidad también es clave para alcanzar el éxito. Por esta razón, muchas compañías que venden sus productos o servicios a través de Internet han decidido implementar un servicio de soporte posventa como parte fundamental de su negocio.
¿Cómo diferenciarse de la competencia con un buen servicio de soporte posventa?
Ya hace más de un siglo el empresario y filósofo japonés Konosuke Matsushita, conocido por ser el fundador de Panasonic y uno de los impulsores del “milagro económico japonés”, sentó las bases de una filosofía comercial revolucionaria para su época. Matsushita se basó en conceptos como la contribución social, el trabajo en equipo, el foco en el cliente y la innovación tecnológica como factores diferenciadores. Escribió varias obras a lo largo de su vida, proyectando su particular visión sobre los negocios y la sociedad. En lo que respecta al soporte posventa opinaba que: “El servicio posventa es más importante que la asistencia antes de la venta, porque es a través de este servicio como se consiguen clientes permanentes”.
Estos clientes habituales pueden convertirse en nuestros mejores embajadores de marca, así que conviene mimarlos para que se sientan satisfechos y compartan sus experiencias positivas o realicen nuevas compras y contrataciones.
¿Cómo ofrecer un servicio posventa centrado en el cliente?
Una de las mayores dificultades que encuentran las empresas a la hora de gestionar el servicio de atención al cliente es ¿Cómo transmitir cercanía y proximidad en un servicio tan automatizado como el soporte TI y que se ofrece de manera remota?
Antiguamente, cuando no había Internet, los clientes tenían que llamar a una central de atención telefónica para que resolvieran sus dudas o reportar cualquier problema. Hoy en día, los centros de soporte TI utilizan herramientas como los chatbots que ahorran mucho tiempo a los equipos humanos. El uso de estos asistentes virtuales creció de manera espectacular durante la pandemia, permitiendo a las empresas responder a picos de actividad muy elevados y seguir ofreciendo un servicio 24/7.
Sin embargo, con la vuelta a la normalidad, los usuarios reclaman un servicio de atención al cliente más conversacional y menos transaccional. La mayoría valora positivamente las herramientas de autogestión (chatbots) como una forma de obtener respuestas rápidas a sus preguntas, pero no desean que las interacciones con las máquinas reemplacen por completo a las personas. Por ejemplo, el informe “Next in Personality 2021” de McKinsey revela que el 71 % de los consumidores espera que las empresas ofrezcan interacciones personalizadas y el 76 % se frustra cuando esto no sucede.
Encontrar el equilibrio perfecto entre automatización y soporte humano es vital para ofrecer un servicio de soporte posventa rápido, eficiente y basado en las necesidades del cliente. No se puede nadar contra corriente o intentar poner freno a la digitalización, al contrario, debemos apoyarnos en las ventajas de la tecnología integrándola dentro del soporte TI de la empresa para acceder a la información de manera unitaria y saber qué solicitudes se pueden automatizar y cuáles necesitan atención personalizada.
¿Cómo integrar el centro de soporte TI para ofrecer a los clientes un buen servicio posventa?
La integración del centro de soporte TI debe planificarse con cuidado para garantizar un flujo de trabajo ordenado y eficiente en la empresa.
Algunos pasos esenciales para una buena integración son los siguientes.
Implementar un sistema de gestión de servicios (ITSM)
Para gestionar cualquier tipo de incidencia o reclamación es imprescindible contar con un marco estructurado en el que se definan las políticas que debe seguir el departamento de soporte.
Los profesionales de esta área se encargan de coordinar los servicios TI con los objetivos empresariales. Además, capacitan al equipo y definen cuáles son las tareas que es posible automatizar.
Crear una infraestructura de soporte TI
Las empresas que reciben un volumen importante de solicitudes pueden atravesar situaciones críticas si no disponen de herramientas que les permitan crear flujos de trabajo dinámicos.
En este sentido, el correo electrónico es una herramienta de gestión penosa ya que no permite hacer cosas tan básicas como priorizar las solicitudes importantes, realizar un seguimiento de las mismas o escalarlas a un nivel superior cuando el equipo de soporte de primera línea no es capaz de resolverlas.
Si tratas de ofrecer un servicio de soporte posventa a través este medio, pronto verás que la bandeja de entrada del correo se satura hasta convertirse en un cajón de sastre ¡Ningún empleado sabrá por dónde empezar!
¿Conoces ya Ticketing Helpdesk de Pandora ITSM? Esta herramienta es todo lo que necesitas para facilitar el trabajo al equipo de soporte y fidelizar a tus clientes.
Como su nombre indica, Ticketing Helpdesk funciona mediante un sistema de tickets. Cada vez que un cliente realiza una solicitud a través de la plataforma, se abre un nuevo ticket con sus datos, fecha y asunto de la incidencia.
Los tickets son catalogados automáticamente según su estado: nuevos, en espera, resueltos, etc. También se pueden priorizar aquellos que requieren una acción inmediata, definir reglas de automatización o transferir los casos complejos que no han podido ser resueltos a niveles superiores de soporte.
Ticketing Helpdesk es una herramienta flexible y preparada para trabajar en un entorno omnicanal. Se puede integrar fácilmente con otras herramientas de la infraestructura TI como gestores de proyectos o CRM, para evitar la redundancia de procesos y aprovechar toda la información disponible para mejorar el funcionamiento de otros departamentos y del mismo servicio posventa.
Utilizar la información recopilada para optimizar el servicio de atención al cliente
Como ya adelantamos, Ticketing Helpdesk recopila datos de las consultas, los analiza y genera informes personalizados con información relevante como:
- Número de tickets resueltos
- Número de tickets que continúan sin resolverse.
- Tiempo medio de resolución de los tickets.
- Incidencias más comunes
- Desempeño de cada agente (feedback del cliente)
- Tickets que se han escalado a niveles superiores
Hacer un seguimiento de estas métricas es muy útil para conocer el rendimiento del servicio a largo plazo y detectar posibles anomalías que pasarían desapercibidas al analizar los datos de manera aislada.
También sirve para garantizar el cumplimiento de los acuerdos contractuales relacionados con el servicio (SLA) como pueden ser el tiempo de inactividad y la capacidad de respuesta de soporte (por ejemplo, resolución de las incidencias en 24 h). Respetar estos acuerdos es importante para generar confianza en el cliente. Además, su incumplimiento involucra compensaciones económicas que deberán asumir las empresas. Con la herramienta Helpdesk podemos gestionar esta información clave y crear alertas automáticas si el servicio permanece inactivo durante mucho tiempo.
Por último, además de la generación automática de informes, Ticketing Helpdesk de Pandora ITMS también recopila información de encuestas de satisfacción que los usuarios pueden responder desde el correo electrónico o a través de un formulario web. Es una forma fiable de saber si el servicio funciona conforme a lo esperado y los agentes encargados del área de soporte resuelven eficazmente los problemas de los clientes.
¿Todavía tienes dudas de si Pandora ITMS cumplirá con tus expectativas?
Pruébalo gratis durante 30 días. No necesitas tarjeta de crédito, solamente conocimientos avanzados en el área TI y algo de tiempo libre para familiarizarte con todas sus funcionalidades.

por Pandora FMS team | Last updated Feb 23, 2024 | ITSM
Los avezados líderes de los departamentos de TI comprenden que el crecimiento constante y sostenible conlleva una serie de desafíos significativos.
Desarrollar el crecimiento de TI requiere una estrategia cohesionada que se alinee a la perfección con el motor de dicha operación:
Y ese es el Service Desk, el protagonista indiscutible de esta travesía.
¿Forma la estrategia de soporte los cimientos del crecimiento empresarial?
Una estrategia sólida de soporte no solo garantiza el éxito de la empresa, sino que se convierte en una pieza esencial para su supervivencia en un entorno competitivo.
La evolución tecnológica ha otorgado una nueva dimensión al significado de crecimiento en el ámbito de TI.
En la constante búsqueda de estrategias innovadoras para impulsar su desarrollo, los líderes de TI reconocen la indiscutible importancia de la tecnología en el avance de una empresa.
En este contexto, el soporte y el servicio al cliente surgen como elementos cruciales para permitir que una empresa pueda:
- Mantener la continuidad de sus operaciones.
- Optimizar la productividad de su base de usuarios y clientes.
- Cumplir con sus compromisos.
- Fomentar la lealtad de sus clientes.
Optimización empresarial a través del soporte remoto: Ahorro y eficiencia
El tiempo, un recurso a veces inapreciable, reafirma su posición como el bien más valioso en la gestión empresarial.
En el arte de administrar el tiempo de manera eficiente, reside el potencial de ahorrar considerables sumas de dinero, dado que los procesos se agilizan y ejecutan en menos horas.
En este contexto, el empleo de herramientas de soporte remoto marca una diferencia tangible.
Si nos ponemos a comparar el Soporte Tradicional y el Soporte Remoto revelamos pronto el impacto de nuestra elección en términos de costes.
En base a un análisis realizado por el Help Desk Institute, se evidencia la disparidad financiera entre resolver un incidente en el sitio físico y abordarlo de manera remota.
Si bien estos datos provienen del lejano Estados Unidos, su utilidad como referencia para estimaciones de ahorro es incuestionable:
¡La implementación de soporte remoto puede reducir los costes por ticket en un asombroso 69%!
¡Malditos y sabios yankees!
Optimiza tu Service Desk: Reducción de costos a través del Tiempo Medio Operativo (TMO)
Tu Departamento de Tecnología de la Información (TI) suele albergar una serie de indicadores que trazan el pulso de la estrategia de soporte implementada.
Entre estos indicadores, resalta el Tiempo Medio Operativo (TMO), conocido como el Average Handle Time (AHT) en inglés.
Esta métrica revela la duración promedio en que un analista de soporte atiende un ticket del Service Desk.
Existe una correlación entre el coste por ticket y el tiempo de gestión asociado.
La rapidez en la resolución de un ticket se traduce en una disminución del costo relacionado.
Cada minuto empleado por un agente tiene un valor económico, de manera que la resolución en 20 minutos es distinta a resolverlo en 40 minutos.
Asimismo, la diferencia entre que un problema sea solucionado en el primer nivel o necesite ser escalado hacia un especialista de nivel superior tiene un impacto en los gastos, dado que los salarios varían notablemente.
Así, las métricas de Resolución en Primera Llamada y Resolución en Primer Nivel se erigen como determinantes en la duración de la gestión del ticket y, en consecuencia, en los costes asociados.
El enfoque en resolver un mayor número de tickets en el primer contacto con el cliente, y en abordar los incidentes desde los niveles iniciales de soporte, culmina en una reducción del costo por ticket, una estrategia que conlleva ahorros considerables.
Herramientas de soporte remoto: El catalizador de eficiencia y ahorro
La capacidad del Soporte Remoto Corporativo es un instrumento esencial para los departamentos de asistencia, permitiéndoles conectarse de manera segura y remota a dispositivos y equipos de los clientes.
La premisa es clara.
Apunta:
Agilizar la gestión de incidentes y salvaguardar la continuidad de los servicios de TI y las operaciones empresariales
Dentro de este contexto, una de las palancas de mayor valor que ofrece una herramienta de soporte remoto corporativo reside en su capacidad para reducir los costes de asistencia, mejorando la métrica del Tiempo Medio Operativo por ticket.
¿Lo que buscas es potenciar la eficacia en la atención al cliente?
Aquí llega el arte de resolver en el Primer Contacto
Bien, ha llegado el momento de poner el foco en la métrica de Resolución en Primera Llamada.
Este indicador refleja el porcentaje de casos que se resuelven en el primer contacto entre el cliente y el Service Desk.
Necesitas una solución precisa y estructurada con la que puedas realizar un diagnóstico veloz del incidente, dejando atrás los métodos obsoletos y adoptando un enfoque para acelerar el soporte de manera práctica y eficiente.
Si fuera necesario elevar el caso a un técnico de nivel avanzado, debes contar con una función que asegure que la resolución continúe en la primera interacción con el cliente.
Este enfoque evita interrupciones en la llamada o chat con el cliente, así como la pausa del ticket y la inclusión de todas las notas del primer contacto, entre otras tareas engorrosas.
Con esta solución, se agiliza el proceso al invitar al técnico pertinente, permitiendo abordar el problema en ese mismo instante.
Imagina el tiempo significativo que se economiza al invitar sin complicaciones al técnico adecuado, resultando en la resolución exitosa en la primera interacción.
Estrategia ‘Shift-Left’: Clave para reducir costos y liberar recursos en TI
Una de las tendencias más notables en el ámbito del Service Desk es la implementación constante de una estrategia “shift-left”.
En la era actual, la generación y el mantenimiento de una ventaja competitiva son inseparables de esta mejora continua.
Volvamos un segundo al punto de antes y pongámonos deductivos:
El costo por hora de los técnicos especializados supera con creces al de los analistas de nivel 1.
Si observamos el costo promedio de resolución de tickets según el nivel de soporte de los yankees, resulta evidente la disparidad entre la resolución en el primer nivel (22 USD) y en el tercer nivel (104 USD).
Esta diferencia llega a ser casi cinco veces mayor.
Por lo tanto, al enfocarnos en fortalecer la estrategia “shift-left” y procurar la resolución de una mayor cantidad de tickets desde los niveles iniciales de soporte, conseguiremos dos metas cruciales:
- Reducir los costos por ticket: Esta acción contribuye directamente a optimizar los gastos operativos.
- Liberar recursos de alto valor: Al disminuir la carga en los técnicos de nivel avanzado, se les otorga más tiempo para involucrarse en actividades de alto impacto en el seno del departamento de TI.
Así que la herramienta de soporte remoto emerge de las aguas como un aliado invaluable para elevar la estrategia “shift-left” a nuevas alturas.
Conclusiones
En el torbellino tecnológico en el que vivimos, los grandes líderes TI han descubierto que el crecimiento constante exige afrontar desafíos formidables.
