







High Availability Database Cluster with Pandora FMS
Introduction
Pandora FMS relies on a MySQL database for configuration and data storage. A database failure can temporarily bring your monitoring solution to a halt. The Pandora FMS high availability database cluster allows you to easily deploy a fault-tolerant, robust architecture.
Cluster resources are managed by Pacemaker, an advanced, scalable High Availability database cluster resource manager. Corosync provides a closed process group communication model for creating replicated state machines. Percona, a backwards-compatible replacement for MySQL, was chosen as the default RDBMS for its scalability, availability, security and backup features.
Active/passive replication takes place from a single master node (writable) to any number of slaves (read only). A virtual IP address always points to the current master. If the master node fails, one of the slaves is promoted to master and the virtual IP address is updated accordingly.
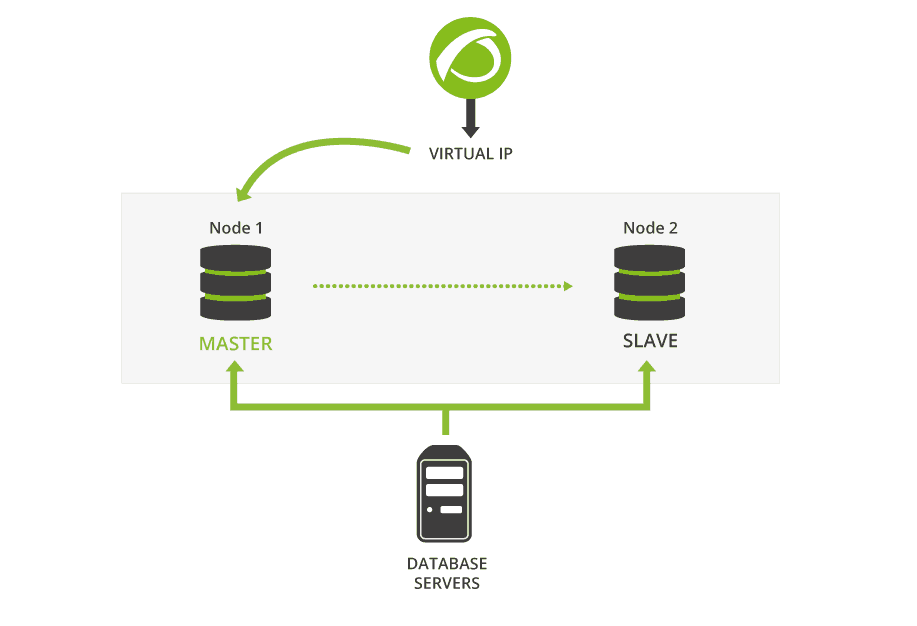
The Pandora FMS Database HA Tool, pandora_ha, monitors the cluster and makes sure the Pandora FMS Server is always running, restarting it when needed. pandora_ha itself is monitored by systemd.
Prerequisites and installation
Throughout this article, we will configure and test a two node cluster with Pandora FMS. You will need an already installed Pandora FMS Enterprise version and two additional hosts running CentOS version 7.
To configure the cluster follow the official Pandora FMS High Availability Database Cluster installation guide. Although it is a straightforward, step-by-step guide, some experience with the Linux command line is recommended.
