






Una pequeña guía de buenas prácticas de monitoreo
Las buenas prácticas en el monitoreo empiezan mucho antes de elegir o implantar una herramienta. No se trata de reglas fijas, sino de una forma de trabajo y de entender cómo usar un software de monitoreo. Todo esto se aplica a cualquier software, sea este Tivoli, OpenView, Spectrum, Zabbix, Nagios, Pandora FMS o ZenOSS.
Algunas herramientas de monitoreo serán más flexibles y permitirán que el proceso sea más fácil de implementar y otras nos forzarán a hacer las cosas a su manera, impidiendo que se adapten a nuestra filosofía. A través de nuestra experiencia de muchos años, en diferentes tipos de empresas que trabajan con diferentes aplicaciones, hemos creado nuestra pequeña guía de buenas prácticas de monitorización, un planteamiento que esperamos os ayude en vuestro trabajo del día a día.



Fase 1. Identificando los problemas cuando estos suceden
Identificar tus activos
Esto incluye todo aquello susceptible de ser monitorizado. Deberás establecer una jerarquía, ya que existen relaciones entre los diferentes elementos. Por ejemplo, la relación entre elementos clave, como las bases de datos y los sistemas que los alimentan. Un fallo en la BBDD afectará a todo. Esto debes tenerlo en cuenta.
Identifica qué debe ser monitorizado y qué no. ¿Cómo hacerlo? Por criticidad. Añade en esa lista una columna nueva, que sea criticidad. Esto te ayudará a empezar, pues puede que te salgan varios cientos de elementos a ser monitorizados. Deberías empezar por lo que es verdaderamente crítico.
Si tienes una política de seguridad, puedes “canibalizar” esa lista ya que en ella encontrarás cosas tan importantes como las bases de datos de negocio, los backups y los sistemas críticos de infraestructura. Todos esos elementos son los primeros que deberías monitorizar.
Clasificar tus activos
Una vez que tienes la lista y un campo de importancia para cada elemento, céntrate en los elementos críticos y en aquellos que están relacionados. Por ejemplo, una base de datos crítica dependerá del sistema base, que a su vez tendrá memoria, disco y CPU. Todos esos elementos son críticos por “relación directa” con el elemento.
Puedes crear una jerarquía de elementos que te ayudará a entender cómo se relacionan estos. Por ejemplo:
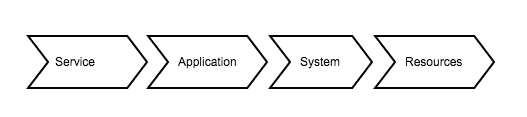
Traducido en algo puramente técnico podría escribirse como:
● Verificación de servicio accesible (Puerto TCP o transacción WEB).
● Proceso de aplicación, que esté activo, recursos RAM / CPU.
● Consumo CPU del SO base, RAM libre en el SO base, Disco libre en el SO base.
● Estado general de la máquina: Load Average, Tráfico de Red.
● Conectividad básica de la máquina (ping).
Esto se debería agrupar en un único elemento de forma que, de “un vistazo”, se pueda ver fácilmente. Hay muchas formas de agruparlos, por servicio, por tecnología o por origen (nodo/agente); todo dependerá de si el servicio es más o menos complejo y forma parte de un cluster. En cualquier caso, cada aplicación dispone de diferentes formas de hacerlo. En Pandora FMS se puede hacer utilizando servicios, grupos o tags.
Definir qué hacer cuando hay problemas
Este punto suele pasar desapercibido y es esencial en nuestras buenas prácticas de monitoreo. ¿De qué sirve si detectamos los problemas, incluso antes de que ocurran, si no lo notificamos eficazmente? La monitorización de un entorno complejo puede ser muy extensa. Incluso a través del sistema de gestión por excepción (gestión por eventos), corremos el riesgo de no identificar los problemas urgentes de forma rápida y eficaz.
Ya tenemos una lista de servicios críticos y los elementos que incluyen; el siguiente paso en nuestras buenas prácticas de monitoreo es el de identificar un responsable que pueda actuar rápidamente cuando un problema lo afecte. Aquí podemos elegir el método de notificación (email, SMS, mensaje emergente vía app) y el grado de escalado, en función de a qué elemento afecte dentro del servicio, o la recurrencia de la alerta. En resumen, notificaremos cuando la CPU del sistema base del servicio se pone muy alta a un operador, y por SMS al responsable del servicio cuando este no responda.