Es ahí cuando el Service Desk brilla como un pivote esencial.
Hemos explorado cómo las estrategias de soporte dan forma al panorama de expansión corporativa y cómo la asistencia remota se convierte en un pilar eficaz para la evolución del Service Desk.
Los ahorros y la eficiencia enraizados en estas prácticas no son solo metas, sino realidades tangibles.
¿Hemos sacado alguna moraleja?
Por supuesto, esto es un gran artículo:
En el ballet cósmico, el tiempo es el protagonista indiscutible.
La inversión inteligente en herramientas de soporte remoto no solo recorta gastos, sino que añade segundos a la danza, liberando potencialidades inexploradas.
Así, el camino hacia la optimización se pavimenta con ahorros y sonrisas.
¡El reloj sigue su marcha, y nosotros, con ingenio, aceleramos hacia el mañana!
¡BUM!
¿Quieres saber cómo Pandora FMS puede ayudarte con esto?
por Pandora FMS team | Last updated Feb 23, 2024 | Control Remoto
¿Qué es el acceso remoto y cómo ha transformado la dinámica laboral en todo el mundo? Sumerjámonos, exploremos, descubramos juntos cómo esta innovadora práctica ha remodelado las estructuras laborales convencionales y ha abierto un abanico de posibilidades.
¿Qué es el acceso remoto?
El acceso remoto o la conexión remota, en esencia, es un portal virtual que vincula tus tareas laborales con la ubicación física que elijas. En lugar de estar anclado a un aburrido escritorio en una oficina, esta tecnología permite que los trabajadores accedan a sistemas informáticos, archivos y recursos desde cualquier lugar con conexión a Internet.
*Ya puedes imaginarte con el bañador puesto y tecleando desde las Maldivas.
En el corazón de esta revolución está la habilidad de interactuar con plataformas y datos a través de interfaces virtuales, lo que borra las fronteras entre la cuadriculada oficina tradicional y un entorno más flexible (y con posibilidad de tardeo en el chiringuito)
¿Para qué sirve el acceso remoto?
La función del acceso remoto trasciende los límites de la mera conveniencia. Ha demostrado ser una herramienta crucial para las empresas y trabajadores en diversas circunstancias. Durante momentos excepcionales, como aquella pandemia global que al parecer todo el mundo ha olvidado, cambió la forma de trabajar tal y como lo conocíamos. Esta tecnología se convirtió en un salvavidas para la continuidad empresarial. Un ejemplo notable se encuentra en España, una, grande y libre, donde la adopción del teletrabajo se elevó de manera sorprendente, con un 80% de las empresas implementando el acceso remoto para mantener la productividad en medio del caos.
Conexión remota: Ve más allá de las fronteras geográficas
Como es evidente el impacto del acceso remoto no se limita a una única región. Colombia, por ejemplo, ha experimentado un asombroso aumento del 400% en la cantidad de trabajadores remotos en comparación con años anteriores. Esto subraya y pone en la palestra cómo la adopción de esta práctica ha trascendido fronteras geográficas y se ha convertido en un estribo esencial en la transformación del mundo laboral.
Acceso remoto seguro: Una herramienta para la seguridad y la colaboración
En un escenario donde la ciberseguridad es una prioridad constante, el acceso remoto emerge como una solución pulcra a la par que elegante. Para aquellos que manejan información confidencial o valiosa, este método brinda una alternativa segura al almacenamiento local en dispositivos personales. Al autenticarse en las plataformas empresariales, los trabajadores pueden acceder a datos sin comprometer su integridad ni la de la empresa. La seguridad, por lo tanto, se convierte en una ventaja indiscutible del acceso remoto. La colaboración entre compañeros se ve potenciada por el acceso remoto, ya que las barreras físicas ya no son obstáculos para la comunicación y el trabajo en equipo. Las videoconferencias y las herramientas de administración de tareas pueden activarse con facilidad, permitiendo la interacción y el flujo de trabajo sin importar la distancia. La tecnología de acceso remoto también desempeña un papel vital en la corrección de errores y la entrega de proyectos importantes. Aunque los miembros del equipo no estén presentes físicamente, su contribución puede fluir de manera constante y efectiva, lo que garantiza la eficiencia en los proyectos y la capacidad de respuesta en un mundo laboral en constante cambio.
Productividad laboral: Transformando la dinámica empresarial
En el tejido de la evolución laboral, el acceso remoto se ha convertido en un hilo conductor que une la productividad con la flexibilidad en el trabajo. A medida que exploramos más a fondo esta práctica revolucionaria, se revelan los numerosos beneficios que ofrece a las empresas y sus trabajadores, así como los fundamentos de su funcionamiento. El acceso remoto no sólo redefine la forma en que trabajamos, sino que también impulsa una eficiencia empresarial sin igual. Entre sus beneficios más notables se encuentra un ahorro sustancial de tiempo y dinero. Aunque la inversión inicial en software de acceso remoto pueda parecer un gasto, las recompensas financieras y operativas son significativas. Al eliminar el tiempo de desplazamiento a la oficina, los trabajadores pueden sumergirse rápidamente en sus tareas, mientras que las empresas ahorran en costos de electricidad y suministros. La oficina virtual se erige como una alternativa sostenible y económica, donde solo es necesario encender una computadora o tableta, ingresar las credenciales y estar listo para trabajar.
Componentes y funcionamiento
El acceso remoto se edifica sobre la convergencia de tres elementos clave:
- Software.
- Hardware.
- Conectividad de red.
En la actualidad, estos elementos se sincronizan de manera habitual a través de una red privada virtual (VPN, por sus siglas en inglés), que crea un enlace seguro entre usuarios y sistemas a través de interfaces de red cableadas, conexiones Wi-Fi o incluso Internet. La VPN desempeña un papel trascendental al establecer una conexión entre usuarios individuales y redes privadas. Una vez que el usuario ingresa al software, este cifra el tráfico de datos antes de dirigirlo a través de la red Wi-Fi. Este proceso es conocido como un “túnel VPN”, que asegura la privacidad del flujo de información. Luego, los datos son descifrados y enviados a la red privada específica. Para que este proceso sea exitoso, tanto la computadora desde la que el usuario se conecta como la que busca acceder deben estar equipadas con software de comunicación compatible. Una vez que el usuario se conecta al anfitrión remoto, se otorga acceso a un escritorio virtual que replica el entorno de trabajo convencional.
Implementación exitosa del acceso remoto
La travesía hacia una implementación exitosa del acceso remoto en una empresa es un recorrido emocionante que requiere una planificación meticulosa y una atención a los detalles. A medida que te embarcas en este viaje, aquí te presentamos cuatro consejos fundamentales que te guiarán hacia una transición fluida y segura.
1. Capacitación
La capacitación son los cimientos sobre los cuales se erige una implementación exitosa del acceso remoto. Proporcionar a tus empleados una comprensión clara de cómo funciona y cómo utilizarlo de manera efectiva es esencial. Un enfoque organizado, planificado por áreas y departamentos, asegura que todos estén en la misma página. Al fomentar una comunicación abierta, las dudas pueden resolverse y los obstáculos se superarán con mayor facilidad. Recordemos que una inversión en capacitación no solo impulsa la productividad, sino que también puede aumentar el margen de rentabilidad de la empresa en un 24%.
2. Las herramientas adecuadas
Pertrechar a tus colaboradores con las herramientas necesarias es un paso crucial. Asegúrate de que cada uno cuente con una computadora de escritorio o portátil con el software de acceso remoto instalado. Es fundamental consultar las preferencias de tu equipo y proporcionar alternativas viables. Cada colaborador debe tener un usuario configurado con conectividad VPN para garantizar un acceso seguro.
3. Seguridad en el acceso remoto
La seguridad es el pilar que sustenta cualquier empresa exitosa. *La seguridad y la máquina de café. En el mundo del acceso remoto, se refuerza mediante la autenticación doble. Este enfoque de autenticación multifactor añade una capa adicional de protección, reduciendo la vulnerabilidad a violaciones de seguridad y filtraciones de información. Opciones como el token físico, la autenticación a través del teléfono móvil o la biometría, como la huella digital, son vías efectivas para asegurar que solo las personas autorizadas tengan acceso a la información sensible.
4. Conectividad
La conectividad segura y eficiente es la columna vertebral, que no pilar, ya hemos gastado esa analogía antes, de una implementación exitosa del acceso remoto. La instalación de un punto de acceso inalámbrico respaldado por un firewall robusto es un paso crítico. Los firewalls empresariales líderes no solo protegen contra amenazas cibernéticas, sino que también ofrecen capacidades avanzadas como el monitoreo de red y soporte para conexiones móviles. Estos firewalls pueden ser una defensa vital para garantizar la integridad de la información y mantener la continuidad operativa.
Explorando el Horizonte: Herramientas de acceso remoto.
A medida que te adentras en la implementación del acceso remoto, hay un mundo de herramientas disponibles para hacer que este cambio sea efectivo y beneficioso para tu organización. Compilar una lista de opciones y comparar sus características puede ayudarte a tomar decisiones informadas. Cada herramienta tiene sus propias ventajas, por lo que es importante encontrar la que se ajuste al tamaño de tu empresa, al número de colaboradores y al tipo de industria en la que te encuentres.
Nosotros te aconsejamos Pandora RC
Como culminación de nuestra exploración en el mundo del acceso remoto, presentamos una solución revolucionaria que simplifica y potencia esta práctica esencial:
Pandora RC, un sistema de gestión de equipos compatible con MS Windows®, GNU/Linux® y Mac OS®, es el puente que conecta a los usuarios con sus ordenadores en cualquier lugar y momento, todo a través de un navegador web y sin necesidad de una conectividad directa. Enraizado en una planificación cuidadosa y una implementación efectiva, Pandora RC desvela su magia con un sencillo proceso. Antes de poder acceder remotamente a un dispositivo, es necesario instalar un agente y registrar este en el servidor central de Pandora RC. Este proceso requiere un usuario válido en la plataforma. Una vez configurado el agente con un usuario y activado, se provisionará y estará listo para la conexión remota. El portal de usuario exhibirá los dispositivos provisionados, cada uno identificado con un EKID (Pandora RC Key ID) único. Este identificador, diseñado para una identificación precisa, garantiza la colaboración entre usuarios y permite un seguimiento eficiente en sistemas de inventario internos.
La seguridad es fundamental en Pandora RC.
Cada agente puede tener una contraseña individual configurada durante la instalación o posteriormente. Esta contraseña se introduce interactivamente en cada acceso, asegurando que la información sensible esté protegida y que no se almacene en los servidores centrales de Pandora RC. La arquitectura de Pandora RC garantiza la conectividad fluida. Los agentes se conectan a servidores en internet, y si es necesario, se pueden configurar para utilizar un proxy en caso de que no puedan conectarse directamente.
Conclusiones
En un mundo donde la tecnología trasciende límites y crea nuevos horizontes, el acceso remoto se alza como una puerta abierta a la productividad y la flexibilidad. Este concepto ha transformado la dinámica laboral global, desvaneciendo las barreras físicas y redefiniendo cómo y dónde trabajamos. El acceso remoto ha demostrado su vitalidad en situaciones excepcionales, como lo hizo en la pandemia y lo hará en el apocalipsis, al mantener la continuidad empresarial y permitir que las empresas prosperen en entornos cambiantes. Desde España hasta Colombia, la adopción masiva ha marcado un hito en la evolución laboral, mostrando cómo la colaboración y la eficiencia no conocen fronteras geográficas. La seguridad, una preocupación constante en la era digital, es abordada con soluciones avanzadas de autenticación y encriptación en el acceso remoto. Además, esta práctica facilita la colaboración a distancia, impulsando videoconferencias y flujos de trabajo sin problemas.
La implementación exitosa del acceso remoto requiere capacitación, suministro adecuado de herramientas, seguridad reforzada y conectividad robusta. Este proceso puede ser catalizado por soluciones como Pandora RC, que ha elevado la experiencia del acceso remoto, democratizando la conexión con las máquinas y eliminando las limitaciones de ubicación. En última instancia, el acceso remoto no solo cambia la forma en que trabajamos, sino que redefine la eficiencia, la seguridad y la colaboración en el panorama laboral actual. Una revolución digital que nos invita a navegar hacia un futuro donde la productividad no tiene fronteras y la flexibilidad es la norma.
¿Quieres saber más sobre Pandora RC?

por Pandora FMS team | Last updated Feb 23, 2024 | Monitorización
Aumenta la calidad y la velocidad de la colaboración del equipo en caso de emergencia con Pandora FMS y las funciones de ChatOps de ilert
Pandora FMS es un excelente sistema de monitorización que ayuda a recopilar datos, detectar anomalías y monitorizar dispositivos, infraestructuras, aplicaciones y procesos de negocio. Sin embargo, se necesita más que solo monitorización para administrar todo el ciclo de vida de un incidente. ilert complementa a Pandora FMS en este sentido, al agregar funciones de alerta y gestión de incidentes. Si bien Pandora FMS detecta anomalías, ilert se asegura de que las personas adecuadas reciban las notificaciones correspondientes y puedan tomar medidas rápidamente. Esta combinación ayuda a reducir la media de tiempo de resolución (MTTR) y minimiza el posible impacto en el negocio.
Si bien Pandora FMS e ilert son bases confiables y sólidas para la resiliencia de tu sistema, la magia de la colaboración en equipo y las decisiones de personas reales ocurre en los chats. Este trío de herramientas es indispensable en el mundo empresarial actual. En este artículo, te daremos las mejores recomendaciones prácticas sobre la evolución de tus ChatOps y la mejora en la velocidad y la calidad de la respuesta a incidentes.
¿Qué es exactamente ChatOps?
ChatOps es un modelo que conecta personas, herramientas, procesos y automatización en un flujo de trabajo transparente. Este flujo generalmente se centra en las aplicaciones de chat e incluye bots, plugins y otros complementos para automatizar tareas y mostrar información.