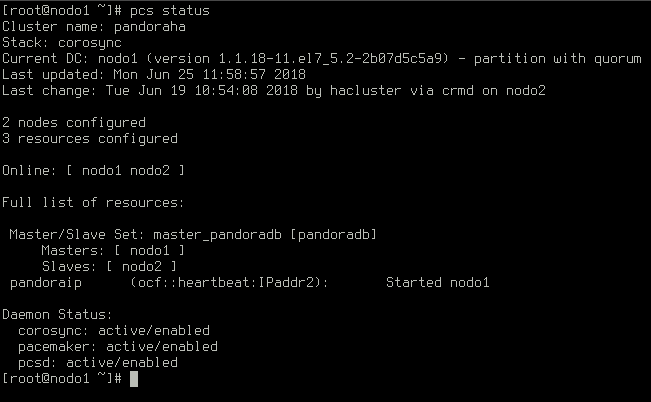
Once finished, ssh to any of the two nodes and run pcs status to check the status of the cluster. Both nodes should be online:
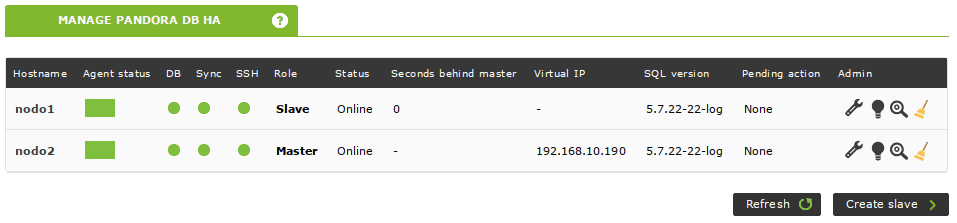
The cluster is up and running. You can check its status from your Pandora FMS Console too. Simply navigate to Servers -> Manage database HA (tip: clicking on the loupe icon displays the output of pcs status without having to ssh to that node):
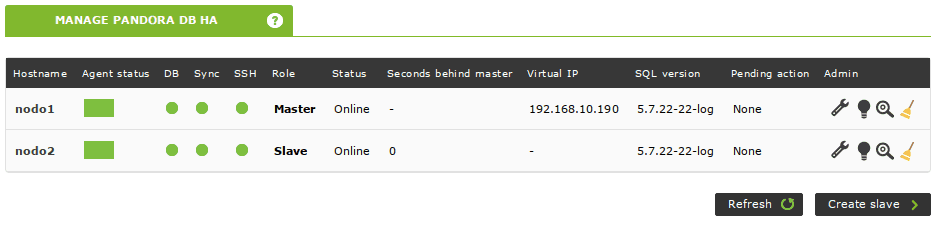
The Pandora FMS High Availability Database Tool automatically creates agents to monitor your cluster. They can be accessed from the previous view by clicking on the node’s name displayed in the Hostname column:
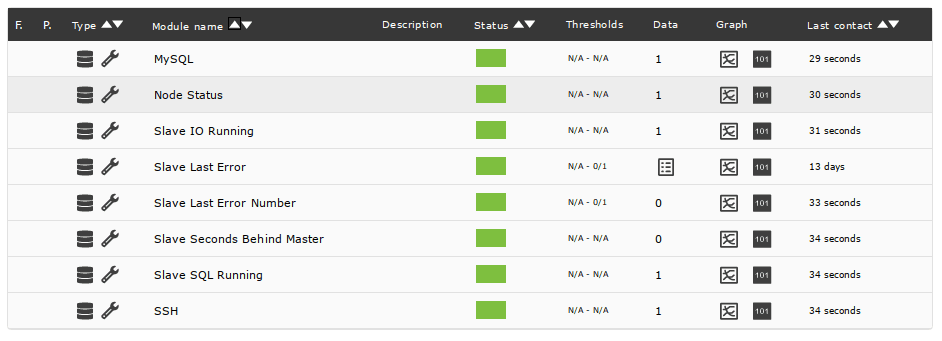
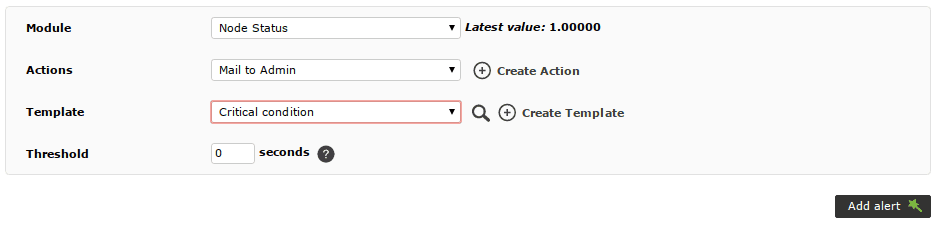
You should configure alerts for, at least, the Node Status, Slave IO Running and Slave SQL Running modules. These modules go critical when there’s a problem, so you can use Pandora’s default Critical condition alert template:
Operating the cluster
Let’s see what happens when things go wrong. In this section we will test the behaviour of our high availability database cluster in different situations.
