







Course 101: Instrumentation, Software Metrics, Monitoring, Alerts
Course 101 -1: Introduction
Since the 1920s, higher education institutions have been using this term to describe the nomenclature of the early years of study. Here we announced some time ago our intentions to focus on tutorials, but we believe that as knowledge is important, we have brought you different kinds of articles because we consider that wisdom is a valuable asset (we include a source for some online encyclopaedias).

A formal introduction to Pandora FMS involves many terms and concepts that we may not know; we may have forgotten them or we should revisit them. We offer OPT certification for those who want a professionalization or specialization in the area. In this blog of ours we are flexible and we also offer a pragmatic approach: today we would like to show you, from the components perspective, the Course 101 on monitoring with plenty of web links to help you expand -or clarify- any of the concepts ” Let’s do this!
Course 101 -2: Instrumentation
In English this term is common although it has become obsolete over time. It comes from the first industrial revolution where there was no telematics, obviously. Thus, one or several people would go to each machine to read the instruments that indicated pressure, temperature, speed, etc. and would take them to the engineers or people in charge of the production processes. An incorrect reading could cause a boiler to explode with water vapor, resulting in the extinction of even human lives. Monitoring was then, as now, still a very serious issue.
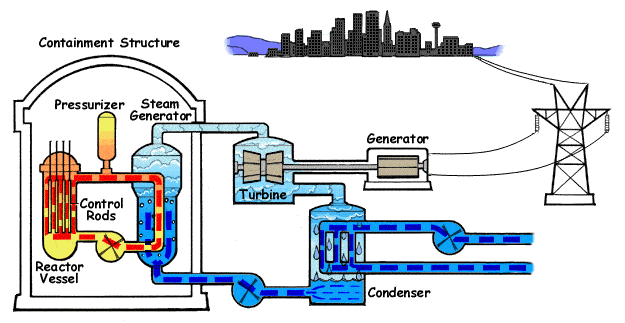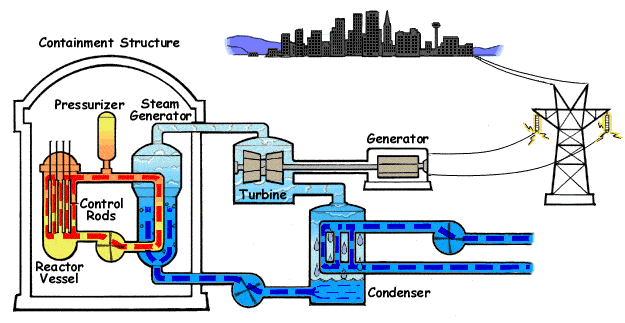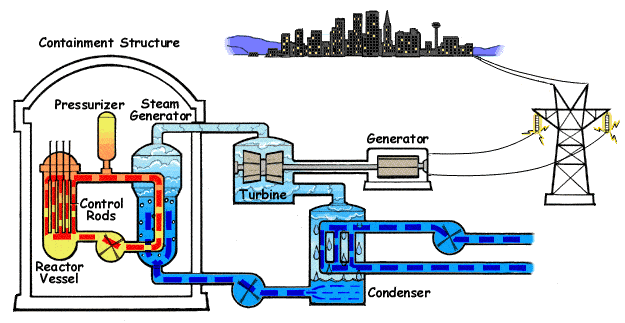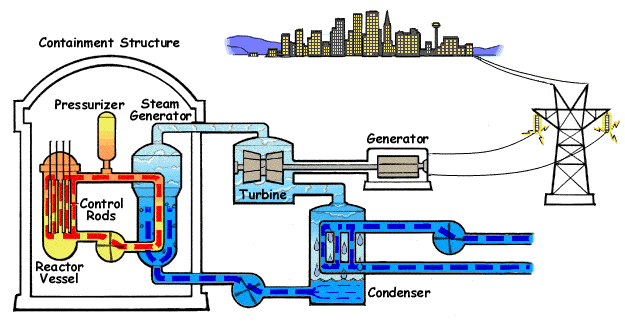
We wanted to show you this concept to illustrate how the passing of time leads to changes in names and denominations, which clearly reflect the innovations of technology. In this Course 101 we will describe Monitoring as a whole, i.e. a Monitoring System, although strictly speaking “Monitoring” is only one of the components. To differentiate this component we will write it as Monitoring. Thus, Software Metrics (modern version of Instrumentation), Monitoring and Alerts are concepts that form an interrelationship and are the basis of a Monitoring System.
Course 101 -3: Software Metrics
As in the Instrumentation era we took the values with the Software Metrics we will do the same but part of the work will be done in advance. Why do we state this? As it turns out, modern operating systems already offer by default the basic values such as disk capacity, RAM memory, etc. and we will find data even from the moment the operating system is installed. This data has a time stamp, of great importance to be able to synchronize events later. We will call this collective set of data supplied by the operating system itself low-level metrics .
Of course, a computer that does not run any applications is of very little use. We use the term application for any software that needs to be installed additionally or expressly during the installation of the OS, the latter being very common in the GNU/Linux environment. These applications have their own way of working and the possibilities of event logs that may occur (and also where they are located on the hard disk) are endless. That’s why Pandora FMS has the modality of complements or plugins that allow us to accommodate any software that arises, hence our flexibility. We will call this set of Application Metrics high level.
We must keep the collection of both Metrics separate, it means more burden for an application to keep track (and we collect it for that application) of the Low Level Metrics, we are interested in the High Level Metrics that are unique to that application, we can get the rest directly from the operating system.
Course 101 3.1: Absolute and relative metrics
Metrics can be classified this way because there are values that have a limit (storage capacity, for example) and we are interested in seeing the percentage of use, that is, the amount of bytes stored is relative to the storage capacity. On the other hand, we would also be interested to know the amount of free space for storage, for example to know if we can install any new application, and that value is absolute, regardless of the storage capacity of the device. The same reasoning can be applied to a network card and its data flow or other device components.
We will go further by saying that these limits that set the Relative Metrics are not set in stone either, although it is true that in order to expand its RAM we must add a physical component to a physical server, nowadays virtual machines have been more effective and practical to manage and if we are short of memory we can contract -or assign- more memory (of course with the limit imposed by the amount of memory of the real machine that it contains to the virtual machine).
Course 101 -4: Monitoring
So far what we have done is to collect and store data like a squirrel getting food for the winter. Collecting data has its own methodology, indexing to quickly locate them by time and origin. The key point of monitoring is to relate and add these data at different points of time and origin but with similar characteristics. I mean, we compared pears to pears and apples to apples: what was the server workload yesterday? and what about a week ago? from a server cluster that had the most workload last Saturday? Here, again, the combinations are endless, we don’t know what the customer can ask for, but dynamic monitoring will give us an excellent starting point.
We can say that by making such comparisons, after conscientious and organized data collection and storage, we will be able to obtain information that is important to the company in order to foresee future expansion plans – and why not? Reduction plans if it is not profitable. So that’ s the difference between data and information and we will see another important point: how that information is displayed.
In Pandora FMS we take care until the smallest detail proposed by the users in order to show the information in the best way possible for its comprehension. If you check the version history of Pandora FMS you will always find that some improvement was made in the metaconsole or in the graphics, since there are many ways and means to show that precious information.
No matter how well presented the information may be (third dimension, augmented reality, etc.) we will always have another inconvenience for us humans: firstly, we are unable to be 24 hours aware of what is happening with the systems and secondly, we like repetitive tasks but to a certain extent (we have a daily routine, but Sundays are different, right?) which leads us to the following point: the Alerts.
Course 101 -5: Alerts
Alerts are a planned mechanism: according to the values observed during a certain time (at least one week) we can establish that when some values are reached for more than a predetermined time, a message will be sent to the person in charge of the area. Alerts can be direct, for example by email, or delegated to a third party, for example Twitter, Slack, Telegram or Whatsapp.