Como modelo, ChatOps se traduce en que toda la comunicación del equipo y las acciones principales se llevan a cabo directamente en una herramienta de chat, lo que supone no tener que cambiar de un servicio a otro y permite organizar el trabajo desde una sola plataforma. Entre toda la variedad de herramientas de chat en el mercado, encontramos, sin duda, dos de las más utilizadas entre los equipos de TI. Esas son Slack y Microsoft Teams. Por arrojar algunos de los datos disponibles, tienen 18 millones y 270 millones de usuarios, respectivamente, y esos números siguen creciendo de forma exponencial en ambas compañías.
Como hay una amplia variedad de implementaciones del modelo ChatOps para el trabajo diario, nos concentraremos específicamente en cómo gestionar los incidentes a través de ChatOps.
ChatOps y gestión de incidentes: ¿De qué se trata exactamente?
La fusión de las plataformas de monitorización y gestión de incidentes con ChatOps es una manifestación de las operaciones modernas de TI que tienen como objetivo optimizar la eficiencia, la velocidad y la colaboración. Al combinar estos paradigmas, las organizaciones pueden capitalizar los puntos fuertes de las herramientas, lo que conlleva una resolución de incidentes simplificada y una mayor visibilidad operativa.
En el núcleo de ChatOps se encuentra la colaboración en tiempo real. Cuando surge un incidente, el tiempo es esencial. La
integración de ChatOps con una plataforma de gestión de incidentes garantiza que todos los miembros del equipo, ya sean desarrolladores, miembros de soporte o administración, estén al tanto del incidente de inmediato. A continuación, pueden diagnosticar, discutir y elaborar estrategias de forma colaborativa sobre los pasos de corrección directamente dentro del entorno de chat. Este tipo de colaboración instantánea entre equipos reduce el tiempo de resolución, lo que garantiza una interrupción mínima del servicio.
Estas son otras ventajas que ofrece ChatOps integrado en tiempos de respuesta a incidentes.
Flujo de información centralizado
ChatOps puede canalizar alertas, diagnósticos y otros datos relevantes desde varias fuentes en un solo canal de chat. Esta consolidación evita el cambio de contexto entre herramientas y garantiza que todos tengan acceso a la misma información.
Concienciación del equipo
Todas las personas involucradas en la respuesta al incidente tienen una visión compartida de la situación. Este contexto compartido reduce la falta de comunicación y garantiza que todos estén al tanto del estado del incidente y la estrategia de respuesta.
Descripción detallada
Cada acción tomada, comando ejecutado y mensaje enviado en un entorno de chat se registra, así como la hora en la que se produjo.
Responsabilidad
Con cada acción de chat atribuida a un miembro del equipo, existe una clara responsabilidad por cada decisión y comando. Esto es especialmente valioso en las revisiones posteriores al incidente para comprender los roles y las contribuciones durante el incidente.
Automatización
A través de los comandos de chat, aquellos que responden pueden activar flujos de trabajo automatizados predefinidos. Esto puede ir desde consultar el estado de un sistema hasta iniciar procesos de recuperación, acelerando así la resolución y reduciendo los esfuerzos manuales.
Accesibilidad
Dado que muchas plataformas de ChatOps están disponibles tanto en ordenadores de escritorio como en dispositivos móviles, quienes responden pueden participar en la gestión de incidentes incluso cuando estén lejos de su lugar de trabajo principal, lo que garantiza que la experiencia sea accesible en cualquier momento y en cualquier lugar.
9 Consejos sobre cómo sacar el máximo provecho de ChatOps en los tiempos de incidentes
ChatOps proporciona un entorno sinérgico que combina la comunicación, la automatización y la integración de herramientas, elevando la eficacia y la eficiencia de la respuesta a incidentes. Pero, ¿qué necesitan exactamente los equipos para descubrir todo el potencial de sus chats?
No profundizaremos en las instrucciones sobre cómo conectar Pandora FMS con la plataforma de gestión de incidentes ilert, pero puedes encontrar información relacionada en la librería de módulos de Pandora FMS y una guía paso a paso en a documentación de ilert. A continuación encontrarás una lista de las mejores prácticas de ChatOps para organizar tu flujo de trabajo cuando recibes una alerta.
Utiliza canales dedicados
Crea canales dedicados para incidentes específicos o alertas de monitorización. Esto contribuye a mantener la conversación centrada en el problema y evita el desorden de los canales generales. Y no olvides establecer un nombre claro para esos canales. En ilert, el título por defecto incluye el nombre de la herramienta de monitorización y el número generado automáticamente de una alerta, por ejemplo, pandorafms_alert_6182268.
Permite a los usuarios informar de incidentes a través de tu herramienta de chat
Permite que todos los usuarios informen incidentes a través de Slack o Microsoft Teams utilizando fuentes de alertas preestablecidas para cada canal. Este enfoque permite a los equipos tener un método estructurado para informar problemas relacionados con los servicios que ofrecen dentro de sus canales dedicados.
Decide qué canales deben ser privados
La mayoría de las herramientas de chat proporcionan funcionalidades para crear canales públicos que puede buscar toda la organización y pueden ser vistos por todos los miembros del equipo, y privados donde solo se puede invitar a personas específicas. Estas son algunas de las razones por las que es posible que desees crear un canal privado:
- Exposición de datos confidenciales. Como información de identificación personal (PII), datos financieros o información de propiedad de la empresa.
- Violaciones de la seguridad de datos. En el caso de un ciberataque o una brecha de seguridad, es importante limitar la información sobre el incidente a un equipo especializado. Esto evita el pánico innecesario y garantiza que los posibles adversarios no obtengan información de las discusiones públicas. Puedes leer más sobre cómo prevenir las filtraciones de datos en el artículo “Higiene cibernética: Evita violaciones de datos”.
- Incidentes de alto riesgo. Si el incidente tiene posibles repercusiones graves para la organización, como un impacto financiero significativo o implicaciones regulatorias, podría ser conveniente restringir la discusión a las partes interesadas clave para garantizar una comunicación controlada y efectiva.
- Evitar las especulaciones. Los canales públicos a veces pueden dar lugar a especulaciones o rumores descontrolados. Lo mejor es mantener las discusiones en privado en caso de incidentes graves, hasta que se aclaren los hechos y se decida cual es la narrativa oficial.
Mantén todas las comunicaciones en un solo lugar
Asegúrate de que todas las decisiones tomadas durante el incidente estén documentadas en el chat. Esto ayuda en las evaluaciones posteriores al incidente.
Fijar mensajes importantes
Utiliza las funciones de fijación para resaltar actualizaciones, decisiones, estados o recursos esenciales para que cualquiera pueda encontrarlos fácilmente.
Mantener informadas a las partes interesadas
Asegúrate de mantener a tu equipo informado y actualiza todas las comunicaciones de incidentes, incluidas las páginas de estado públicas y privadas, a tiempo.
Utiliza chats en la creación post mortem
Los registros de chat en tiempo real en ChatOps capturan un registro cronológico de eventos, discusiones, decisiones y acciones. Durante una creación post mortem, los equipos pueden revisar este conjunto de datos combinado para construir un cronograma integral de incidentes. Una cuenta tan detallada ayuda a identificar las causas fundamentales, identificar los cuellos de botella del proceso y resaltar las estrategias de respuesta efectivas e ineficaces.
Limpia y archiva regularmente
Para mantener la organización y reducir el desorden, archiva regularmente canales antiguos o conversaciones que ya no sean relevantes. Evita tener múltiples canales en tu lista, lo que acelerará el proceso cuando ocurra otro incidente.
Proporcionar capacitación regular para todos los miembros del equipo
Cuanto más familiarizado esté tu equipo con las herramientas, la estructura de alertas, las opciones de chat y las funciones, más rápido será el proceso cuando llegue el momento. Activa alertas de prueba y realiza sesiones de aprendizaje de incidentes para que todos los involucrados conozcan su papel en el ciclo de respuesta a incidentes.
por Pandora FMS team | Last updated Feb 23, 2024 | Monitorización
¿Por qué debería usar ilert con Pandora FMS?
Hay muchas formas de notificar, desde una aplicación de monitorización tan flexible como Pandora FMS, pero por muchas opciones que incluya, no es una aplicación específica para tener en cuenta la complejidad de los flujos de notificación de una organización compleja, que requiere integrar muchos sistemas que generen notificaciones. No es lo mismo detectar cuando un proceso está caído, recibir un evento asíncrono a través de una WEB API o procesar un email, por mencionar tres posibles fuentes de alertas en un entorno complejo. Pandora FMS es bueno en monitorización, hay cientos de integraciones (o plugins) publicados en la librería pública de módulos de Pandora FMS.
Además, recibir un email o un SMS es fácil hoy día, lo complejo es permitir que cada usuario disponga de su sistema de notificación favorito (SMS, email, llamada de voz, Whatsapp, Telegram) y que la configuración sea rápida, fácil y centralizada. Todo es posible, pero lleva tiempo y está sujeto a fallos ¿queremos que falle la notificación porque ha cambiado una API?, ¿de verdad podemos permitirnos no recibir una notificación?
Por eso ilert tiene sentido.
No es porque Pandora FMS no pueda enviar notificaciones de manera directa, es porque a veces, simplemente hace falta implementar una convergencia de notificaciones de otras fuentes, a veces no tenemos tiempo de implementar la complejidad de un workflow de notificaciones complejo que incluyan a tecnologías push como Whatsapp o Telegram y queremos delegar esto en un proveedor en la nube especializado, como ilert.
A todos los efectos ilert actúa como un embudo de notificaciones, que recoge todas las notificaciones de diversos orígenes, una vez recepcionadas, y gracias a un sistema muy completo de escalado, reglas de workflow, sistema de grupos/usuarios y notificaciones, desarrolla todas las acciones necesarias, de manera independiente a las fuentes de las notificaciones, su formato, frecuencia o estructura.
ilert también se puede integrar con su ITSM o utilizarlo para enriquecer alertas. También se puede integrar con Pandora ITSM.
Configuración en 5 minutos
Darse de alta en ilert lleva menos de 30 segundos. Lo siguiente es configurar los usuarios para recibir diferentes tipos de notificaciones: llamada de voz, SMS, Whatsapp, Telegram o email. Desde esta cuenta podemos recibir notificaciones de Pandora FMS o desde un script, desde otra aplicación o de workflows de trabajo tan manuales y dispares como recibir un correo electrónico. La API de ilert es flexible, sencilla y permite echar a andar el proyecto en cuestión de minutos.
Configurando el usuario (y cómo queremos recibir notificaciones)
Lo primero es configurar un usuario (si ya tienes uno creado, es configurar/habilitar los diferentes métodos de notificación). Veamos este ejemplo, donde se configuran el envío de emails (por defecto), los SMS, las llamadas de voz y el Whatsapp:
Para activar cada uno de los sistemas, nos pedirá activarlo. Para hacerlo por Whatsapp nos escribe directamente a mi teléfono móvil para pedirme confirmación, y solo hay que hacer click. Lo mismo ocurre con llamadas de voz, sms, email, etc. No hay que instalar ni hacer nada.
Cada usuario tiene sus propios sistemas de notificación. Se pueden crear grupos de usuarios (teams) y notificar a grupos. Existe la posibilidad de crear reglas de notificación, escalado, etc. La potencia de ilert está en cómo gestiona las notificaciones de terceras fuentes.
Para establecer el “orden” o la prioridad a la hora de notificarnos, se hace en la pantalla de notificación de la configuración de cada usuario:
Configurando el escalado de notificaciones
Si editamos los valores que vienen por defecto, veremos que se trata de un conjunto de reglas sencillas. Permite definir el flujo de escalado de alertas, basándonos en personas. Cada persona/usuario tiene configurado ya su sistema de notificaciones (SMS, llamada, etc).
Dado que toda la lógica del escalado (ventanas de tiempo, repeticiones, workflows) está en ilert , nos podemos olvidar de que los “orígenes de alertas” nos envían multitud de alertas, ilert nos ayudará a filtrar y a clasificar.
Creando orígenes de notificaciones
Aquí es donde empieza lo interesante. Vamos a definir cómo podemos incorporar alertas a ilert . Para que se vea la potencia de ilert , no solo vamos a integrar Pandora FMS, sino que vamos a integrar otras dos fuentes muy diferentes: emails genéricos y otro para uso en una API desde un script.
Alertas ilert usando como fuente un email
Esta es una de las más fáciles. Tan simple como enviar un email a una dirección concreta, y eso lanzará una alerta. Para ello, vamos a Alert sources > Create new alert source y luego filtramos los resultados por “mail”:
Usamos esa fuente (email) y rellenamos algunos datos:
Si no has creado todavía un “Team”, lo podrás crear más adelante. Aceptamos la siguiente pantalla con valores por defecto y configuramos por último el mail al que vamos a enviar las notificaciones:
Pulsamos continuar para terminar el setup:
Ahora solo tenemos que enviar un email desde cualquier aplicación a “[email protected]” para que entre en nuestro embudo de notificaciones.
Alertas ilert usando como fuente a Pandora FMS
De forma muy similar, crearemos una fuente de datos de tipo “Pandora FMS”, que viene por defecto en la librería de fuentes de alertas de ilert.
Tras seguir todos los pasos, nos dará una serie de datos que necesitaremos para integrar la alerta con Pandora FMS:
Ahora toca “conectar” nuestro Pandora FMS con ilert , para ello necesitaremos la API Key. Se puede usar ilert en cualquier versión de Pandora FMS (incluso las más viejas), pero a partir de la versión 775 ya viene “de serie” integrado en el sistema de acciones, vamos a describir cómo implementarlo desde cero, perfecto si tu versión es más antigua. Si ya usas un Pandora FMS 775 o superior te puedes saltar prácticamente todos los pasos siguientes (creación de comando, creación de acción) y puedes editar directamente la acción que viene por defecto con Pandora FMS para ilert para poner el API Key generado en el paso anterior.