Manual failover
We may need to stop one of the nodes for maintenance, for example. Stopping a slave is a trivial case. Let’s stop the master instead:
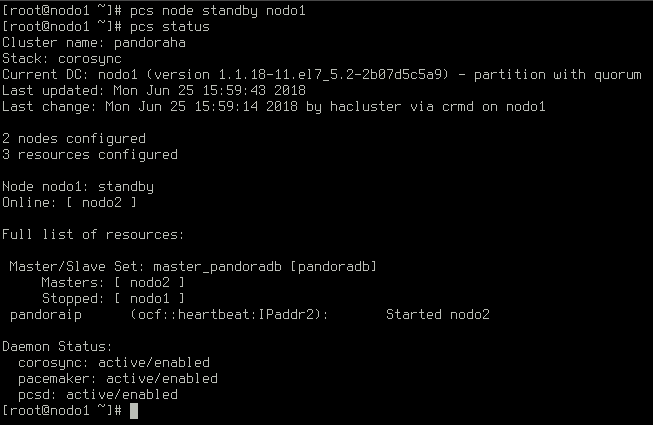
The former master is on standby and the slave has been promoted to master:
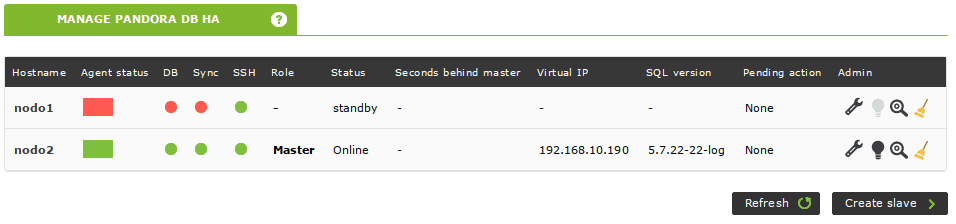
Let’s get it back online:
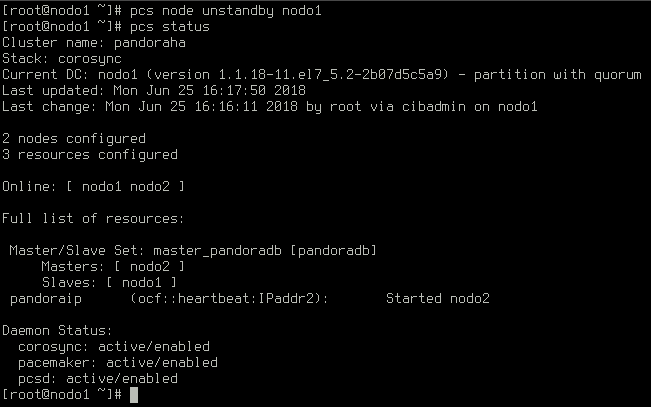
The former master is online, and it is a slave now. The new master will not relinquish its role unless it fails.
Our Pandora FMS server is running, as expected:

Crash of the master
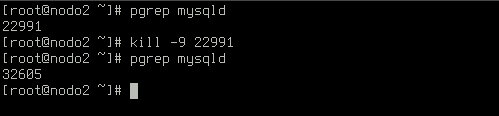
If the process of the database server crashes, it will be automatically restarted:
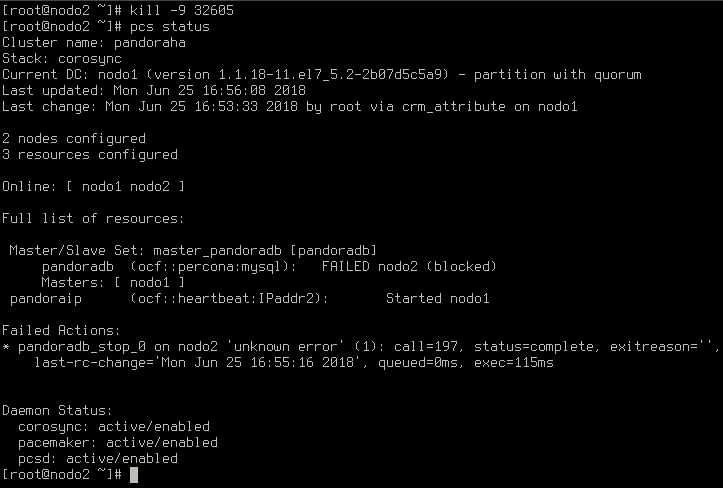
However, if there is more than one crash in a one hour span, the node will be blocked and a slave will be promoted to master:
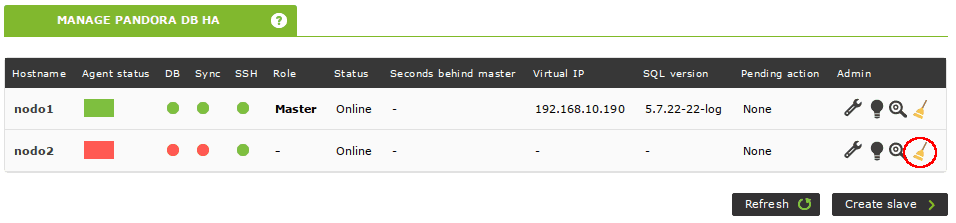
Once the problem is fixed, click on the broom icon to recover the blocked node.