Categorizar las alertas
Es muy importante definir, en todas las alertas, qué queremos destapar y la categoría de la misma, con el fin de evitar alarmar por cosas innecesarias y que nuestros soportes sepan con qué criticidad atender cada tipo de alertas. A priori podríamos clasificar nuestras alertas en los siguientes grupos: Crítico, Warning y Mensaje.
Hasta aquí, hemos pasado por tres puntos: Enumerar activos, clasificar servicios y criticidades y definir responsables y métodos de comunicación. Todo esto a través de una hoja de cálculo por lo que, hasta el momento, todas estas buenas prácticas de monitoreo son útiles para cualquier herramienta de monitoreo. Dedicar tiempo a hacer esto antes de empezar a implementar la monitorización nos asegurará lo siguiente:
- Nos evitará pasar por alto la monitorización de elementos relevantes de nuestros sistemas. Es decir, cuando haya problemas podremos estar seguros de que no puede ocurrir nada realmente grave sin que seamos conscientes de ello. Esto es una de las cosas más importantes, ya que nos permitirá “fiarnos” de nuestra propia monitorización. No hay nada peor que algo malo ocurra y nos demos cuenta de que ha sido culpa nuestra por no monitorizarlo.
- Cuando algo malo ocurra, tendremos datos relativos al problema, fáciles de acceder e interpretar porque se decidió tomar información del servicio en conjunto y no de forma aislada. Esto ayudará a determinar la causa del problema (root cause analysis) de una forma natural, definida por nosotros mismos, sin depender de la supuesta magia que ofrecen algunos fabricantes.
- Cuando suceda un problema, las partes implicadas ya estarán implicadas e informadas. No perderemos tiempo informando del problema, sino que trabajaremos directamente en la solución.
- Ofrecer únicamente la información necesaria. Esto es especialmente importante, ya que si tenemos toda la pantalla en rojo, mezclando alertas irrelevantes con alertas críticas, nos costará mucho determinar el origen del problema y nuestra respuesta no será ni rápida ni eficiente. El exceso de información puede ser incluso más dañino que la falta de la misma.
Una vez definido el método de trabajo se puede aplicar esta metodología descomponiendo el problema general (la monitorización de toda la organización) por partes, como haría cualquier ingeniero competente: podemos hacerlo por servicios, por criticidades, por tecnologías, por departamentos, por ubicaciones geográficas, etc.
Fase 2. Identificando los problemas antes de que sucedan
Una vez que tenemos lo básico, que es identificar sin género de duda cuándo sucede algo malo, podemos afrontar, en una segunda fase, algo mucho más difícil, que es determinar cuándo se acerca un problema. Esta funcionalidad, junto a la de detectar la causa de los problemas de forma automática y la de configurar las herramientas de monitoreo de forma automática (umbrales inteligentes, monitorización dinámica, correlación de eventos, big data monitoring, etc), son las funcionalidades más perseguidas por cualquier software de monitoreo.
En nuestras buenas prácticas de monitoreo debemos tener mucho cuidado con los falsos positivos y los falsos negativos, los cuales empiezan a surgir cuando dejamos que el sistema interprete los datos. Estos resultados pueden provocarnos que malinterpretemos una situación compleja y tomemos malas decisiones. Todos los operadores, con el tiempo, desarrollan un instinto basado en su conocimiento de lo que es normal y lo que no lo es, es decir, no pueden decir que algo esté mal, pero pueden tener la intuición de que algo no está bien.
Con esto, sí queremos insistir en que aún nadie ha conseguido la automatización completa, y siempre recomendamos a nuestros usuarios y clientes que utilicen mucho la cabeza y no busquen la automatización extrema, la cual puede llevar a diferentes errores que solo saldrán cuando tengamos un gran problema en nuestras instalaciones y ya quizás sea demasiado tarde.
Monitorización por intuición es un término que todavía no he oído, ni siquiera en boca de los analistas de Gartner, pero todo llegará.