Para crear una notificación de ilert con Pandora FMS, tenemos que hacer tres pasos: Crear un comando, una acción y asociar una plantilla de alerta a dicha acción.
Crear el comando en Pandora FMS para llamar a ilert
- Descargamos el script desde la propia librería de plugins de Pandora FMS, en https://pandorafms.com/library/ilert-integration/. En Pandora FMS 775 y sucesivos ya viene instalado de serie, no hay que hacer este paso (además usamos nuestra propia versión de la integración, que es un poco más completa). Para ver como instalar/usar la propia herramienta de ilert , sigue leyendo:Para esto tienes que entrar por shell en el servidor de pandora, descargar el fichero, descomprimirlo y meterlo en el path que se indica. Se resume en los siguientes comandos (ejecutados como root):
cd /tmp
wget https://pandorafms.com/library/wp-content/uploads/2022/11/pandorafms_ilert.sh.zip
unzip pandorafms_ilert.sh.zip
mv pandorafms_ilert.sh /usr/share/pandora_server/util/pandorafms_ilert.sh
chmod 755 /usr/share/pandora_server/util/pandorafms_ilert.sh
- En la consola de Pandora, añadimos un Comando de alerta (In the sidebar, go to Alerts -> Commands and click on the Create button).
- Enter a Name for the command.
- In the Command field enter:
\
sh /usr/share/pandora_server/util/pandorafms_ilert.sh “_field1_” “_field2_” “_id_alert_” “_field3_” “_field4_” “_timestamp_” “_alert_text_severity_” “_agentname_” “_module_” “_data_”/span>
- In the Description field enter:
_field1_ : ilert alert source API key. _field2_ : Type of the created event. Can be “alert” or “resolved”. _field3_ : Title of the event. _field4_ : Description of the event.
Una vez creado, estará disponible como comando:
Creando una acción que use el comando de ilert
Vamos a crear una acción, que es como la alerta, ejecutará el comando (con unos parámetros determinados) para cada caso concreto. Solo vamos a crear un caso (acción) determinado, pero podríamos definir varios si lo necesitáramos. En ella vamos a configurar solo el campo 1 (API Key), copiado de la configuración de ilert y el 2 (tipo de alerta), especificando “Alert” cuando se dispara y “Resolved” cuando se recupera.
De esta manera, cualquier uso que hagamos ahora de la acción “ilert General” llevará ya el APIKey y no tendremos que especificarlo.
Creando una alerta que utilice la acción de ilert
Creamos una alerta sobre un módulo (en este ejemplo, de disco), que usa nuestro comando a través de la acción recién creada:
Alertas ilert usando como fuente una API externa genérica
Imagina que el propio proceso de Pandora FMS no puede levantar porque la BBDD se ha caído ¿cómo lo notificarías?, pues también con ilert .
Para ello vamos a crear un enganche via API, de manera que se pueda llamar desde cualquier script.
Primero crearemos como origen de alerta, una API:
Al terminar de configurarla, nos dará una referencia para poder usarla:
Para poder inyectar una notificación en ilert basta con ejecutar este comando desde cualquier shell:
curl -X POST -H “Content-Type: application/json” \
-d ‘{“apiKey”: “il1api10230c21209d93294006a2fa47528fae069bc8f2f0820e”,”eventType”: “ALERT”,”alertKey”: “Pandora General Alert”,”summary”: “Something goes wrong”}’ https://api.ilert.com/api/events
Lo único que tendrás que cambiar el es apiKey por el tuyo propio. Solo con esta ejecución podrás lanzar una alerta a ilert desde cualquier script. Es una manera perfecta de asegurarse por ejemplo, que si todo falla, por lo menos sepas que todo falla. Si no sabes como hacer ese script, puedes consultar en la comunidad de Pandora FMS, además ser expertos en monitorización, dominamos Linux.
¿Cómo se ve una alerta de ilert?
Por correo electrónico:
Por SMS:
Por Whatsapp:
Y por supuesto, en la interfaz de control de ilert donde podemos hacer muchas cosas con la alerta:
Usos avanzados de ilert: correlación de eventos con Pandora FMS
Con Pandora FMS uno puede monitorizar 20 servidores o 2000. Es fácil imaginar que si tenemos decenas de métricas en cada servidor, ir módulo a módulo para asignarle una alerta es algo tedioso. Tenemos herramientas como las políticas o el gestor de operaciones masivas para asignar cientos de alertas de una sola vez, pero aun así, es complejo y farragoso.
Lo ideal en estos casos es asignar alertas por “conceptos”, veamos algunos casos:
- Asignar una alerta cuando se caigan los procesos MySQL, sin mirar en qué máquinas están. Para ello asignaríamos alertas sobre cualquier evento de caida de un modulo concreto, independientemente del agente.
- Asignar una alerta cuando ocurra algo en módulos marcados con una etiqueta, por ejemplo “Infraestructura crítica”.
- Asignar una alerta cuando suceda algo en cualquier fuente de datos de un grupo de sistemas que pertene a un grupo, por ejemplo “Entorno de producción”.
- Asignar una alerta cuando se den condiciones complejas, por ejemplo: “Caida de cualquier proceso MySQL” en “el grupo de máquinas de producción”.
- Asignar condiciones más complejas, como las anteriores, usando operadores lógicos (AND, OR, NOT, XOR….) en ventanas de tiempo.
Para ello existen las alertas de eventos o alertas de correlación de eventos. Trabajan sobre los eventos generadas por los módulos, no sobre los módulos si sobre sus datos. Esto permite operar sobre conceptos mas genéricos, no sobre datos concretos, ya que un evento de caída de un proceso MySQL es el mismo en una máquina que en otra (si el módulo se llama igual), lo mismo que un evento de Caída es un evento de caída, da igual el agente o da igual el módulo. Por eso, aplicar reglas sobre eventos es mucho mas eficiente e intuitivo que hacerlo sobre módulos.
Ejemplo de definición de una regla de correlación de eventos:
Si a las alertas de eventos además le añadimos ilert , podemos optimizar aún mas el proceso, pues ilert tiene una lógica adicional que podemos usar junto con la de Pandora FMS. Con Pandora FMS es posible establecer calendarios de días especiales, paradas planificadas o franjas de tiempo, también podemos establecer reglas de escalado y muchas otras cosas, pero ilert permite hacerlo sobre alertas de otras fuentes de datos que igual no tiene integradas con Pandora FMS.
Puedes leer más sobre correlación de eventos en Pandora FMS en la documentación online de Pandora FMS.
También puede obtener ayuda online en los foros de soporte y en la comunidad Discord de Pandora FMS.
por Pandora FMS team | Last updated Feb 23, 2024 | ITSM
En un mundo cada vez más dominado por la tecnología, las empresas tecnológicas se han enfrentado a desafíos financieros en diversas ocasiones.
Microsoft
¿Todo el mundo lo conoce, no?
Ha vuelto a ser noticia debido a su decisión de recortar personal, sumando una nueva ola de despidos a los aproximadamente 10.000 empleados que fueron desvinculados a principios de año.
Si bien los recortes en la plantilla de ventas son comunes cuando las empresas buscan reducir costos, no es el único departamento afectado:
Contratación, marketing y funciones de atención al cliente también suelen sentir el impacto cuando la economía se torna incierta.
Un ejemplo claro de esta tendencia se evidenció en Crunchbase, una plataforma de datos empresariales.
Tras anunciar su reciente recorte de personal, se pudo observar en una hoja de cálculo los departamentos en los que la startup consideró que podría ajustar los gastos:
- Ventas.
- Atención al cliente.
- Marketing.
- Contratación.
- Incluso Crunchbase News, un equipo que fomentaba la difusión de noticias relevantes, se vio afectado por esta decisión.
Cabe mencionar que la situación resulta personal para algunos, como aquellos que participaron en la construcción del equipo mientras trabajaban en la empresa y aún conservan acciones de la compañía.
*Los llamaremos “Mártires”.
A pesar de esta tendencia aparentemente arraigada, el panorama de los despidos tecnológicos muestra signos de cambio.
Un análisis detallado de Layoffs.fyi, una base de datos que rastrea los recortes de personal en el sector tecnológico, revela una tendencia interesante en gestación.
Desde el punto álgido de los despidos en enero de 2023, el número de trabajadores tecnológicos afectados por estos recortes ha ido disminuyendo de forma constante.
Esto sugiere que las empresas están encontrando nuevos enfoques para mantener la estabilidad financiera y, al mismo tiempo, retener el talento que impulsa la innovación en el sector.
*Menos mal que alguien se preocupa, ¿no?
A medida que avanzamos en esta era de constante transformación tecnológica, el futuro de los despidos en el ámbito tecnológico se vislumbra incierto.
¿Serán las empresas capaces de encontrar un equilibrio entre la necesidad de ajustar gastos y la preservación del talento?
¿Se convertirán los despidos en una medida menos frecuente?
Estas preguntas permanecerán en el centro del debate mientras las compañías buscan adaptarse a un entorno en constante cambio y se esfuerzan por garantizar un futuro sostenible tanto para sus negocios como para sus empleados.
Impacto de los despidos en el sector tecnológico durante el año 2023
A medida que avanzamos por el año 2023, el sector tecnológico ha sido testigo de una tendencia significativa en lo que respecta a la cantidad de trabajadores despedidos.
Al analizar las cifras recopiladas en Layoffs.fyi, queda patente que el inicio del año fue sombrío para muchos empleados en la industria.
Durante el mes de enero, un asombroso total de 89,554 trabajadores se encontraron sin empleo debido a los recortes efectuados por diversas empresas.
Sin embargo, las cifras comenzaron a mostrar signos de cambio en febrero, cuando la cantidad de despidos se redujo notablemente a 40,011.
Este descenso continuó en marzo, con un total de 37,823 empleados afectados por los recortes en ese mes.
El mes de abril trajo consigo una nueva disminución en los despidos, situándose en 19,864 trabajadores.
A medida que avanzábamos hacia el final del año, la curva descendente continúa, alcanzando los 14,858 despidos en mayo y descendiendo aún más a 10,524 en junio.
Estas cifras reflejan un cambio positivo en la tendencia de los despidos tecnológicos a lo largo del año.
Parece que las empresas han estado buscando otras alternativas para mantener sus operaciones en medio de las dificultades económicas.
*Minipunto para las empresas.
La disminución constante de los despidos sugiere que las compañías están adoptando un enfoque más cauteloso y estratégico para ajustar sus costos, en lugar de recurrir a despidos masivos como primera opción.
Este panorama podría ser una señal de que las empresas tecnológicas están adaptándose a un entorno en constante cambio, encontrando formas más sostenibles de gestionar sus recursos humanos.
Además, la reducción de despidos puede ser una respuesta a la creciente conciencia sobre la importancia del talento y la innovación en el desarrollo del sector tecnológico.
A medida que nos adentramos en la segunda mitad del año, será interesante observar cómo evoluciona esta tendencia.
¿Continuará la disminución de los despidos tecnológicos o habrá factores imprevistos que puedan revertir esta tendencia positiva?
El futuro sigue siendo incierto, pero los datos sugieren que el sector tecnológico está aprendiendo de su pasado y buscando un futuro más estable y equilibrado para sus empleados y su crecimiento sostenible.
Conclusiones: Nueva era de gestión. Reducción de despidos en el ámbito tecnológico
La era de los despidos tecnológicos ha experimentado una transformación significativa en el transcurso del año 2023.
Si bien el inicio del año se caracterizó por un preocupante número de trabajadores despedidos, las cifras han mostrado un decrecimiento constante en los meses subsiguientes.
Este cambio de tendencia sugiere que las empresas tecnológicas están reconsiderando su enfoque hacia la reducción de costos y la gestión de sus recursos humanos.
Tradicionalmente, los recortes en el sector tecnológico han impactado en departamentos como ventas, marketing, contratación y atención al cliente.
*Vaya, siempre marketing, ¡SIEMPRE! ¡FUERZA, CAMARADAS!
**Soy de marketing 🙁
Sin embargo, esta práctica parece estar cediendo espacio a una mentalidad más centrada en la retención del talento y la preservación de la innovación.
Es posible que las compañías estén reconociendo el valor estratégico de contar con empleados altamente calificados y comprometidos en un entorno altamente competitivo.
El análisis de Layoffs.fyi ha proporcionado valiosas perspectivas sobre la evolución de la situación laboral en el sector tecnológico.
La disminución sostenida de los despidos desde enero hasta junio ha sido alentadora y ha planteado la pregunta de si las empresas están adoptando enfoques más equilibrados y responsables para afrontar los desafíos económicos.
La nueva era de estabilidad laboral en el sector tecnológico no solo representa un cambio en las prácticas de gestión, sino también una oportunidad para que las empresas rediseñen su visión de futuro.
Priorizar la inversión en talento y fomentar una cultura empresarial que valore la creatividad y la colaboración puede ser la clave para mantener una ventaja competitiva en un mundo tecnológico en constante cambio.
No obstante, el futuro sigue siendo incierto, y es posible que las condiciones económicas y otros factores imprevistos puedan alterar esta tendencia positiva.
Es fundamental que las empresas continúen siendo ágiles y flexibles en su enfoque para adaptarse a las circunstancias cambiantes.
*Por favor, empresas tecnológicas, no os comporteis tan fríamente con vuestra gente.
por Pandora FMS team | Last updated Feb 23, 2024 | Comunidad
Como buen superhéroe de la tecnología sabrás que en el mundo de la resolución de problemas, hay un enfoque que va más allá de simplemente solucionar los síntomas superficiales. A este enfoque lo llamamos “Heroicidad máxima” o Análisis de causa raíz (ACR), un método encantador que busca desentrañar los misterios que se esconden detrás de un incidente.
A través del ACR, se examinan los factores causales del incidente, se desglosa el porqué, el cómo y el cuándo ocurrió, en aras de evitar su repetición y garantizar la continuidad sin contratiempos.
Prevé problemas, optimiza tus sistemas y procesos con ACR
Imagínate este escenario postapocalíptico: un sistema se rompe o experimenta un cambio inesperado, dejando perplejos a quienes dependen de él.
Aquí es cuando entra en juego el ACR, como una herramienta indispensable para comprender plenamente el incidente y lo que lo desencadenó.
A diferencia de la simple resolución de problemas, que se centra en tomar medidas correctivas una vez que el incidente ha ocurrido, el ACR va más allá, buscando desvelar la causa raíz del problema.
En ocasiones, el ACR también se utiliza para investigar y comprender el funcionamiento de un sistema en particular, así como su superioridad en comparación con otros sistemas similares.
Sin embargo, en la mayoría de los casos, el análisis de causa raíz se concentra en los problemas, especialmente cuando estos afectan a sistemas críticos.
Mediante un ACR, se logra identificar y conectar todos los factores contribuyentes al problema de manera significativa, lo que permite un abordaje adecuado y, lo más importante, evita que la misma adversidad se repita una y otra vez.
Solo al llegar “a la raíz” del problema, en lugar de enfocarse en los síntomas superficiales, se puede descubrir cómo, cuándo y por qué surgió el problema en primer lugar.
Los problemas que justifican un análisis de causa raíz pueden ser variados y provienen de diversas fuentes, desde errores humanos hasta fallos en sistemas físicos, pasando por deficiencias en los procesos u operaciones de una organización.
En esencia, cualquier tipo de anomalía que afecte al funcionamiento óptimo de un sistema puede requerir la implementación de un ACR.
Ya sea que se trate de una maquinaria defectuosa en una planta de fabricación, un aterrizaje de emergencia en un avión o una interrupción del servicio en una aplicación web, los investigadores se embarcan en un viaje para desvelar las capas ocultas de cada incidente, en busca de la solución definitiva.
Persiguiendo la mejora continua: Los beneficios del análisis de causa raíz
Cuando se trata de mantener la integridad y el funcionamiento impecable de una organización, el análisis de causa raíz se convierte en un aliado invaluable.
Con el objetivo principal de reducir el riesgo en todos los niveles, este proceso revelador brinda información vital que se puede utilizar para mejorar la confiabilidad de los sistemas.
Pero, ¿cuáles son exactamente los objetivos y las ventajas de realizar un análisis de causa raíz?
En primer lugar, el análisis de causa raíz, como ya sabemos, busca identificar con precisión lo que realmente ha estado sucediendo, yendo más allá de los síntomas superficiales para desentrañar la secuencia de eventos y las causas fundamentales.
Comprender qué se necesita para resolver el incidente o aprovechar el aprendizaje extraído de él, teniendo en cuenta sus factores causales, es otro de los objetivos clave del ACR.
Además, aplicar este conocimiento adquirido con el fin de prevenir la repetición del problema o duplicar las condiciones subyacentes es un logro fundamental del análisis de causa raíz.
Cuando se alcanzan estos objetivos, un ACR puede brindar una serie de beneficios significativos a una organización.
En primer lugar, se optimizan los sistemas, procesos y operaciones al proporcionar información valiosa sobre los problemas y obstáculos subyacentes.
Además, se evita la repetición de problemas similares, lo que conlleva una mejora en la calidad de la gestión.
Al abordar los problemas de manera más efectiva y exhaustiva, se logra ofrecer servicios de mayor calidad a los clientes, generando así su satisfacción y fidelidad.
El análisis de causa raíz también promueve la mejora de la comunicación y la colaboración internas, al tiempo que fortalece el conocimiento de los sistemas subyacentes.
Además, al llegar rápidamente a la raíz del problema en lugar de tratar únicamente los síntomas, se reduce significativamente el tiempo y los esfuerzos invertidos a largo plazo en la resolución de problemas recurrentes.
Por si fuera poco, esta aproximación eficiente también permite reducir costes al abordar directamente la raíz del problema, en lugar de enfrentarse continuamente a los síntomas sin resolver.
Es importante destacar que el análisis de causa raíz no se limita a un solo sector, sino que puede beneficiar a una amplia gama de industrias.
Desde mejorar los tratamientos médicos y reducir las lesiones en el trabajo, hasta optimizar el rendimiento de las aplicaciones y garantizar la disponibilidad de las infraestructuras, esta metodología tiene el potencial de impulsar la excelencia en diversos sistemas y procesos.
Los cimientos del Análisis de causa raíz: Principios para el éxito
El análisis de causa raíz es una metodología lo suficientemente versátil como para adaptarse a diversas industrias y circunstancias individuales.
Sin embargo, en el núcleo de esta flexibilidad, existen cuatro principios fundamentales que son esenciales para garantizar el éxito del ACR:
Comprender el porqué, el cómo y el cuándo del incidente: Estas preguntas trabajan en conjunto para proporcionar una imagen completa de las causas subyacentes.
Por ejemplo, resulta difícil comprender por qué ocurrió un evento si no se comprende cómo o cuándo sucedió.
Los investigadores deben explorar la magnitud completa del incidente y todos los factores clave que contribuyeron a su ocurrencia en el momento preciso.
-
Enfocarse en las causas subyacentes, no en los síntomas: Abordar únicamente los síntomas cuando surge un problema rara vez evita que se repita y puede resultar en una pérdida de tiempo y recursos.
En cambio, el ACR se centra en las relaciones entre los eventos y las causas profundas del incidente.
Este enfoque ayuda a reducir el tiempo y los recursos dedicados a resolver problemas y garantiza una solución sostenible a largo plazo.
-
Pensar en la prevención al utilizar el ACR para resolver problemas: Para que sea efectivo, el análisis de causa raíz debe llegar a las causas fundamentales del problema, pero eso no es suficiente.
También debe permitir la implementación de soluciones que eviten que el problema vuelva a ocurrir.
Si el ACR no ayuda a resolver el problema y prevenir su recurrencia, gran parte del esfuerzo habrá sido en vano.
-
Hacerlo bien desde el principio: Un análisis de causa raíz sólo es exitoso en la medida en que se realice de manera adecuada.
Un ACR mal ejecutado puede desperdiciar tiempo y recursos e incluso empeorar la situación, obligando a los investigadores a comenzar de nuevo.
Un análisis de causa raíz efectivo debe llevarse a cabo cuidadosa y sistemáticamente.
Requiere los métodos y herramientas adecuados, así como un liderazgo que comprenda lo que implica el esfuerzo y lo respalde plenamente.
Siguiendo estos principios fundamentales, el análisis de causa raíz se convierte en una herramienta poderosa para desentrañar las causas profundas de los problemas y lograr soluciones duraderas.
Al comprender plenamente los incidentes, enfocarse en las causas subyacentes y adoptar un enfoque preventivo, las organizaciones pueden evitar la repetición de problemas y mejorar su rendimiento de manera continua.
En última instancia, el análisis de causa raíz se convierte en el cimiento sobre el cual se construye una cultura de mejora constante y excelencia.
Un abanico de herramientas: Métodos para el Análisis de causa raíz
Cuando se trata de desentrañar las causas profundas de un problema, el análisis de causa raíz ofrece una variedad de métodos efectivos.
Uno de los enfoques más populares es el de los 5 porqués, donde se plantean preguntas sucesivas de “por qué” para llegar a las causas subyacentes.
Este método busca seguir indagando hasta descubrir las razones que explican el origen del problema.
Si bien el número cinco es solo una guía, pueden requerirse menos o más preguntas “por qué” para llegar a las causas fundamentales del problema inicialmente definido.
Otro método ampliamente utilizado en el ACR es el “Diagrama de Ishikawa”, también conocido como “Diagrama de causa y efecto” o “Diagrama de espina de pescado”.
En este enfoque, el problema se define en la cabeza de la espina de pescado, mientras que las causas y los efectos se despliegan en las ramas.
Las posibles causas se agrupan en categorías que se conectan a la espina dorsal, brindando una visión global de las posibles causas que podrían haber provocado el incidente.
Además, los investigadores cuentan con varias metodologías para realizar un análisis de causa raíz:
-
Análisis modal de fallos y efectos (AMFE): Identifica las diversas formas en que un sistema puede fallar y analiza los posibles efectos de cada fallo.
-
Análisis del árbol de fallos (AEF): Proporciona un mapa visual de las relaciones causales utilizando la lógica booleana para determinar las posibles causas de un fallo o evaluar la fiabilidad de un sistema.
-
Diagrama de Pareto: Combina un diagrama de barras y un diagrama de líneas para mostrar la frecuencia de las causas más comunes de los problemas, desde la más probable hasta la menos probable.
-
Análisis de cambios: Considera cómo han cambiado las condiciones que rodean el incidente a lo largo del tiempo, lo cual puede desempeñar un papel directo en su aparición.
-
Diagrama de dispersión: Representa los datos en un gráfico bidimensional con un eje X y un eje Y para descubrir las relaciones entre los datos y las posibles causas de un incidente.
-
Además de estos métodos, existen otros enfoques utilizados en el análisis de causa raíz. Aquellos profesionales que se dedican a este análisis y buscan la mejora continua de la fiabilidad deben estar familiarizados con varios métodos y utilizar el más adecuado para cada situación específica.
El éxito del análisis de causa raíz también depende de una comunicación efectiva dentro del grupo y el personal involucrado en el sistema.
Las reuniones informativas posteriores al ACR, comúnmente conocidas como “post-mortem”, ayudan a asegurar que los principales interesados comprendan los factores causales y relacionados, sus efectos y los métodos de resolución utilizados.
El intercambio de información en estas reuniones también puede dar lugar a una lluvia de ideas sobre otras áreas que podrían requerir una investigación adicional y sobre quién debería encargarse de cada una de ellas.
Uniendo fuerzas: Herramientas para el Análisis de causa raíz
El análisis de causa raíz es un proceso que combina la habilidad humana para la deducción con la recopilación de datos y el uso de herramientas de informes.
Los equipos de tecnología de la información (TI) a menudo aprovechan las plataformas que ya utilizan para la supervisión del rendimiento de las aplicaciones, la supervisión de la infraestructura o la gestión de sistemas, incluyendo herramientas de gestión en la nube, para obtener los datos necesarios que respalden el análisis de causa raíz.
Muchos de estos productos también incluyen funciones integradas en sus plataformas para facilitar el análisis de causa raíz.
Además, algunos proveedores ofrecen herramientas especializadas que recopilan y correlacionan métricas de otras plataformas, lo que ayuda a remediar problemas o eventos disruptivos.
Las herramientas que incorporan capacidades de AIOps (Inteligencia Artificial para Operaciones de TI) son capaces de aprender de eventos pasados y sugerir acciones correctivas para el futuro.
Además de las herramientas de monitorización y análisis, las organizaciones de TI a menudo buscan fuentes externas para obtener ayuda en el análisis de causa raíz.
La colaboración y la utilización de recursos externos son aspectos valiosos en el análisis de causa raíz.
Al aprovechar las herramientas existentes y buscar conocimientos adicionales en comunidades y plataformas en línea, los equipos de TI pueden obtener una perspectiva más completa y enriquecedora.
Estas sinergias permiten abordar los problemas de manera más efectiva y lograr soluciones duraderas.
Conclusiones
El análisis de causa raíz emerge como una poderosa metodología para comprender las causas subyacentes de los problemas y los incidentes que enfrentan las organizaciones.
A lo largo de este artículo, hemos explorado en detalle qué es el análisis de causa raíz, sus objetivos y ventajas, así como los principios fundamentales que lo respaldan.
El análisis de causa raíz nos invita a ir más allá de los síntomas superficiales y descubrir las verdaderas causas que se esconden detrás de un incidente.
Mediante el uso de diversos métodos y herramientas, como los 5 porqués, los diagramas de Ishikawa, el AMFE, el AEF y muchas otras, los profesionales del ACR se embarcan en un viaje psicotrópico de descubrimiento para identificar las causas fundamentales y evitar que los problemas se repitan.
Alcanzar los objetivos del análisis de causa raíz, como comprender plenamente los eventos, aplicar soluciones preventivas y mejorar la calidad de los sistemas y procesos, conlleva una serie de beneficios de los que podrás presumir luego con un café.
Desde la optimización de sistemas y operaciones hasta la mejora de la calidad de los servicios, la reducción de costos y la promoción de la colaboración interna, el análisis de causa raíz se convierte en un habilitador de la mejora continua y la excelencia organizacional.
En este proceso, la elección adecuada de herramientas y métodos es crucial.
Las organizaciones pueden aprovechar las herramientas existentes de monitorización, análisis y gestión de sistemas, así como buscar conocimientos adicionales en fuentes externas.
La colaboración y el intercambio de información juegan un papel vital en el éxito del análisis de causa raíz, ya que permiten obtener perspectivas más amplias y enriquecedoras.
El análisis de causa raíz es un poderoso aliado de La Fuerza y de las organizaciones en su búsqueda de soluciones efectivas y duraderas.

por Dimas Pardo | Last updated Oct 13, 2023 | Comunidad
Los desarrolladores de software y fabricantes de todo el mundo están siendo atacados por ciberdelincuentes. No es que estemos en una época del año en la que cundan más y se atrincheren, frente a las oficinas, con sus portátiles malignos buscando hacer saltar todo por los aires, no. Siempre están ahí en realidad, intentando vulnerar la seguridad de la información, y en este artículo vamos a daros un poco de asesoramiento sobre el tema.
Nadie está a salvo de todas las amenazas
Ya sea un ataque de medio pelo o sofisticado y destructivo (Como les pasó a nuestros competidores de Solarwinds y Kaseya) el mal nunca descansa. Toda la industria se enfrenta a un panorama de amenazas cada vez más exasperante. Casi siempre amanecemos con alguna noticia de un ciberataque imprevisto que trae consigo la consecuente ola de actualizaciones urgentes y necesarias para que nuestro sistema se encuentre a salvo…. No se salva nadie, han caído verdaderos gigantes. La complejidad del ecosistema actual de software hace que la vulnerabilidad en una pequeña librería afecte a cientos de aplicaciones. Sucedió en el pasado (openssh, openssl, zlib, glibc…) y seguirá sucediendo.
Como hemos apuntado, estos ataques pueden ser muy sofisticados o pueden ser fruto de una combinación de debilidades de terceras partes que hacen vulnerable al cliente, no por el software, pero sí por alguno de los componentes de su entorno. Por eso los profesionales de TI deberían exigir a sus proveedores de software que se tomen en serio la seguridad, tanto desde el punto de vista de ingeniería como desde la gestión de las vulnerabilidades.
Repetimos: Nadie está a salvo de todas las amenazas. El proveedor de software que ayer le quitó el negocio a otros puede ser muy probablemente la nueva víctima de mañana. Sí, el otro día fue Kaseya, mañana podemos ser nosotros. Da igual lo que hagamos, no existe la seguridad 100%, nadie puede prometerla. La cuestión no es evitar que suceda algo malo, la cuestión es cómo se gestiona esa situación y se sale de ella.
Pandora FMS y el Sgsi Iso 27001
Cualquier proveedor de software puede ser atacado y que cada proveedor debe tomar las medidas necesarias adicionales para protegerse a sí mismo y a sus usuarios. Pandora FMS anima a nuestros clientes, actuales y futuros, a pedir a sus proveedores mayor consideración en este tema. Nos incluimos.
Pandora FMS siempre se ha tomado muy en serio la seguridad, tanto es así que desde hace años disponemos de una política pública de “Vulnerability disclosure policy” y Artica PFMS como empresa, está certificada en la ISO 27001. Periódicamente pasamos herramientas de auditorías de código y mantenemos localmente algunas versiones modificadas de librerías comunes.
En 2021, en vista de la demanda en el tema de la seguridad, decidimos dar un paso más, y hacernos CNA de CVE para dar una respuesta mucho más directa a las vulnerabilidades de software reportadas por auditores independientes.
Decálogo de PFMS para una mejor seguridad de la información
Cuando un cliente nos pregunta si Pandora FMS es segura a veces le recordamos toda esta información, pero no basta. Por ello, hoy queremos ir más allá y elaborar un decálogo de preguntas reveladoras sobre el tema, sí, porque algunos desarrolladores de software se toman un poco más en serio la seguridad que otros. Tranquilos, estas cuestiones y sus correspondientes respuestas valen tanto para Microsoft como para Paco Software. Ya que la seguridad no distingue entre grandes, pequeños, tímidos o expertos del marketing.
¿Hay un espacio específico para la seguridad dentro de su ciclo de vida de software?
En Pandora FMS tenemos una filosofía AGILE con sprints (releases) cada cuatro semanas, y disponemos de una categoría específica para tickets de seguridad. Estos tienen una prioridad diferente, un ciclo de validación (Q/A) diferente y por supuesto, una gestión totalmente diferente, ya que implican a actores externos en algunos casos (CVE mediante).
¿Su sistema de CICD y versionado de código está ubicado en un entorno seguro y dispone de medidas específicas de seguridad para asegurarlo?
Utilizamos Gitlab internamente, en un servidor en nuestras oficinas físicas de Madrid. A él tienen acceso personas con nombre y apellidos, y usuario y password único. Da igual en qué país estén, su acceso a través de VPN está controlado de manera individual y a este servidor no se puede acceder de otra manera. Nuestra oficina está protegida por un sistema de acceso biométrico y la sala de servidores con una llave que solo tienen dos personas.
¿La empresa desarrolladora dispone de un SGSI? (Sistema de Gestión de Incidencias de Seguridad?)
Artica PFMS; la empresa detrás de Pandora FMS está certificada con la ISO 27001 casi desde sus orígenes. Nuestra primera certificación fue en el año 2009. La ISO 27001 certifica que existe un SGSI como tal en la organización.
¿La empresa desarrolladora dispone de un plan de contingencia?
No solo disponemos de uno, si que lo hemos tenido que usar varias veces. Con el COVID pasamos de trabajar 40 personas en una oficina de Gran vía (Madrid) a trabajar cada uno en su casa. Hemos tenido caídas de suministro eléctrico (durante semanas), incendio de servidores y otras muchas incidencias que nos han puesto a prueba.
¿La empresa desarrolladora dispone de un plan de comunicación ante incidencias de seguridad que incluya a sus clientes?
No ha ocurrido en muchas ocasiones, pero hemos tenido que sacar algun parche de seguridad urgente, y hemos notificado a nuestros clientes, en tiempo y en forma.
¿Existe una trazabilidad atómica y nominal sobre los cambios en el código?
Lo bueno de los repositorios de código, como GIT, es que este tipo de cuestiones llevan resueltas mucho tiempo. Es imposible desarrollar software de manera profesional hoy día si herramientas como GIT no están totalmente integradas en la organización, y no solo al equipo de desarrollo, sino también el equipo de Q/A, soporte, ingeniería…
¿Dispone de un sistema fiable de distribución de actualizaciones con firmas digitales?
Nuestro sistema de actualización (Update Manager) distribuye paquetes con firma digital. Es un sistema privado, debidamente securizado y con tecnología propia.
¿Tiene una política abierta de divulgación de vulnerabilidades pública?
En nuestro caso, está publicada en nuestra web.
¿Tiene una política de Código Abierto que permita al cliente observar y auditar el código de la aplicación en caso de necesidad?
Nuestro código es abierto, cualquier persona lo puede revisar en https://github.com/pandorafms/pandorafms. Además, algunos de nuestros clientes nos piden poder auditar el código fuente de la versión enterprise y nosotros estamos encantados de poder hacerlo.
¿Los componentes / adquisiciones de terceras partes cumplen los mismos estándares del resto de partes de la aplicación?
Sí lo hacen y cuando no lo cumplen los mantenemos nosotros.
BONUS TRACK:
¿Dispone la empresa de alguna certificación ISO de Calidad?
ISO 27001
¿Dispone la empresa de alguna certificación específica de seguridad?
Esquema Nacional de Seguridad, nivel básico.
Conclusión
Pandora FMS está preparado y armado para ¡TODO! Es broma, como hemos dicho, todos en este sector somos vulnerables, y claro que las preguntas de este decálogo están elaboradas con un cierta astucia, después de todo teníamos sólidas y veraces respuestas preparadas de antemano para ellas, sin embargo, la verdadera cuestión es ¿Tienen todos los proveedores de software respuesta?
Si tienes que monitorizar más de 100 dispositivos también puedes disfrutar de un TRIAL GRATUITO de 30 días de Pandora FMS Enterprise. Instalación en Cloud u On-Premise, ¡¡tú eliges!!
Por último, recuerda que si cuentas con un número reducido de dispositivos para monitorizar puedes utilizar la versión OpenSource de Pandora FMS. Encuentra más información aquí.
No dudes en enviar tus consultas.¡El equipazo que se encuentra detrás de Pandora FMS estará encantado de atenderte!

por Dimas Pardo | Last updated Feb 23, 2024 | Atención al cliente
Si tienes esa innata vocación por ayudar a los demás, y no has podido con el voto de castidad que requiere la Iglesia, ni con la hipocresía de algunas ONG, sumergirte en el emocionante mundo de la atención al cliente puede ser la elección perfecta para ti.
Desde el bullicio del comercio minorista hasta los encantos de la hostelería, las oportunidades laborales en este campo son prácticamente infinitas.
Sin importar cuáles sean tus intereses particulares, siempre podrás encontrar un puesto que se ajuste a tus metas profesionales a corto y largo plazo.
Imagina tener la oportunidad de marcar la diferencia en la vida de las personas a diario. Como Superman o, en su día, Indurain.
Sin embargo, no podemos ignorar el hecho de que el campo de la atención al cliente es altamente competitivo.
¿Cómo lograr que tu currículum y tu carta de presentación destaquen por encima del resto?
La clave está en comprender la necesidad de un currículum especializado.
Demasiado a menudo, los solicitantes de empleo se conforman con un currículum genérico que utilizan para postular a cualquier puesto, sin hacer apenas modificaciones.
Pero aquí está la cruda verdad:
Los currículums genéricos rara vez alcanzan el éxito, especialmente cuando se trata de puestos de atención al cliente.
Si realmente deseas destacar, debes invertir tiempo en actualizar y personalizar tu currículum para cada puesto específico al que te postules.
En la actualidad, los reclutadores y los equipos directivos buscan candidatos que demuestren haber adaptado su currículum y su experiencia previa, con el objetivo de mostrar por qué son el mejor candidato para el puesto.
Esto significa que debes redactar tu objetivo, experiencia laboral, habilidades y demás secciones del currículum desde una perspectiva centrada en el servicio al cliente.
No hay lugar para currículums duplicados; cada uno debe ser único y sobresaliente.
Pero, ¿cómo puedes lograrlo? No te preocupes, estamos aquí para guiarte en el proceso de redacción de un currículum que te ayude a destacar entre la multitud y captar la atención de los empleadores.
*Recuerda, tu currículum es tu carta de presentación y la oportunidad de mostrar tu pasión por el servicio al cliente. Prepárate para impresionar a los reclutadores y abrir las puertas hacia una exitosa carrera en el apasionante mundo de la atención al cliente.
Para un currículum especializado: destaca tu experiencia más relevante
Cuando se trata de abordar la sección de “empleos anteriores” en tu currículum, es importante que te centres en tu experiencia más relevante en lugar de seguir el enfoque cronológico inverso.
Esta estrategia es especialmente útil cuando tu experiencia profesional más pertinente no es tu puesto más reciente.
¿Cómo debes abordar esta situación en tu currículum?
Lo ideal es que tu experiencia laboral más relevante aparezca en primer lugar en la sección de empleo de tu currículum, lo que significa, insistimos, que no debes seguir el orden cronológico inverso tradicional.
Una forma efectiva de lograrlo es dividir tu experiencia laboral en dos secciones:
“Experiencia profesional relevante” y “Otra experiencia laboral”, por ejemplo.
*Sí, ya sé que parecen títulos anodinos, pero son la mar de específicos.
De esta manera, puedes resaltar todos tus trabajos relevantes en atención al cliente cerca de la parte superior de tu currículum, donde es más probable que los reclutadores lo noten, mientras utilizas la otra sección para mostrar que también ha tenido empleos estables en otros campos.
Ahora bien, al describir tus puestos anteriores, es importante renovar tus descripciones utilizando las “palabras de moda” del sector.
Ya tú sabeh.
Ten en cuenta que quienes revisen tu currículum probablemente no tendrán tiempo para leerlo detenidamente.
En cambio, lo ojearán en busca de información relevante.
Es aquí donde las palabras clave cobran importancia.
Además, si tienes experiencia en el uso de las redes sociales para atraer clientes asegúrate de destacarlo.
Cada vez más, se valora la capacidad de los profesionales de atención al cliente para gestionar las redes sociales de las empresas, como Facebook, Twitter, Instagram, y otras plataformas.
Personalización del currículum: el camino hacia el éxito
En la búsqueda de empleo, cada puesto tiene sus propias particularidades y requerimientos.
Por lo tanto, es esencial adaptar tu currículum y solicitud para un puesto de cajero de manera diferente a la solicitud para un puesto de supervisor de comercio minorista.
Mientras que un currículum para cajero resalta tus habilidades en manejo de efectivo y resolución de problemas, un puesto de supervisor requiere un enfoque en habilidades de liderazgo y comunicación.
Cuando te encuentres buscando ofertas de empleo en atención al cliente y decidas postularte, una de las mejores estrategias que puedes seguir es incorporar toda la información relevante del puesto en tu currículum.
*Por ejemplo, si un anuncio de empleo para un representante de centro de llamadas busca candidatos que puedan trabajar en entornos de ritmo rápido y resolver conflictos, debes adaptar partes específicas de tu currículum para reflejar esas habilidades en ti mismo.
Esto puede incluir ejemplos concretos de roles previos en los que hayas trabajado en entornos de alta velocidad o situaciones en las que se te haya confiado la resolución de problemas.
Cuanto más personalizado esté tu currículum para el puesto al que te postulas, mayores serán tus posibilidades de recibir una llamada para una entrevista.
Además, no te olvides de resaltar tus logros pasados.
Uno de los errores más comunes al redactar un currículum de atención al cliente es no enfatizar los logros previos con ejemplos concretos.
Este es tu momento para brillar, cual Gisela (OT 1) en Frozen, y destacar entre los demás solicitantes de empleo.
Si lideraste exitosamente a tu equipo de ventas, logrando el primer puesto en ventas a nivel regional, o si recibiste un premio por satisfacción al cliente en un empleo anterior, ¡esto es algo que definitivamente debes incluir en tu currículum!
Dedica una sección específica al final del currículum para resaltar premios y reconocimientos especiales, y aprovecha los espacios en cada lista de empleos para incluir ejemplos concretos de tus logros.
Destacando tu estabilidad laboral y formación relevante en el currículum
En el competitivo campo de la atención al cliente, la estabilidad laboral es un factor cada vez más valorado por las empresas.
Con tasas de rotación tan altas, resaltar tu historial de permanencia en puestos anteriores puede marcar la diferencia frente a otros candidatos con habilidades y experiencia similares.
Si has trabajado en una empresa durante varios años, aprovecha esta oportunidad para destacar tu compromiso y fiabilidad en tu currículum.
*Dedica una sección especial a resaltar tu estabilidad laboral, especialmente si has estado en un puesto durante un período prolongado.
Esto mostrará a los empleadores potenciales que eres alguien en quien pueden confiar y que tienes la capacidad de mantener una relación a largo plazo con una empresa.