Before we start to send a lot of messages to network administrators, we must take into account that we must classify the alerts to respond according to the magnitude of the abnormality. A failure in a server hard disk with built-in RAID 0+1 must generate a reminder alert: when the employee who works in the physical facilities shows up to work, he or she will proceed to replace it with a new one. We see that this is a strictly necessary alert to attend to, but its urgency is not so great. That’s why we can classify alerts into:
- Notices (minor).
- Warnings.
- Critical (greater importance).
Some monitoring systems have integrated monitoring, control and resolution of incidents and Pandora FMS provides the option to add comments for future references and reminders. Also the management of multiple alarms that depend on one main alarm is considered: if a server is turned off obviously its disk space, memory and other alarms will show a warning sign that does not need to be displayed. Another special case is when a system suffers three or more Warning type alerts in a period of say 6 hours: although the system is successfully recovered and that these warnings can wait until the next day for correction, their sum and coincidence in time justifies immediate human attention to decide what is happening based on the panorama in the console.
Course 101 -5.1: Responsive alerts
In the case of Warning type Alerts, they may perform a specific automated task in order to get out of the abnormal situation. Let’s explain with real facts: we know a web server and we know that its maximum capacity is to serve a thousand clients with a logged in session. When you reach this limit and maintain this value for a period of time, let’s say 15 minutes, a Warning type alarm will be triggered: the server is working but its performance is known to be degraded. We could program the monitoring system to order the execution of another machine (virtual or real) to start serving new customers.
Although the last example may seem like a trivial matter, we will notice it in our pockets: if we have a virtual machine contracted and it is enough to attend to our customers, we save money by keeping the minimum amount contracted, the least expense. But if we increase our number of clients, a good monitoring system can “contract” more virtual machines, serve more clients and increase our revenue (of course, both virtual machines are configured to share the workload). Our graduates will also increase, but the profit margin will pay off. Something important is that this alert will always reach us but will be degraded to a Notice type to notify you that this month we will implicitly pay more for the use of virtual computers.
Course 101 -6: How many Metrics should we collect?
We must maintain good monitoring practices, avoiding false alerts as much as possible and this leads to focusing on the metrics that really matter. In an ideal world we could collect everything and then filter it, but it is much better to select the data. This is because monitoring already places a burden on the target system, so we must keep interference to a minimum. If we want to monitor our NGINX web server it does not exceed a dozen parameters and if we cache the server to improve its performance the monitoring of the same cache will not be a major problem either. In the case of monitoring a document-oriented database such as MongoDB, which handles huge amounts of data, the number of parameters will be two to three dozens.

The complexity of the application is directly related to the amount of Metrics it generates and the great complexity reduces the efficiency plus Pandora FMS breaks with the established in the monitoring, generating a necessary balance.
Completing Monitoring 101
We have covered the basics of monitoring and as good teachers we leave you the task of doing some research on the following ones from the letter D to the letter Z and in order to do this you have many links to help you move forward, also use the search function in the drop-down menu to find out about many other good articles that the Pandora FMS community keeps online always at your disposal.
Comment below and we will answer your questions or if you want just leave a greeting, like a guestbook!

Programmer since 1993 at KS7000.net.ve (since 2014 free software solutions for commercial pharmacies in Venezuela). He writes regularly for Pandora FMS and offers advice on the forum . He is also an enthusiastic contributor to Wikipedia and Wikidata. He crushes iron in gyms and when he can, he also exercises cycling. Science fiction fan. Programmer since 1993 in KS7000.net.ve (since 2014 free software solutions for commercial pharmacies in Venezuela). He writes regularly for Pandora FMS and offers advice in the forum. Also an enthusiastic contributor to Wikipedia and Wikidata. He crusher of irons in gyms and when he can he exercises in cycling as well. Science fiction fan.