¿En qué consiste la monitorización por intuición?
Hay dos formas de hacerlo, la pseudo automatizada o la puramente visual. En la primera, definiremos pequeñas alertas que nos avisen cuando algo se sale de los umbrales operativos “normales”. No significa que entren en umbrales “dañinos” o de error, simplemente que entran en umbrales diferentes a lo normal. Para eso deberemos crear una categoría de alertas, como comentábamos en la primera fase, que deje bien claro que no son problemas, sino cosas sospechosas, eliminando el concepto de “criticidad” en ellas, para que, en caso de tener muchos eventos de todo tipo, estos sean fáciles de ocultar si es preciso.
La otra manera es crear cuadros de mando, pantallas o dashboards (cada herramienta tiene su propia forma de venderlo), que deben servir para poner en una pantalla muy grande un montón de gráficas en tiempo real. Un operador que mire siempre las mismas pantallas, en el mismo orden, con el tiempo adquiere la habilidad innata de decir “algo no va bien”.
Herramientas imprescindibles
No voy a hablar de aplicaciones, si no de funcionalidades que son imprescindibles a la hora de implementar cualquier monitorización útil para una organización que se tome en serio la operación.
Los elementos imprescindibles en cualquier software que se precie son los siguientes:
● Alertas. Deben de permitir un escalado, una agrupación de elementos (correlación) y la definición de acciones complejas (más allá de enviar un email o un SMS). Hoy día, en que muchas organizaciones trabajan con herramientas colaborativas (como Slack o Whatsapp), la capacidad de insertar un evento en un grupo, incluyendo una gráfica y una descripción del problema junto con un enlace directo a la monitorización, permite una respuesta mucho más rápida que un simple SMS.
● Gráficas. Deberían ser una herramienta, no algo estático; es decir, deben ser filtrables, estrujables, se deben poder combinar dinámicamente con otras series de datos, poder ver la evolución detallada a lo largo de grandes períodos de tiempo, que se puedan comparar con valores en intervalos similares de otros meses, etc. Las gráficas son la principal fuente de análisis numérico de que disponemos. Una gráfica aporta muchísima información de forma muy fácil. Un sistema con gráficas estáticas puede ser bonito, pero no útil.
● Logs. El siguiente paso ante un problema o la sospecha de un problema es analizar la información en bruto. Esto puede ser simplemente tablas de datos o datos en crudo del sistema (entradas de log). En caso de ausencia de estos datos, estamos limitados a gráficas y eventos.
● Acceso directo a la fuente. Esto ya se excede de lo que sistema de monitorización hace por lo general. Pero si tenemos información precisa (alertas), series de datos que nos ayudan a entender el comportamiento (gráficas) y datos concretos que ayudan a concretar nuestro análisis (logs) el siguiente paso lógico es acceder directamente al sistema que genera toda esa información. Que una herramienta de monitorización nos permita acceder fácilmente a ese sistema es el cierre del círculo.
Esperamos que con este artículo de buenas prácticas de monitoreo os hayáis hecho una mejor idea de cómo llevar a cabo una buena monitorización.
Para finalizar, recuerda que Pandora FMS es un software de monitorización flexible, capaz de monitorizar dispositivos, infraestructuras, aplicaciones, servicios y procesos de negocio.
¿Quieres conocer mejor qué es lo que Pandora FMS puede ofrecerte? Descúbrelo entrando aquí: https://pandorafms.com/es
O si tienes que monitorizar más de 100 dispositivos también puedes disfrutar de una DEMO GRATUITA de 30 días de Pandora FMS Enterprise. Consíguela aquí.
Además, recuerda que si tus necesidades de monitorización son más limitadas tienes a tu disposición la versión OpenSource de Pandora FMS. Encuentra más información aquí: https://pandorafms.org/es/
No dudes en enviar tus consultas. ¡El equipo de Pandora FMS estará encantado de atenderte!
El equipo de redacción de Pandora FMS está formado por un conjunto de escritores y profesionales de las TI con una cosa en común: su pasión por la monitorización de sistemas informáticos. Pandora FMS’s editorial team is made up of a group of writers and IT professionals with one thing in common: their passion for computer system monitoring.