En caso de que haya lagunas en tu historial de empleo de más de cinco años, considera incluir solo los últimos cinco años de experiencia laboral para evitar resaltar esas brechas, especialmente si tus trabajos anteriores no están directamente relacionados con la atención al cliente.
Además, no olvides mencionar los cursos y estudios relevantes que has realizado.
Incluso si no has obtenido un título, puedes incluir los cursos universitarios que hayas completado como “cursos relevantes”.
Examina las clases que has tomado y selecciona aquellas que sean pertinentes para el trabajo en atención al cliente.
Por ejemplo, un curso de comunicación o un idioma extranjero puede ser muy valioso en el trato con clientes que hablan diferentes idiomas.
Explica brevemente cómo estos cursos te han ayudado a desarrollar habilidades específicas en el campo de la atención al cliente, como la resolución de conflictos y la comunicación efectiva.
Presentación del curriculum y formato
La presentación adecuada y el formato de un currículum de atención al cliente son elementos cruciales para captar la atención de los reclutadores y destacar entre la competencia.
Es esencial tener en cuenta tanto la longitud como el diseño para garantizar que tu currículum sea efectivo y transmita la información de manera clara y concisa.
En primer lugar, debes tener en cuenta que los reclutadores suelen dedicar poco tiempo a revisar cada currículum.
*Por tanto, es recomendable mantener tu currículum en una sola página impresa.
Evita la tentación de incluir todos los detalles de tus experiencias laborales anteriores.
En su lugar, enfócate en los aspectos más relevantes y destacados de tu trayectoria.
El formato lógico de tu currículum es igualmente importante.
Comienza con tus datos de contacto, como tu nombre, número de teléfono, dirección de correo electrónico y domicilio.
A continuación, considera incluir una breve declaración de objetivos en la que expreses tu interés en el puesto específico al que estás aplicando.
Esto puede ser especialmente útil cuando solicitas un puesto en una empresa que está contratando para varios roles simultáneamente.
Posteriormente, presenta tu experiencia educativa y laboral relevante, resaltando aquellos roles y responsabilidades que demuestren tus habilidades en atención al cliente.
Recuerda adaptar esta sección a cada puesto al que te postules, enfatizando las tareas y logros que se alineen con los requisitos específicos de cada empleador.
*Una lista de habilidades específicas también puede ser de gran utilidad.
Incluye aquellas competencias que sean relevantes para el puesto de atención al cliente, como la capacidad de resolución de problemas, la comunicación efectiva y el enfoque en la satisfacción del cliente.
Además, si tienes premios o reconocimientos destacados, puedes mencionarlos en una sección aparte para resaltar tus logros pasados.
En cuanto a las referencias, a menos que se soliciten específicamente en la solicitud, no es necesario incluirlas en tu currículum.
En su lugar, puedes indicar que las referencias estarán disponibles a petición.
Conclusiones
Si estás buscando una carrera emocionante y gratificante en el campo de la atención al cliente, es importante que te destaques entre la multitud de solicitantes.
No te conformes con un currículum genérico, sino que invierte tiempo en personalizarlo para cada puesto al que te postules.
Recuerda que los reclutadores buscan candidatos que demuestren haber adaptado su experiencia y habilidades al servicio al cliente.
Destaca tu experiencia más relevante y utiliza palabras clave relevantes para captar la atención de los empleadores.
Personaliza tu currículum para cada puesto, resaltando las habilidades específicas que se requieren.
No olvides resaltar tus logros pasados y premios recibidos, ya que esto puede marcar la diferencia.
Además, la estabilidad laboral y la formación relevante son aspectos valorados en el campo de la atención al cliente.
Destaca tu historial de permanencia en puestos anteriores y menciona los cursos y estudios pertinentes que has realizado.
Por último, presta atención a la presentación y formato de tu currículum.
Manténlo en una página impresa y organízalo de manera lógica.
Comienza con tus datos de contacto, seguido de una declaración de objetivos y tu experiencia educativa y laboral relevante.
Destaca tus habilidades y menciona premios y reconocimientos destacados en secciones separadas.
Así que levántate del sofá y prepárate para impresionar a los reclutadores y adéntrate en el apasionante mundo de la atención al cliente.
Con un currículum personalizado y bien presentado, estarás un paso más cerca de conseguir la carrera de tus sueños y marcar la diferencia en la vida de las personas a diario. Como Wonder Woman o, en su día, Gisela.
¡Buena suerte y vuelve a este artículo para dejar un mensaje si lo conseguiste!

por Dimas Pardo | Last updated Feb 23, 2024 | Monitorización
Es el momento, coge tus cosas y partamos hacia una monitorización más moderna. Tranquilo, sé lo difícil que son para ti los cambios, pero si pudiste aceptar la llegada del TDT y el euro, también puedes con esto. Pero antes demos un pequeño repaso: Las soluciones tradicionales de monitorización de sistemas se basan en sondear diferentes contadores, como el protocolo simple de gestión de red (SNMP), para extraer datos y reaccionar ante ellos. Cuando se detecta un problema que requiere atención, se activa un evento, que puede ser notificado mediante un correo electrónico al administrador o mediante el lanzamiento de una alerta. En consecuencia, el administrador responde de acuerdo a la naturaleza del problema. Sin embargo, este enfoque centralizado de monitorización demanda una considerable cantidad de recursos.
¿Lo sabías?
Debido a la naturaleza “pull” de las solicitudes, se generan lagunas en los datos y estos podrían carecer de la suficiente granularidad. En respuesta a esta limitación, la adopción de una solución de monitorización basada en telemetría ha surgido como una alternativa prometedora.
Ha llegado el día: descubre una monitorización más moderna
Al hacer el cambio hacia un enfoque moderno de la monitorización, se obtiene acceso a soluciones más inteligentes y ricas en términos de detección de anomalías. Esta transición representa una gran ventaja en el campo de la monitorización de sistemas. Además, otra razón de peso para implementar una monitorización moderna es el número creciente de sistemas que dependen de una monitorización precisa para activar operaciones de infraestructura automatizadas, como la ampliación o reducción de nodos. Si la monitorización falla o no es lo suficientemente precisa, pueden surgir interrupciones en la escalabilidad esperada de una aplicación. Por lo tanto, es fundamental contar con una monitorización confiable y precisa para garantizar el correcto funcionamiento de los sistemas. Con el objetivo de mejorar la eficiencia y la precisión de los sistemas de vigilancia, las organizaciones están explorando soluciones más inteligentes y avanzadas.
Telemetría vs. Sondeo: Diferencias y beneficios en la monitorización de sistemas moderna
Cuando se trata de la implementación de la telemetría en sistemas de vigilancia, es importante comprender las diferencias entre el enfoque de streaming y el de sondeo. Si bien la telemetría en streaming puede ser más compleja, su diseño ofrece una mayor escalabilidad, lo cual se evidencia en los proveedores de nubes públicas como Amazon, Microsoft y Google. Estos gigantes tecnológicos gestionan millones de hosts y puntos finales que requieren supervisión constante. Como resultado, han desarrollado canales de telemetría y monitorización sin puntos únicos de fallo, lo que les permite obtener el nivel de inteligencia y automatización necesario para operar a gran escala en sus centros de datos. Aprender de estas experiencias puede resultar invaluable al construir soluciones de monitorización propias. En contraste, las soluciones de monitorización basadas en el sondeo pueden enfrentar desafíos de escalabilidad. Aumentar el intervalo de sondeo para un contador de rendimiento específico incrementa la carga en el sistema que está siendo supervisado. Algunos contadores son livianos y pueden ser sondeados con frecuencia, pero otros contadores más pesados generan una sobrecarga significativa. La transmisión de datos constante puede parecer, a primera vista, que implica una mayor sobrecarga en comparación con una solución de sondeo. Sin embargo, gracias a los avances tecnológicos, se han desarrollado soluciones ligeras. En muchos casos, los datos fluyen a través de un motor de consulta de flujo que permite la detección de valores atípicos al tiempo que almacena todos los datos para respaldar el análisis de tendencias y el aprendizaje automático. Esta arquitectura se conoce como arquitectura lambda y se utiliza ampliamente en aplicaciones que van más allá de la monitorización, como en dispositivos y sensores del Internet de las Cosas (IoT). Proporciona alertas en tiempo real para valores fuera de los límites normales, al mismo tiempo que permite un almacenamiento rentable de los datos registrados, lo que facilita un análisis más profundo en un almacén de datos de bajo costo. La capacidad de contar con una amplia cantidad de datos registrados permite realizar análisis exhaustivos de los valores transmitidos.
Monitorización de sistemas: Enfoques inteligentes y aprendizaje automático para alertas precisas
En el ámbito de la monitorización de sistemas, es crucial garantizar la calidad de los datos para obtener alertas precisas y relevantes. La mayoría de las herramientas de monitorización ofrecen la posibilidad de personalizar los rangos de alerta. *Por ejemplo, es posible que desee recibir una alerta cuando el uso de la CPU supere el 80% en ciertos sistemas, mientras que en otros sistemas un nivel alto de uso de CPU puede ser parte de su funcionamiento normal. Sin embargo, encontrar el equilibrio adecuado puede resultar complicado:
- Por un lado, no desea que las alertas abrumen a los administradores con información irrelevante.
- Por otro lado, tampoco quiere establecer umbrales demasiado laxos que oculten problemas críticos en su centro de datos.
Para abordar esta dicotomía, es recomendable utilizar enfoques de monitorización inteligente o dinámica. Estos enfoques capturan una línea de base para cada sistema y solo activan alertas cuando los valores están fuera de los límites normales tanto para el servidor específico como para el marco temporal correspondiente. A medida que se recopila un mayor volumen de datos, muchas herramientas de monitorización están implementando sistemas de aprendizaje automático para realizar un análisis más profundo de los datos.
Este procesamiento avanzado permite generar alertas más inteligentes basadas en la carga de trabajo específica de cada sistema.
El aprendizaje automático se emplea para detectar patrones y anomalías sutiles que podrían pasar desapercibidos para las reglas de alerta tradicionales. Sin embargo, es importante destacar que es fundamental verificar que estas alertas inteligentes funcionen correctamente y proporcionen las alertas esperadas. Es necesario realizar pruebas exhaustivas y validar los resultados para asegurarse de que las alertas se generen de manera precisa y oportuna. *De esta manera, se logrará un sistema de vigilancia más eficiente y confiable.
Continuidad de la monitorización: Estrategias y enfoques clave para detectar problemas en sistemas
A medida que su organización busca implementar una monitorización más inteligente, surge la pregunta crucial: ¿Cómo detectamos problemas o interrupciones en nuestros sistemas de monitorización? A medida que se depende cada vez más de la automatización conectada a estos sistemas, la monitorización se convierte en un desafío aún mayor. Existen varias medidas que se pueden tomar para asegurar la continuidad de la monitorización:
- En primer lugar, es fundamental crear redundancia en la infraestructura, ya sea mediante la implementación de máquinas virtuales o aprovechando servicios de plataforma como servicio (PaaS) en diferentes centros de datos o regiones de la nube.
- Esto garantiza que, en caso de fallos en un punto, se cuente con sistemas alternativos para respaldar la monitorización.
- Otra opción es establecer un mecanismo de alerta personalizado o secundario que verifique el estado del sistema de monitorización principal y actúe como una capa adicional de seguridad.
- También es posible implementar un proceso de alerta, que genera alertas a intervalos regulares, y contar con un mecanismo escalado que emita una alerta adicional si el proceso no se activa como se esperaba.
Además de estos enfoques, es importante asegurarse de que el mecanismo de alerta cubra todas las capas de la aplicación y no se limite a una sola. *Por ejemplo, es necesario realizar pruebas y monitoreo en la capa web, la capa de almacenamiento en caché y la base de datos, para detectar cualquier fallo o anomalía en cualquiera de ellas y recibir alertas pertinentes. Mantener la supervisión en línea requiere un enfoque proactivo y sólido en términos de arquitectura y estrategia. Al implementar estas medidas de seguridad y verificación, se garantiza que cualquier problema o interrupción en los sistemas de monitorización sea rápidamente detectado y atendido, lo que permite una respuesta oportuna para mantener el funcionamiento adecuado de los sistemas críticos.
Conclusiones
Dar el salto hacia una monitorización más moderna es una decisión inteligente y necesaria para garantizar el correcto funcionamiento de los sistemas. Aunque los cambios pueden parecer intimidantes, recuerda que has sobrevivido al Ibook y la mahonesa sin huevo ¡así que esto es pan comido!
La telemetría se presenta como una alternativa prometedora, ofreciendo soluciones más inteligentes y detección de anomalías más precisas.
Además, la implementación de medidas de redundancia, mecanismos de alerta personalizados y pruebas exhaustivas en todas las capas de la aplicación garantizarán una monitorización confiable y oportuna. ¡Así que prepárate para abrazar la monitorización moderna y dejar atrás los métodos anticuados! Recuerda, en el mundo de la monitorización, ser moderno es ser más moderno que la media humana. ¡Y tú ya estás listo para ser el “cool kid” de la monitorización!
¿Conoces el sistema de monitorización Pandora FMS?

por Dimas Pardo | Last updated Aug 10, 2023 | Tutorial
Hola de nuevo, Pandorafílicos. Hoy en nuestro queridísimo blog te queremos presentar un vídeo. Ya sabes que de vez en cuando hacemos eso, ¿no? Rescatar un vídeo de nuestro canal, el más majo y relevante, y desglosarlo un poquito por escrito.
Todo para que tengas el libro y el audiolibro, por así decir.
Pues hoy vamos con… Redoble de tambor:
En este artículo, como en el vídeo, te guiaremos a través del proceso de instalación del entorno de Pandora FMS utilizando el práctico script de instalación online.
Con esta herramienta, podrás configurar rápidamente tu sistema y comenzar a aprovechar todas las capacidades de supervisión y gestión que ofrece Pandora FMS.
Antes de comenzar, asegúrate de cumplir con los siguientes requisitos para garantizar una instalación exitosa:
- En primer lugar, tu máquina debe tener acceso a internet, ya que el script de instalación requiere acceder a diversas URL y repositorios oficiales de la distribución que estés utilizando.
- Asimismo, verifica si tienes instalado el comando ‘curl‘, el cual suele venir por defecto en la mayoría de las distribuciones.
- Es importante contar con los requisitos mínimos de hardware recomendados para un rendimiento óptimo del sistema.
- Cuando estés listo para iniciar la instalación, asegúrate de ejecutar los comandos como usuario root.
- Por último, asegúrate de tener un SO compatible. En este caso, la instalación se puede realizar en CentOS 7, Red Hat Enterprise Linux 8 o Rocky Linux 8. Si estás utilizando una distribución de Red Hat, asegúrate de que esté activada con una licencia y suscrita a los repositorios estándar.
En el caso específico de este vídeo/artículo, hemos creado una máquina con Rocky Linux 8.
Si ya contamos con el resto de requisitos, solo queda comprobar que efectivamente estamos ejecutando los comandos como usuario root y procederemos con la ejecución de la herramienta de instalación online. Este proceso nos instalará la última versión disponible de Pandora.
Instalación
Ahora esperaremos a que termine el proceso de instalación.
Una vez terminada la instalación, podremos acceder a la consola de Pandora a través de nuestro navegador.
En el video, además, se presenta un valioso añadido:
Veremos las variables de entorno que podemos modificar, previo a la instalación de Pandora.
Entre las variables que podemos ajustar se encuentran:
- El huso horario, a través de la variable TZ.
- El host anfitrión de la base de datos, así como el nombre, usuario y contraseña de la base de datos.
- También podemos especificar el puerto de la base de datos y la contraseña del usuario root, que por defecto es “pandora”.
Además, se nos brinda la opción de omitir la comprobación de la existencia de una instalación previa de Pandora, saltar la instalación de una nueva base de datos o evitar la optimización del kernel recomendada.
Estas opciones permiten adaptar la instalación a nuestras necesidades específicas.
Asimismo, hay variables como MYVER o PHPVER, que nos permiten definir qué versión de MySQL y PHP deseamos instalar.
Con MySQL, podemos indicar “80” para MySQL 8 o “57” como opción por defecto para MySQL 5.7. En el caso de PHP, podemos especificar “8” para PHP8 o “7” por defecto para PHP7.
Continuando con la personalización del entorno de Pandora FMS, también tendremos la opción de definir las URL de los paquetes RPM del servidor, consola y agente de Pandora.
Por defecto, estas URL apuntan a la última versión disponible, lo que garantiza que siempre estemos utilizando las últimas mejoras y correcciones de errores.
Es importante tener en cuenta que también existe la posibilidad de indicar si deseamos instalar los paquetes de la última versión beta disponible.
Sin embargo, se recomienda utilizar esta opción solo en entornos de prueba, ya que las versiones beta pueden contener características experimentales y no ser tan estables como las versiones estables.
Si queremos instalar paquetes específicos, esta opción será ignorada automáticamente.
¿Quieres saber más sobre Pandora FMS?

por Dimas Pardo | Last updated Aug 8, 2023 | Comunidad
Trabajar en el campo de la monitorización de software puede parecer aburrido o demasiado técnico, pero déjame decirte que hay más diversión y emoción de lo que uno podría imaginar.
No es que estemos todo el día de barbacoa y celebraciones, pero una vez casi hacemos unas olimpiadas artesanales en la oficina. Rollo The Office.
*Larga vida a Michael Scott.
En fin, acompáñame en este viaje por un día en la vida de un experto en monitorización de software, donde las líneas de código se mezclan con las risas y el café soluble.
Nuestro protagonista, al que cariñosamente llamaremos “Capitán Monitor”, se enfrentará en este pseudodocumental de flora y fauna, a un día lleno de desafíos técnicos y sorpresas inesperadas.
Desde el momento en el que abre uno de sus perezosos ojos cubiertos de legañas hasta que cierra su portátil última generación, su vida es una montaña rusa de emociones y situaciones hilarantes.
Primera hora
Comencemos con la hora punta matutina, exactamente cuándo el Capitán Monitor se enfrenta a la temida avalancha de alertas en su bandeja de entrada.
Mientras intenta clasificar y priorizar las alertas, se encuentra con una que dice:
“¡El servidor principal se ha convertido en una orquesta de mariachis que acaban de salir, pedo, del Salón Tenampa a Plaza Garibaldi!”.
Sí, lo has leído bien.
Resulta que un “compañero” bromista decidió jugarle una pequeña broma y cambiar los tonos de alerta por rancheras de Lucha Reyes.
Pero las sorpresas no terminan ahí.
Media mañana
Durante una reunión de equipo, Capitán Monitor descubre que su encantador compañero de cubículo ha convertido su escritorio en una jungla de cables, clavijas, módems y demás dispositivos electrónicos…
Entre tanto monitor gigante y las pilas de discos duros, el Capitán parece hallarse perdido en una especie de versión moderna del Jumanji de Alan Parrish.
No importa cuánto insista en que la monitorización de software moderna en realidad no requiere de un entorno de trabajo de tan alto emperifollamiento tecnológico, su compañero sigue y sigue sacando trebejos con enchufe para paramentar su particular mundo de fantasía digital.
Primera hora de la tarde
En medio de las pruebas y los ajustes del sistema, Capitán Monitor también se enfrenta a los desafíos de lidiar con el “usuario olvidadizo”.
Sí, ese usuario que llama a todas horas con problemas que podrían solucionarse con un simple reinicio.
Pero nuestro héroe no se rinde fácilmente y se convierte en el maestro de las instrucciones básicas de reinicio.
A veces incluso sueña, mientras dormita en el baño a la hora de la siesta, con una vida en la que no tenga que decir
“¿Ya intentó reiniciar su dispositivo?”.
Tarde profunda
Pero no todo es caos y microúlceras en el mundo de la monitorización de software. Capitán Monitor, que como habéis podido adivinar curra en el Departamento de Soporte, también tiene su momento de gloria cuando logra detectar y solucionar un problema crítico de escala global antes de que cause un colapso en el sistema de la compañía de encargos florales que monitoriza.
En ese momento de triunfo se siente como si estuviera en el escenario principal de un concierto de rock, con la multitud vitoreando y los fuegos artificiales estallando en lo alto.
“Sí, esta es la vida que he elegido y me gusta”, exclama para sí.
Justo antes de acabar la jornada
Al final del día, cuando no todo peligro ha pasado pero se empieza a obviar por agotamiento, Capitán Monitor se relaja y comparte algunas anécdotas graciosas con sus colegas en la sala de descanso.
Todos se parten la caja y comparten historias similares de locuras técnicas y situaciones tensas con los clientes.
Es, más que nunca, en esos momentos compartidos cuando Capitán Monitor se da cuenta de que, a pesar de los desafíos y de las tres mil perrerías que sufre a diario, hay una camaradería especial entre los expertos en monitorización de software.
Son una comunidad unida, aventurera, cool.
Here we go again
Y así, a la mañana siguiente, estamos seguros de que el Capitán Monitor se levantará con energía renovada, listo una vez más para enfrentar otro día lleno de desafíos en el emocionante mundo de la monitorización de software.
Porque, aunque pueda haber momentos de frustración y estrés, no hay nada como la satisfacción de descubrir y resolver problemas para quedar bien con el jefe.

por Dimas Pardo | Last updated Feb 23, 2024 | Tecnología
¡Agárrense los cinturones, desarrolladores intrépidos! En esta era de tendencias tecnológicas y estrategias digital-first, las organizaciones están saltando a bordo del tren de los microservicios con contenedores Docker.
¿Qué es Docker?
Bueno, es como una caja mágica que envuelve tu aplicación con todo lo que necesita para funcionar, como un sistema de archivos, herramientas y hasta un mapa de ruta para llegar a múltiples plataformas.
¡Es como si tu software tuviera su propia mochila lista para viajar!
Los microservicios: el nuevo equipo de superhéroes de la programación
Hoy en día, los desarrolladores están usando Docker para construir microservicios, que son como los Avengers del mundo del software.
Estos microservicios son pequeñas piezas de código que trabajan juntas para realizar tareas específicas. Por ejemplo, imagínate una cadena de pizzerías que utiliza microservicios para tomar pedidos, procesar pagos y coordinar las entregas en todo el país.
¡Es como tener una liga de superhéroes pizza-ficientes trabajando en conjunto!
El papel estelar de Docker Engine y su pandilla
Cuando hablamos de Docker, no podemos dejar de mencionar a Docker Engine, el líder de esta pandilla de contenedores. Docker Engine es el responsable de construir y ejecutar los contenedores.
Pero antes de poder hacer eso, necesitamos un Archivo Docker. Piénsalo como el guión de una película que define todo lo necesario para que la imagen del contenedor cobre vida.
Una vez que tenemos el Archivo Docker, podemos construir la imagen del contenedor, que es como el actor principal que se ejecuta en el motor Docker.
Docker Compose y Docker Swarm: los compañeros de aventuras de Docker
Pero la diversión no termina ahí. Docker ofrece más compañeros de aventuras, como Docker Compose y Docker Swarm.
Docker Compose permite definir y ejecutar aplicaciones en contenedores, como el director de cine que coordina todas las escenas. Y luego tenemos a Docker Swarm, que convierte un grupo de servidores Docker en uno solo, como si fusionaran a los Power Rangers para formar un megazord.
¡Es el sueño de todo director tener un equipo unido y listo para la acción!
El festín de Docker Hub y la fiesta de la Open Container Initiative (OCI)
Pero espera, no vamos a cesar en nuestras analogías, ¡hay más! Docker Hub es como el buffet de comida para desarrolladores, lleno de microservicios en contenedores listos para ser devorados.
¿Necesitas un servidor web? ¿Una base de datos? ¡Aquí encontrarás de todo!
Es como una fiesta en la que todos los servicios principales están invitados.
Además, Docker ha creado la Open Container Initiative para asegurarse de que el formato de empaquetado sea universal y abierto. Es como garantizar que todos los invitados sigan las reglas de etiqueta.
AWS ECS: ¡El servicio de gestión de contenedores de Amazon al rescate!
Si estás jugando en el mundo de Amazon Web Services, tienes a tu disposición Amazon EC2 Container Service (ECS), el cual es un servicio de gestión de contenedores altamente escalable y seguro.
Con ECS, puedes desplegar y administrar fácilmente tus microservicios en contenedores Docker en la nube de Amazon. Imagina tener un equipo de asistentes que se encarguen de toda la infraestructura y logística, mientras tú te enfocas en desarrollar y desplegar tus aplicaciones en contenedores.
¡Atrévete a construir tu propia arquitectura de microservicios con Docker!
Ahora que conoces los conceptos básicos de Docker, los microservicios y las herramientas asociadas, es hora de aventurarte a construir tu propia arquitectura de microservicios con Docker.
Recuerda que los microservicios te permiten dividir tu aplicación en componentes independientes, lo que facilita la escalabilidad y el mantenimiento.
Con Docker, puedes empaquetar y desplegar cada microservicio en un contenedor, aprovechando al máximo la flexibilidad y portabilidad que ofrece esta tecnología.
¡Prepárate para una nueva forma de desarrollar aplicaciones!
Docker y los microservicios están revolucionando la forma en que desarrollamos y desplegamos aplicaciones. Con su enfoque modular, escalabilidad y portabilidad, esta combinación se ha convertido en una opción popular para muchas organizaciones.
Ya sea que estés construyendo una aplicación empresarial compleja o una aplicación web sencilla, considera adoptar una arquitectura de microservicios con Docker para aprovechar los beneficios que ofrece.
¡Es hora de dar el salto y descubrir el apasionante mundo de las aplicaciones en contenedores!
Una vez que hayas construido tu arquitectura de microservicios con Docker, se abrirán nuevas posibilidades para tu desarrollo de aplicaciones.
He aquí algunas ideas adicionales para que las tengas en cuenta:
- Orquestación de contenedores: Además de Docker, existen herramientas como Kubernetes y Docker Swarm que te permiten orquestar y gestionar eficientemente tus contenedores en producción. Estas herramientas te ayudarán a escalar tus servicios, distribuir la carga de trabajo y asegurarte de que tus aplicaciones estén siempre disponibles.
- Implementación continua (CI) y entrega continua (CD): Con Docker, puedes integrar fácilmente tus microservicios en un flujo de trabajo de CI/CD. Esto significa que puedes automatizar el proceso de construcción, prueba y despliegue de tus contenedores, lo que agiliza el ciclo de vida de desarrollo y te permite lanzar nuevas características más rápidamente.
- Monitorización y registro: A medida que tus aplicaciones crecen en complejidad y escala, es fundamental contar con herramientas de monitorización y registro para mantener un buen rendimiento y solucionar problemas. Herramientas como Prometheus, Grafana y ELK Stack son muy populares en el ecosistema de Docker y te ayudarán a supervisar y analizar el rendimiento de tus contenedores y microservicios.
- Seguridad: Al utilizar contenedores Docker, es importante tener en cuenta las mejores prácticas de seguridad. Asegúrate de aplicar parches y actualizaciones regularmente, utiliza imágenes confiables y seguras, y considera el uso de herramientas de escaneo de vulnerabilidades para identificar posibles problemas en tus imágenes de contenedor.
Conclusiones
Docker y los microservicios son tecnologías en constante evolución, y siempre hay más por descubrir. Sigue aprendiendo sobre nuevas herramientas y enfoques, participa en comunidades y conferencias, y mantente al tanto de las últimas tendencias.
¡El mundo de los contenedores y los microservicios está lleno de oportunidades emocionantes y desafiantes!
¿Quieres saber más sobre Pandora FMS?