Halting or rebooting one node
Halting or rebooting any node will leave the cluster with a master and the operation will not be affected:

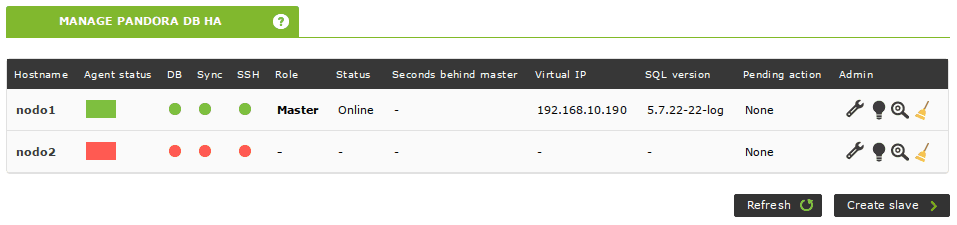
If seconds behind master is greater than 0 when you bring the node back online, it means the slave has not yet replicated all the transactions that have taken place in the master. This value should start decreasing on its own until it reaches 0:
Broken replication
When the master is not in synchrony with the slave (i.e., the master is ahead of the slave) and it fails, it may not be able to start replication from the new master when it gets back online:
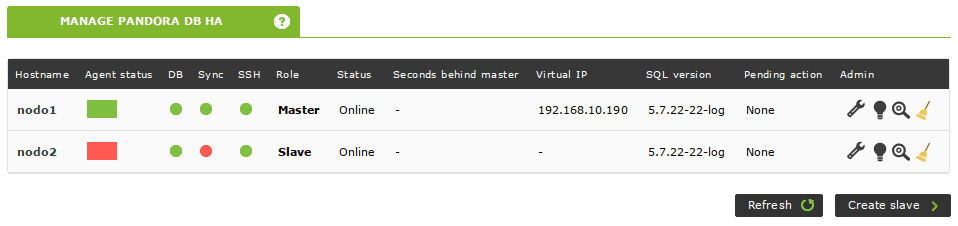
Some of the changes that were not replicated by the former slave may conflict with new changes that need to be replicated now:
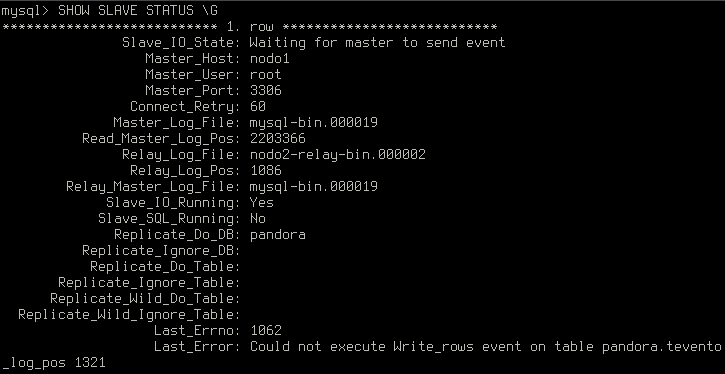
The easiest way to fix a broken node is to follow the instructions in the fixing a broken node section of the Pandora FMS High Availability Database Cluster installation guide, which implies reconstructing the node’s database from the master and starting replication again.
Adding additional nodes
Although not covered in this article, additional nodes can be added to the cluster for increased resilience. See the Pandora FMS High Availability Database Cluster installation guide for more information.
Conclusion
When using a Pandora FMS High-Availability Database Cluster, failures on slave nodes are not even noticed by the Pandora FMS Server. However, they should be acted upon quickly before other nodes fail.
A failure in the master node will cause a small interruption until one of the slaves is promoted to master, after which normal operation will automatically resume.
Your monitoring infrastructure will never be down again because of a database failure!
You can watch the tutorial on HA Database Cluster with Pandora FMS here:








